Abstract: This article originates from the production practices of StreamPark at Dustess Information, written by the senior data development engineer, Gump. The main content includes:
- Technology selection
- Practical implementation
- Business support & capability opening
- Future planning
- Closing remarks
Dustess Information is a one-stop private domain operation management solution provider based on the WeChat Work ecosystem. It is committed to becoming the leading expert in private domain operation and management across all industries, helping enterprises build a new model of private domain operation management in the digital age, and promoting high-quality development for businesses.
Currently, Dustess has established 13 city centers nationwide, covering five major regions: North China, Central China, East China, South China, and Southwest China, providing digital marketing services to over 10,000 enterprises across more than 30 industries.
01 Technology Selection
Dustess Information entered a rapid development phase in 2021. With the increase in service industries and corporate clients, the demand for real-time solutions became more pressing, necessitating the immediate implementation of a real-time computing platform.
As the company is in a phase of rapid growth, with urgent and rapidly changing needs, the team's technology selection followed these principles:
- Speed: Due to urgent business needs, we required a quick implementation of the planned technology selection into production.
- Stability: On the basis of speed, the chosen technology must provide stable service for the business.
- Innovation: On the basis of the above, the selected technology should also be as modern as possible.
- Comprehensiveness: The selected technology should meet the company's rapidly developing and changing business needs, be in line with the team's long-term development goals, and support quick and efficient secondary development.
Firstly, in terms of the computing engine: We chose Flink for the following reasons:
- Team members have an in-depth understanding of Flink and are well-versed in its source code.
- Flink supports both batch and stream processing. Although the company's current batch processing architecture is based on Hive, Spark, etc., using Flink for stream computing facilitates the subsequent construction of unified batch and stream processing and lake-house architecture.
- The domestic ecosystem of Flink has become increasingly mature, and Flink is starting to break boundaries towards the development of stream-based data warehousing.
At the platform level, we comprehensively compared StreamPark, Apache Zeppelin, and flink-streaming-platform-web, also thoroughly read their source code and conducted an analysis of their advantages and disadvantages. We won’t elaborate on the latter two projects in this article, but those interested can search for them on GitHub. We ultimately chose StreamPark for the following reasons:
High Completion
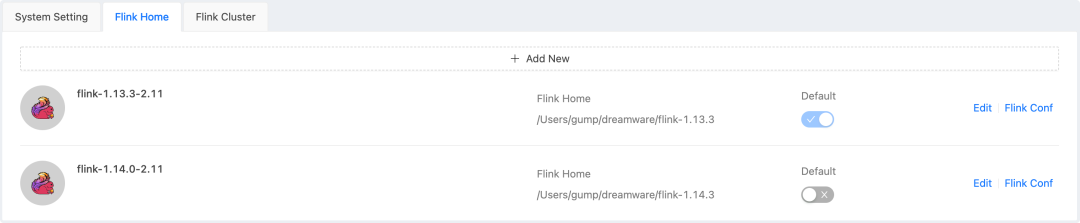
1. Supports Multiple Flink Versions
//Video link (Flink Multi-Version Support Demo)
When creating a task, you can freely choose the Flink version. The Flink binary package will be automatically uploaded to HDFS (if using Yarn for submission), and only one copy of a version's binary package will be saved on HDFS. When the task is initiated, the Flink binary package in HDFS will be automatically loaded according to the context, which is very elegant. This can meet the needs for coexistence of multiple versions and for testing new versions of Flink during upgrades.
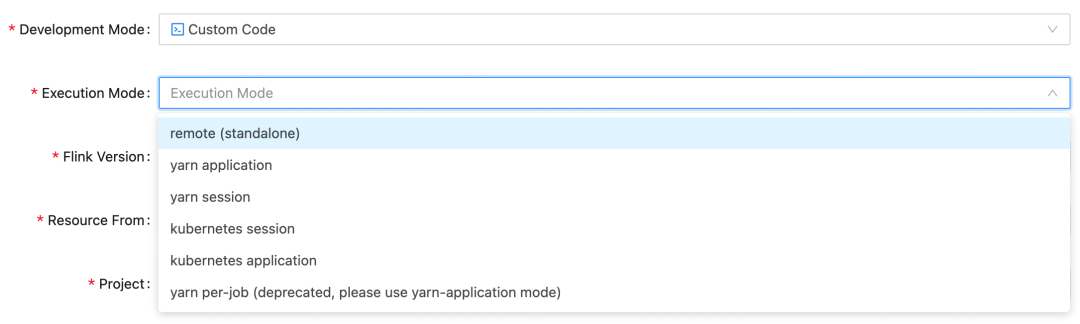
2. Supports Multiple Deployment Modes
StreamPark supports all the mainstream submission modes for Flink, such as standalone, yarn-session, yarn application, yarn-perjob, kubernetes-session, kubernetes-application. Moreover, StreamPark does not simply piece together Flink run commands to submit tasks. Instead, it introduces the Flink Client source package and directly calls the Flink Client API for task submission. The advantages of this approach include modular code, readability, ease of extension, stability, and the ability to quickly adapt to upgrades of the Flink version.
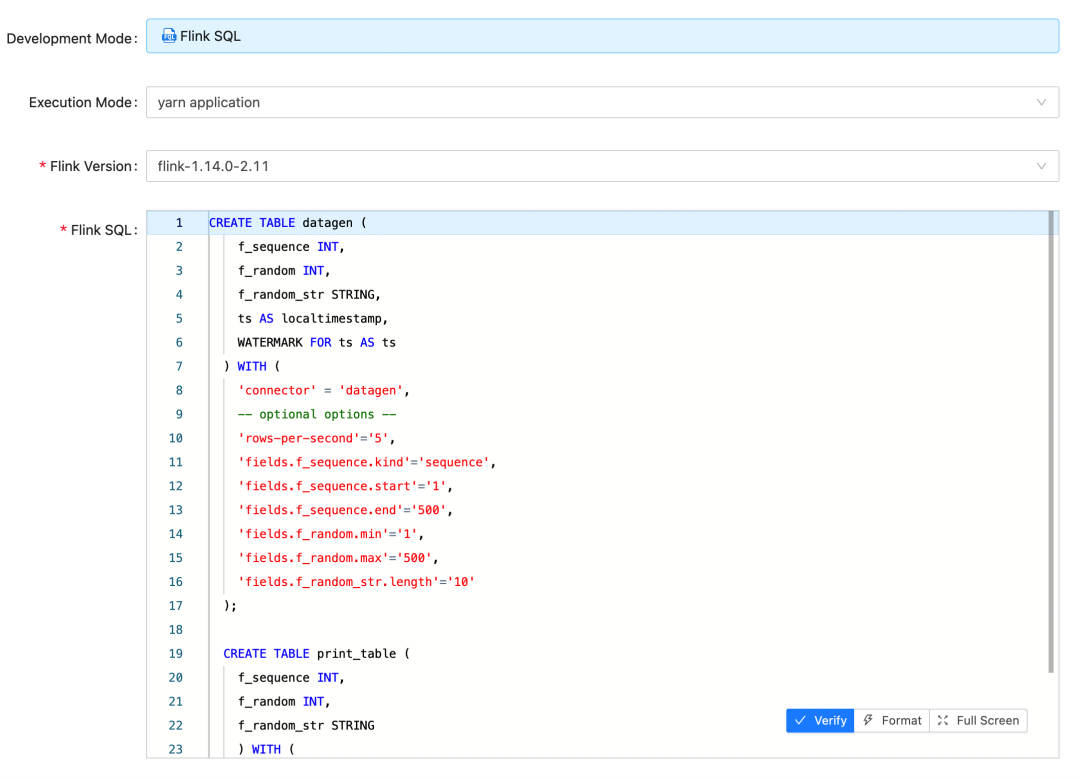
Flink SQL can greatly improve development efficiency and the popularity of Flink. StreamPark’s support for Flink SQL is very comprehensive, with an excellent SQL editor, dependency management, multi-version task management, etc. The StreamPark official website states that it will introduce metadata management integration for Flink SQL in the future. Stay tuned.
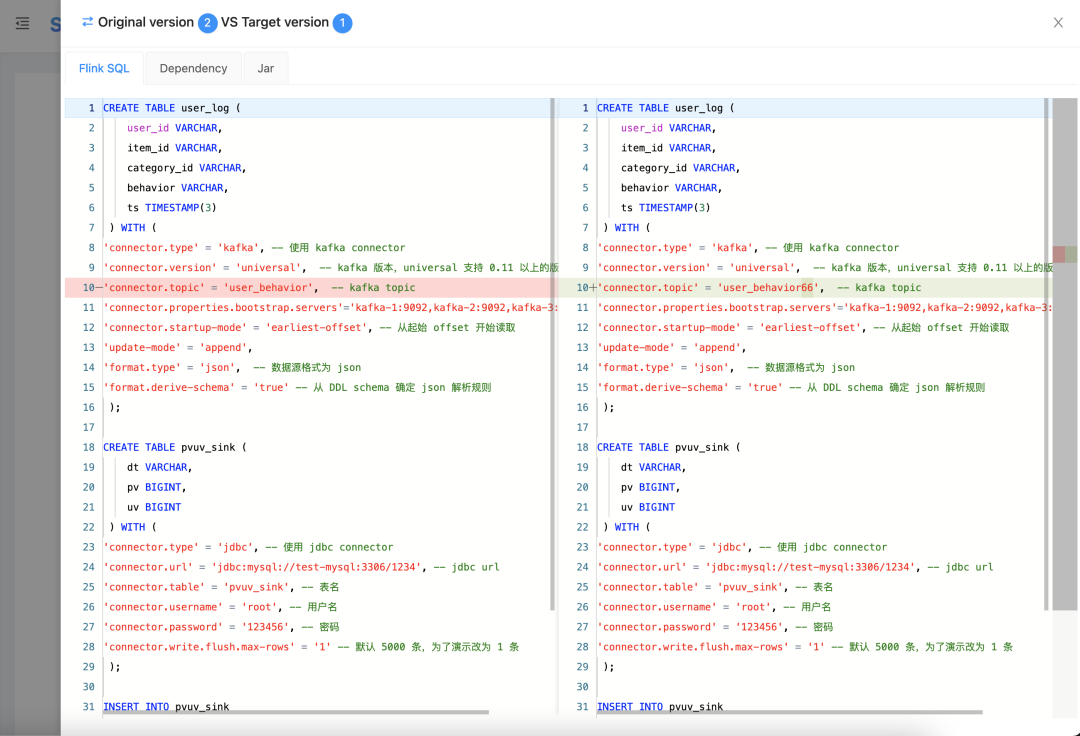
4. Online Building of JAVA Tasks
//Video link (JAVA Task Building Demo)
Although Flink SQL is now powerful enough, using JVM languages like Java and Scala to develop Flink tasks can be more flexible, more customizable, and better for tuning and improving resource utilization. The biggest problem with submitting tasks via Jar packages, compared to SQL, is the management of the Jar uploads. Without excellent tooling products, this can significantly reduce development efficiency and increase maintenance costs.
Besides supporting Jar uploads, StreamPark also provides an online update build feature, which elegantly solves the above problems:
-
Create Project: Fill in the GitHub/Gitlab (supports enterprise private servers) address and username/password, and StreamPark can Pull and Build the project.
-
When creating a StreamPark Custom-Code task, refer to the Project, specify the main class, and optionally automate Pull, Build, and bind the generated Jar when starting the task, which is very elegant!
At the same time, the StreamPark community is also perfecting the entire task compilation and launch process. The future StreamPark will be even more refined and professional on this foundation.
5. Comprehensive Task Parameter Configuration
For data development using Flink, the parameters submitted with Flink run are almost impossible to maintain. StreamPark has also elegantly solved this kind of problem, mainly because, as mentioned above, StreamPark directly calls the Flink Client API and has connected the entire process through the StreamPark product frontend.
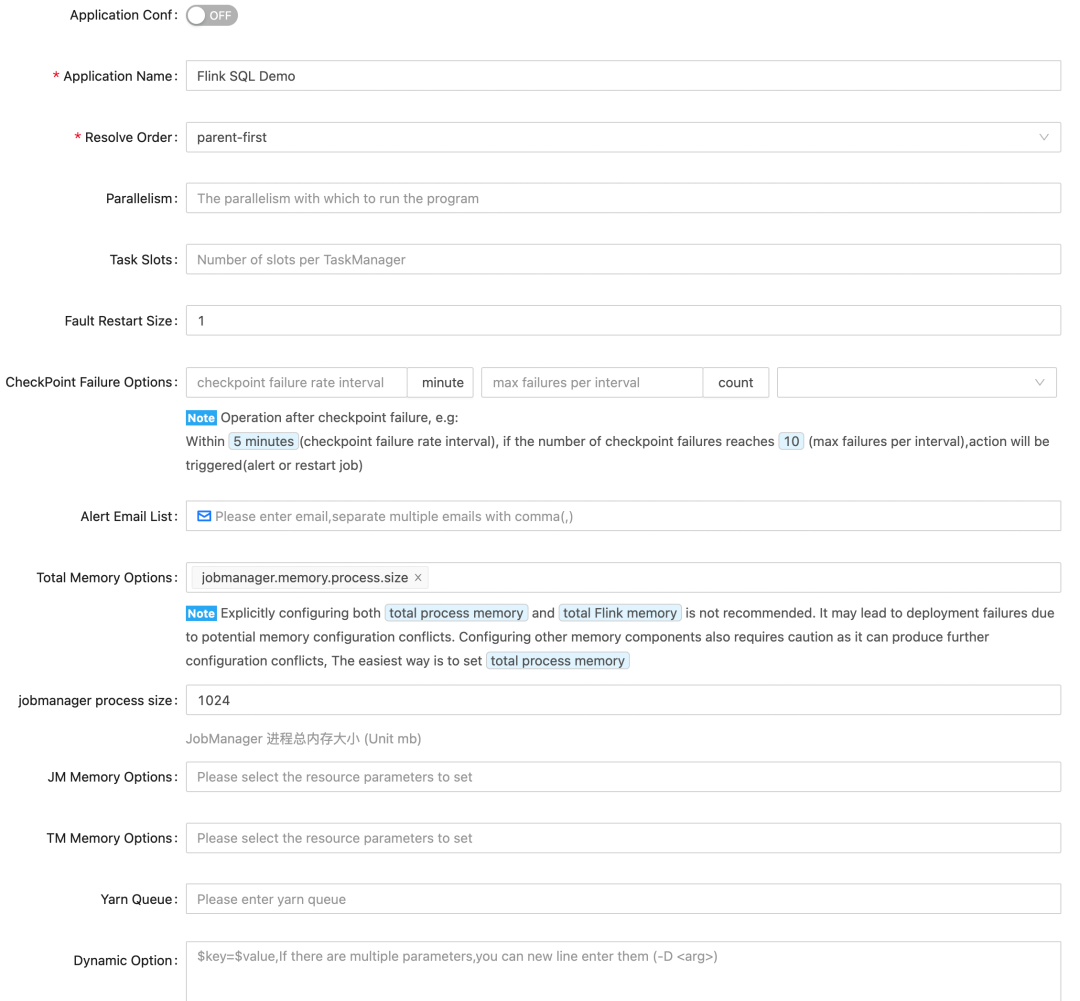
As you can see, StreamPark's task parameter settings cover all the mainstream parameters, and every parameter has been thoughtfully provided with an introduction and an optimal recommendation based on best practices. This is also very beneficial for newcomers to Flink, helping them to avoid common pitfalls!
6. Excellent Configuration File Design
In addition to the native parameters for Flink tasks, which are covered by the task parameters above, StreamPark also provides a powerful Yaml configuration file mode and programming model.
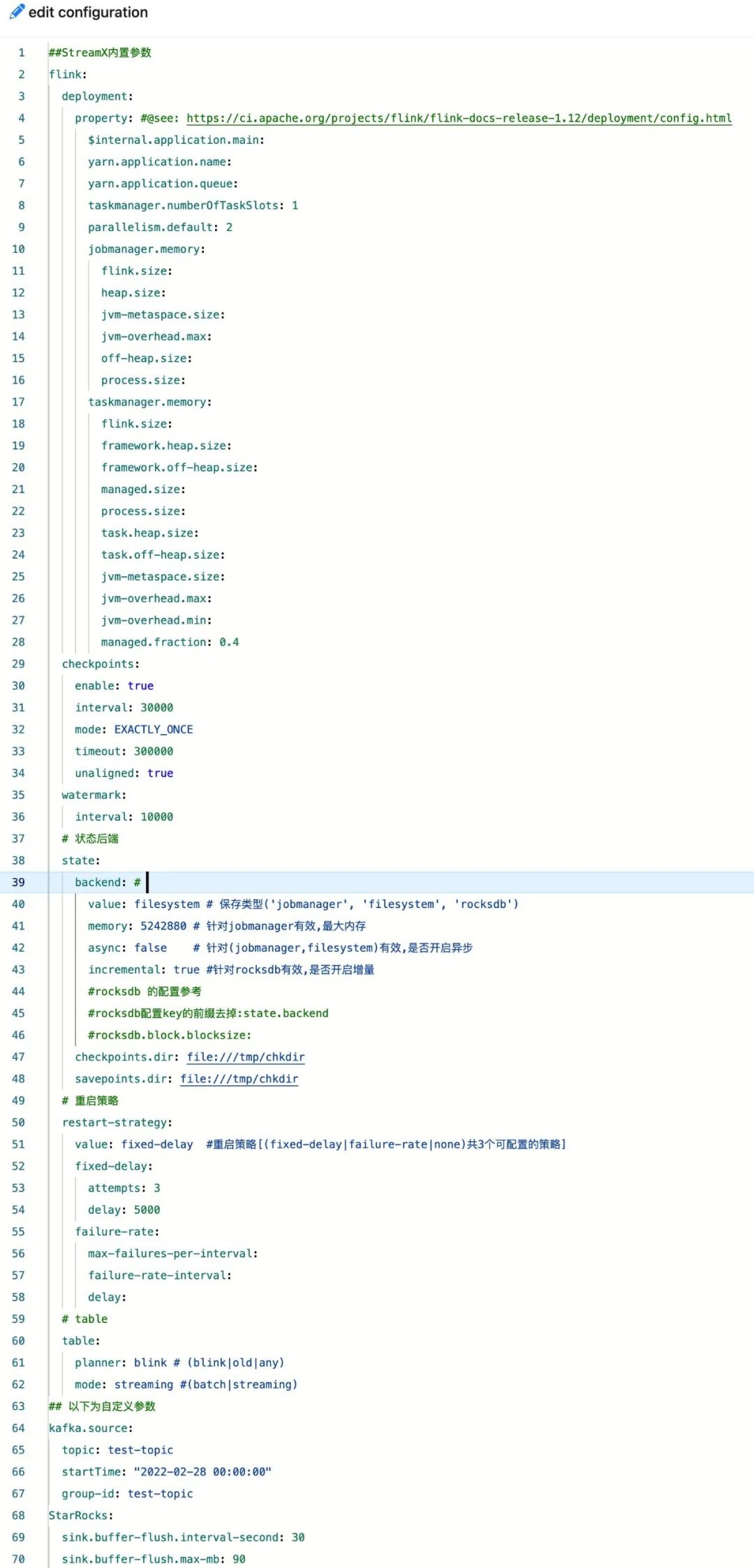
-
For Flink SQL tasks, you can configure the parameters that StreamPark has already built-in, such as CheckPoint, retry mechanism, State Backend, table planner, mode, etc., directly using the task's Yaml configuration file.
-
For Jar tasks, StreamPark offers a generic programming model that encapsulates the native Flink API. Combined with the wrapper package provided by StreamPark, it can very elegantly retrieve custom parameters from the configuration file. For more details, see the documentation:
Programming model:
https://streampark.apache.org/docs/development/dev-model
Built-in Configuration File Parameters:
https://streampark.apache.org/docs/development/config
In addition:
StreamPark also supports Apache Flink® native tasks. The parameter configuration can be statically maintained within the Java task internal code, covering a wide range of scenarios, such as seamless migration of existing Flink tasks, etc.
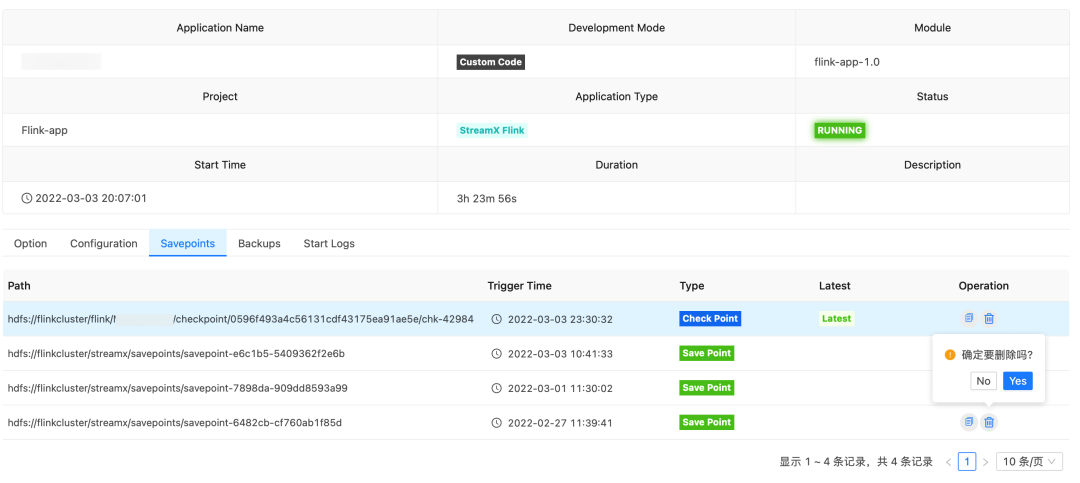
7. Checkpoint Management
Regarding Flink's Checkpoint (Savepoint) mechanism, the greatest difficulty is maintenance. StreamPark has also elegantly solved this problem:
- StreamPark will automatically maintain the task Checkpoint directory and versions in the system for easy retrieval.
- When users need to update and restart an application, they can choose whether to save a Savepoint.
- When restarting a task, it is possible to choose to recover from a specified version of Checkpoint/Savepoint.
As shown below, developers can very intuitively and conveniently upgrade or deal with exceptional tasks, which is very powerful.
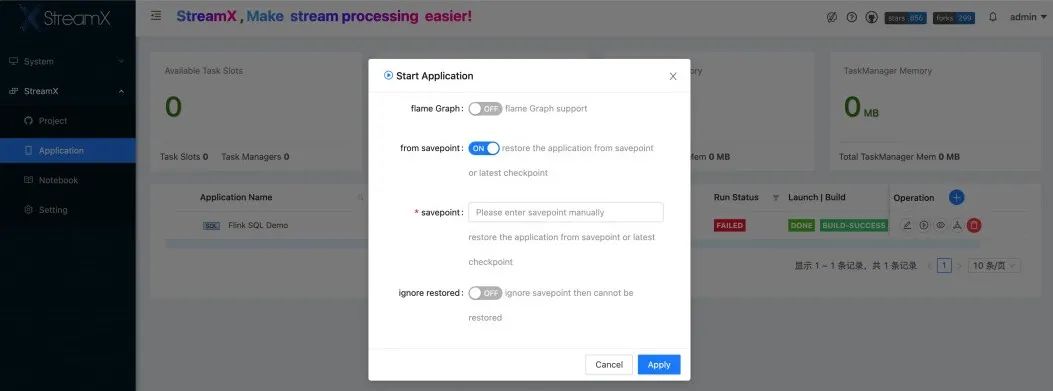
8. Comprehensive Alerting Features
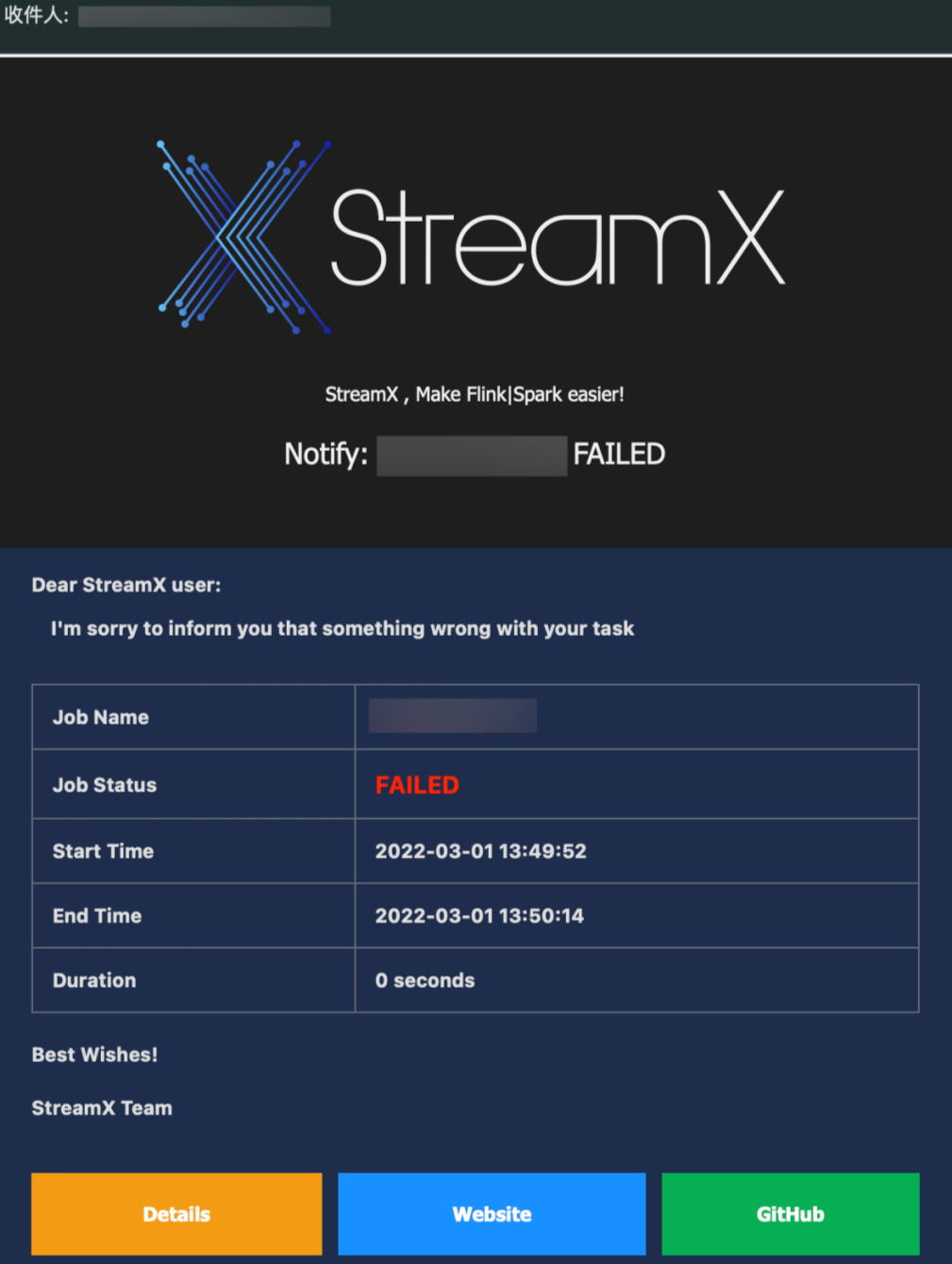
For streaming computations, which are 7*24H resident tasks, monitoring and alerting are very important. StreamPark also has a comprehensive solution for these issues:
- It comes with an email-based alerting method, which has zero development cost and can be used once configured.
- Thanks to the excellent modularity of the StreamPark source code, it's possible to enhance the code at the Task Track point and introduce the company's internal SDK for telephone, group, and other alerting methods, all with a very low development cost.
Excellent Source Code
Following the principle of technology selection, a new technology must be sufficiently understood in terms of underlying principles and architectural ideas before it is considered for production use. Before choosing StreamPark, its architecture and source code were subjected to in-depth study and reading. It was found that the underlying technologies used by StreamPark are very familiar to Chinese developers: MySQL, Spring Boot, Mybatis Plus, Vue, etc. The code style is unified and elegantly implemented with complete annotations. The modules are independently abstracted and reasonable, employing numerous design patterns, and the code quality is very high, making it highly suitable for troubleshooting and further development in the later stages.
In November 2021, StreamPark was successfully selected by Open Source China as a GVP - Gitee "Most Valuable Open Source Project," which speaks volumes about its quality and potential.

03 Active Community
The community is currently very active. Since the end of November 2021, when StreamPark (based on 1.2.0-release) was implemented, StreamPark had just started to be recognized by everyone, and there were some minor bugs in the user experience (not affecting core functionality). At that time, in order to go live quickly, some features were disabled and some minor bugs were fixed. Just as we were preparing to contribute back to the community, we found that these had already been fixed, indicating that the community's iteration cycle is very fast. In the future, our company's team will also strive to stay in sync with the community, quickly implement new features, and improve data development efficiency while reducing maintenance costs.
02 Implementation Practice
StreamPark's environment setup is very straightforward, following the official website's building tutorial you can complete the setup within a few hours. It now supports a front-end and back-end separation packaging deployment model, which can meet the needs of more companies, and there has already been a Docker Build related PR, suggesting that StreamPark's compilation and deployment will become even more convenient and quick in the future. Related documentation is as follows:
https://streampark.apache.org/docs/user-guide/deployment
For rapid implementation and production use, we chose the reliable On Yarn resource management mode (even though StreamPark already supports K8S quite well), and there are already many companies that have deployed using StreamPark on K8S, which you can refer to:
https://streampark.apache.org/blog/flink-development-framework-streampark
Integrating StreamPark with the Hadoop ecosystem can be said to be zero-cost (provided that Flink is integrated with the Hadoop ecosystem according to the Flink official website, and tasks can be launched via Flink scripts).
Currently, we are also conducting K8S testing and solution design, and will be migrating to K8S in the future.
01 Implementing FlinkSQL Tasks
At present, our company's tasks based on Flink SQL are mainly for simple real-time ETL and computing scenarios, with about 10 tasks, all of which have been very stable since they went live.

StreamPark has thoughtfully prepared a demo SQL task that can be run directly on a newly set up platform. This attention to detail demonstrates the community's commitment to user experience. Initially, our simple tasks were written and executed using Flink SQL, and StreamPark's support for Flink SQL is excellent, with a superior SQL editor and innovative POM and Jar package dependency management that can meet many SQL scenario needs.
Currently, we are researching and designing solutions related to metadata, permissions, UDFs, etc.
02 Implementing Jar Tasks
Since most of the data development team members have a background in Java and Scala, we've implemented Jar-based builds for more flexible development, transparent tuning of Flink tasks, and to cover more scenarios. Our implementation was in two phases:
First Phase: StreamPark provides support for native Apache Flink® projects. We configured our existing tasks' Git addresses in StreamPark, used Maven to package them as Jar files, and created StreamPark Apache Flink® tasks for seamless migration. In this process, StreamPark was merely used as a platform tool for task submission and state maintenance, without leveraging the other features mentioned above.
Second Phase: After migrating tasks to StreamPark in the first phase and having them run on the platform, the tasks' configurations, such as checkpoint, fault tolerance, and adjustments to business parameters within Flink tasks, required source code modifications, pushes, and builds. This was very inefficient and opaque.
Therefore, following StreamPark's QuickStart, we quickly integrated StreamPark's programming model, which is an encapsulation for StreamPark Flink tasks (for Apache Flink).
Example:
StreamingContext = ParameterTool + StreamExecutionEnvironment
- StreamingContext is the encapsulation object for StreamPark
- ParameterTool is the parameter object after parsing the configuration file
String value = ParameterTool.get("${user.custom.key}")
- StreamExecutionEnvironment is the native task context for Apache Flink
03 Business Support & Capability Opening
Currently, Dustess Info's real-time computing platform based on StreamPark has been online since the end of November last year and has launched 50+ Flink tasks, including 10+ Flink SQL tasks and 40+ Jar tasks. At present, it is mainly used internally by the data team, and the real-time computing platform will be opened up for use by business teams across the company shortly, which will significantly increase the number of tasks.
01 Real-Time Data Warehouse
The real-time data warehouse mainly uses Jar tasks because the model is more generic. Using Jar tasks can generically handle a large number of data table synchronization and calculations, and even achieve configuration-based synchronization. Our real-time data warehouse mainly uses Apache Doris for storage, with Flink handling the cleaning and calculations (the goal being storage-computation separation).
Using StreamPark to integrate other components is also very straightforward, and we have also abstracted the configuration related to Apache Doris and Kafka into the configuration file, which greatly enhances our development efficiency and flexibility.
02 Capability Opening
Other business teams outside the data team also have many stream processing scenarios. Hence, after secondary development of the real-time computing platform based on StreamPark, we opened up the following capabilities to all business teams in the company:
- Business capability opening: The upstream real-time data warehouse collects all business tables through log collection and writes them into Kafka. Business teams can base their business-related development on Kafka, or they can perform OLAP analysis through the real-time data warehouse (Apache Doris).
- Computing capability opening: The server resources of the big data platform are made available for use by business teams.
- Solution opening: The mature Connectors of the Flink ecosystem and support for Exactly Once semantics can reduce the development and maintenance costs related to stream processing for business teams.
Currently, StreamPark does not support multi-business group functions. The multi-business group function will be abstracted and contributed to the community.
04 Future Planning
01 Flink on K8S
Currently, all our company's Flink tasks run on Yarn, which meets current needs, but Flink on Kubernetes has the following advantages:
- Unified Operations. The company has unified operations with a dedicated department managing K8S.
- CPU Isolation. There is CPU isolation between K8S Pods, so real-time tasks do not affect each other, leading to more stability.
- Separation of Storage and Computation. Flink's computational resources and state storage are separated; computational resources can be mixed with other component resources, improving machine utilization.
- Elastic Scaling. It is capable of elastic scaling, better saving manpower and material costs.
I am also currently organizing and implementing related technical architectures and solutions and have completed the technical verification of Flink on Kubernetes using StreamPark in an experimental environment. With the support of the StreamPark platform and the enthusiastic help of the community, I believe that production implementation is not far off.
02 Stream-Batch Unification Construction
Personally, I think the biggest difference between batch and stream processing lies in the scheduling strategy of operator tasks and the data transfer strategy between operators:
- Batch processing: Upstream and downstream operator tasks have sequential scheduling (upstream tasks end and release resources), and data has a Shuffle strategy (landing on disk). The downside is lower timeliness and no intermediate state in computation, but the upside is high throughput, suitable for offline computation of super-large data volumes.
- Stream processing: Upstream and downstream operator tasks start at the same time (occupying resources simultaneously), and data is streamed between nodes through the network. The downside is insufficient throughput, but the advantage is high timeliness and intermediate state in computation, suitable for real-time and incremental computation scenarios.
As mentioned above, I believe that choosing batch or stream processing is a tuning method for data development according to different data volumes and business scenarios. However, currently, because the computing engine and platform distinguish offline and real-time, it causes development and maintenance fragmentation, with prohibitively high costs. To achieve stream-batch unification, the following aspects must be realized:
- Unified storage (unification of metadata): Supports batch and stream writing/reading.
- Unified computing engine: Able to use a set of APIs or SQL to develop offline and real-time tasks.
- Unified data platform: Able to support the persistent real-time tasks, as well as offline scheduling strategies.
Regarding the unification of stream and batch, I am also currently researching and organizing, and I welcome interested friends to discuss and study the project together.
05 Closing Words
That's all for the sharing of StreamPark in the production practice at Dustess Info. Thank you all for reading this far. The original intention of writing this article was to bring a bit of StreamPark's production practice experience and reference to everyone, and together with the buddies in the StreamPark community, to jointly build StreamPark. In the future, I plan to participate and contribute more. A big thank you to the developers of StreamPark for providing such an excellent product; in many details, we can feel everyone's dedication. Although the current production version used by the company (1.2.0-release) still has some room for improvement in task group search, edit return jump page, and other interactive experiences, the merits outweigh the minor issues. I believe that StreamPark will get better and better, and I also believe that StreamPark will promote the popularity of Apache Flink. Finally, let's end with a phrase from the Apache Flink® community: The future is real-time!
