
Introduction: Ziroom, an O2O internet company focusing on providing rental housing products and services, has built an online, data-driven, and intelligent platform that covers the entire chain of urban living. Real-time computing has always played an important role in Ziroom. To date, Ziroom processes TB-level data daily. This article, brought by the real-time computing team from Ziroom, introduces the in-depth practice of Ziroom's real-time computing platform based on StreamPark.
- Challenges in real-time computing
- The journey to the solution
- In-depth practice based on StreamPark
- Summary of practical experience and examples
- Benefits brought by the implementation
- Future plans
As an O2O internet brand offering rental housing products and services, Ziroom was established in October 2011. To date, Ziroom has served nearly 500,000 landlords and 5 million customers, managing over 1 million housing units. As of March 2021, Ziroom has expanded to 10 major cities including Beijing, Shanghai, Shenzhen, Hangzhou, Nanjing, Guangzhou, Chengdu, Tianjin, Wuhan, and Suzhou. Ziroom has created an online, data-driven, and intelligent platform for quality residential products for both To C and To B markets, covering the entire chain of urban living. The Ziroom app has accumulated 140 million downloads, with an average of 400 million online service calls per day, and owns tens of thousands of smart housing units. Ziroom has now established an O2O closed loop for renting, services, and community on PC, app, and WeChat platforms, eliminating all redundant steps in the traditional renting model, restructuring the residential market through the O2O model, and building China's largest O2O youth living community.
With a vast user base, Ziroom has been committed to providing superior product experiences and achieving digital transformation of the enterprise. Since 2021, real-time computing, particularly Flink, has played an important role in Ziroom. To date, Ziroom processes TB-level data daily, with over 500 real-time jobs supporting more than 10 million data calls per day.
Challenges in Real-Time Computing
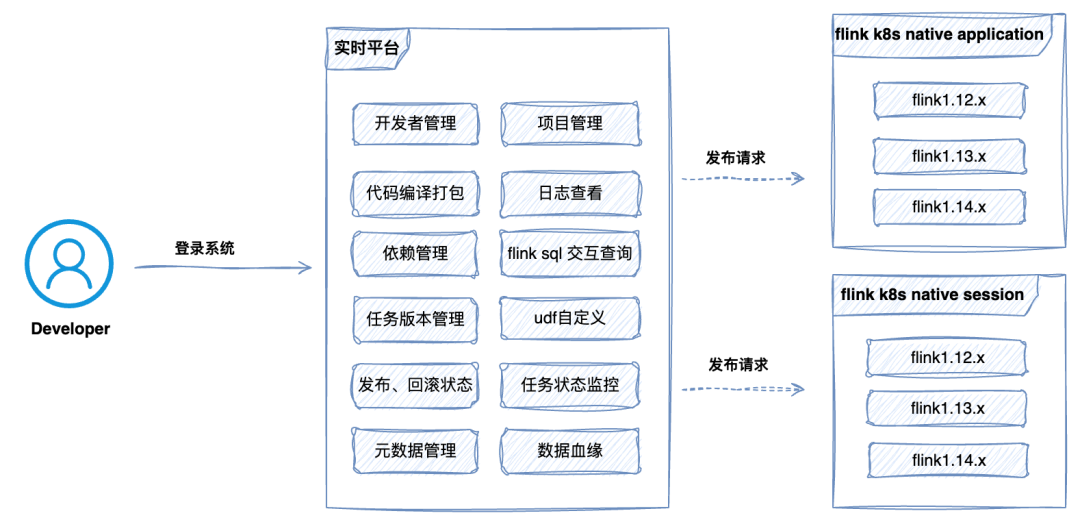
At Ziroom, real-time computing is mainly divided into two application scenarios:
-
Data synchronization: Includes Kafka, MySQL, and MongoDB data synchronization to Hive / Paimon / ClickHouse, etc.
-
Real-time data warehouse: Includes real-time indicators for businesses like rentals, acquisitions, and home services.
In the process of implementing real-time computing, we faced several challenges, roughly as follows:
01 Low Efficiency in Job Deployment
The process of developing and deploying real-time jobs at Ziroom is as follows: data warehouse developers embed Flink SQL code in the program, debug locally, compile into FatJar, and then submit the job as a work order and JAR package to the operation team. The operation team member responsible for job deployment then deploys the job to the online Kubernetes session environment through the command line. This process involves many steps, each requiring manual intervention, resulting in extremely low efficiency and being prone to errors, affecting work efficiency and stability. Therefore, there is an urgent need to build an efficient and automated real-time computing platform to meet the growing demands of real-time computing.
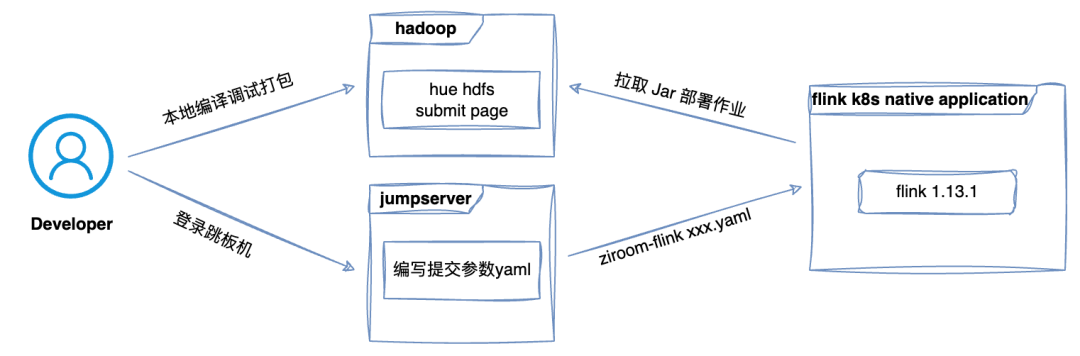
02 Unclear Job Ownership Information
Due to the lack of unified management of the real-time computing platform, business code is managed by GitLab. Although this solved some problems, we found deficiencies between the repository code and the management of online Flink jobs: lack of clear ownership, lack of grouping and effective permission control, leading to chaotic job management and difficult responsibility tracing. To ensure the consistency and controllability of code and online jobs, there is an urgent need to establish a strict and clear job management system, including strict code version control, clear job ownership and responsible persons, and effective permission control.
03 Difficulty in Job Maintenance
At Ziroom, multiple versions of Flink jobs are running. Due to frequent API changes and lack of backward compatibility in major version upgrades of Apache Flink, the cost of upgrading project code becomes very high. Therefore, managing these different versions of jobs has become a headache.
Without a
unified job platform, these jobs are submitted using scripts. Jobs vary in importance and data volume, requiring different resources and runtime parameters, necessitating corresponding modifications. Modifications can be made by editing the submission script or directly setting parameters in the code, but this makes configuration information difficult to access, especially when jobs restart or fail and FlinkUI is unavailable, turning configuration information into a black box. Therefore, there is an urgent need for a more efficient platform that supports configuration of real-time computing jobs.
04 Difficulty in Job Development and Debugging
In our previous development process, we typically embedded SQL code within program code in the local IDEA environment for job development and debugging, verifying the correctness of the program. However, this approach has several disadvantages:
-
Difficulty in multi-data source debugging. Often, a requirement involves multiple different data sources. For local environment debugging, developers need to apply for white-list access to data, which is both time-consuming and cumbersome.
-
SQL code is hard to read and modify. As SQL code is embedded in program code, it's difficult to read and inconvenient to modify. More challenging is debugging through SQL segments, as the lack of SQL version control and syntax verification makes it hard for developers to locate specific SQL lines in client logs to identify the cause of execution failure.
Therefore, there is a need to improve the efficiency of development and debugging.
The Journey to the Solution
In the early stages of platform construction, we comprehensively surveyed almost all relevant projects in the industry, covering both commercial paid versions and open-source versions, starting from early 2022. After investigation and comparison, we found that these projects have their limitations to varying extents, and their usability and stability could not be effectively guaranteed.
Overall, StreamPark performed best in our evaluation. It was the only project without major flaws and with strong extensibility: supporting both SQL and JAR jobs, with the most complete and stable deployment mode for Flink jobs. Its unique architectural design not only avoids locking in specific Flink versions but also supports convenient version switching and parallel processing, effectively solving job dependency isolation and conflict issues. The job management & operations capabilities we focused on were also very complete, including monitoring, alerts, SQL validation, SQL version comparison, CI, etc. StreamPark's support for Flink on K8s was the most comprehensive among all the open-source projects we surveyed. However, StreamPark's K8s mode submission required local image building, leading to storage resource consumption.
In the latest 2.2 version, the community has already restructured this part.
After analyzing the pros and cons of many open-source projects, we decided to participate in projects with excellent architecture, development potential, and an actively dedicated core team. Based on this understanding, we made the following decisions:
-
In terms of job deployment mode, we decided to adopt the On Kubernetes mode. Real-time jobs have dynamic resource consumption, creating a strong need for Kubernetes' elastic scaling, which helps us better cope with data output fluctuations and ensure job stability.
-
In the selection of open-source components, after comprehensive comparison and evaluation of various indicators, we finally chose what was then StreamX. Subsequent close communication with the community allowed us to deeply appreciate the serious and responsible attitude of the founders and the united and friendly atmosphere of the community. We also witnessed the project's inclusion in the Apache Incubator in September 2022, making us hopeful for its future.
-
On the basis of StreamPark, we aim to promote integration with the existing ecosystem of the company to better meet our business needs.
In-depth Practice Based on Apache StreamPark™
Based on the above decisions, we initiated the evolution of the real-time computing platform, oriented by "pain point needs," and built a stable, efficient, and easy-to-maintain real-time computing platform based on StreamPark. Since the beginning of 2022, we have participated in the construction of the community while officially scheduling our internal platform construction.
First, we further improved related functionalities on the basis of StreamPark:
01 LDAP Login Support
On the basis of StreamPark, we further improved related functionalities, including support for LDAP, so that in the future we can fully open up real-time capabilities, allowing analysts from the company's four business lines to use the platform, expected to reach about 170 people. With the increase in numbers, account management becomes increasingly important, especially in the case of personnel changes, account cancellation, and application become frequent and time-consuming operations. Therefore, integrating LDAP becomes particularly important. We communicated with the community in a timely manner and initiated a discussion, eventually contributing this Feature. Now, starting LDAP in StreamPark has become very simple, requiring just two steps:
step1: Fill in the corresponding LDAP
configuration:
Edit the application.yml file, setting the LDAP basic information as follows:
ldap:
# Is ldap enabled?
enable: false
## AD server IP, default port 389
urls: ldap://99.99.99.99:389
## Login Account
base-dn: dc=streampark,dc=com
username: cn=Manager,dc=streampark,dc=com
password: streampark
user:
identity-attribute: uid
email-attribute: mail
step2: LDAP Login
On the login interface, click LDAP login method, then enter the corresponding account and password, and click to log in.
02 Automatic Ingress Generation for Job Submission
Due to the company's network security policy, only port 80 is opened on the Kubernetes host machines by the operation team, making it impossible to directly access the job WebUI on Kubernetes via "domain + random port." To solve this problem, we needed to use Ingress to add a proxy layer to the access path, achieving the effect of access routing. In StreamPark version 2.0, we contributed the functionality related to Ingress [3]. We adopted a strategy pattern implementation, initially obtaining Kubernetes metadata information to identify its version and accordingly constructing respective objects, ensuring smooth use of the Ingress function across various Kubernetes environments.
The specific configuration steps are as follows:
step1: Click to enter Setting-> Choose Ingress Setting, fill in the domain name
step2: Submit a job
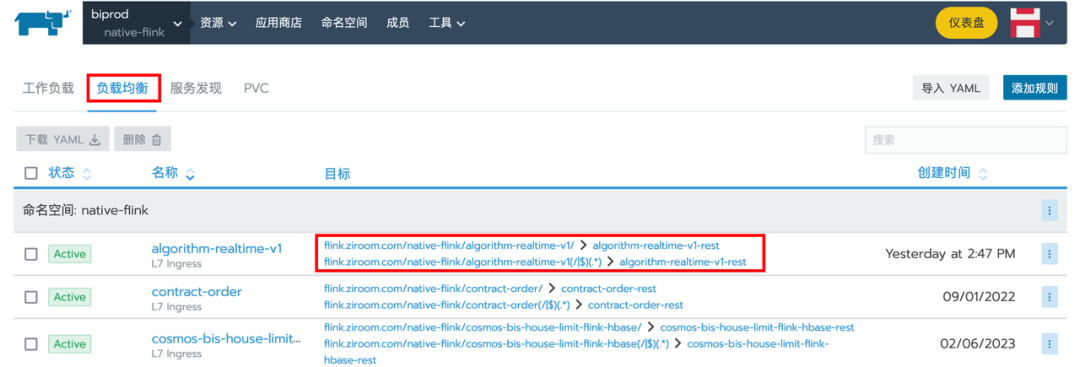
Upon entering the K8s management platform, you can observe that submitting a Flink job also corresponds to submitting an Ingress with the same name.
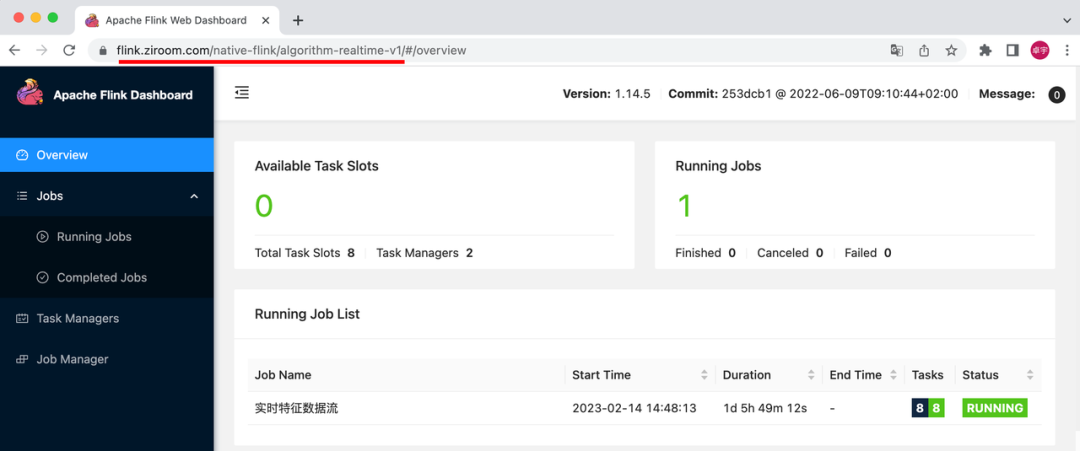
step3: Click to enter Flink's WebUI
You will notice that the generated address consists of three parts: domain + job submission namespace + job name.
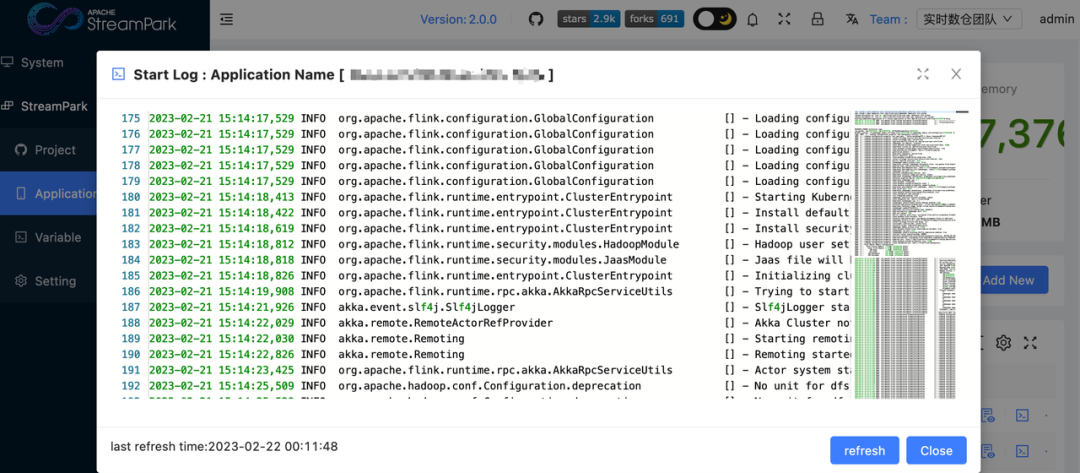
03 Support for Viewing Job Deployment Logs
In the process of continuous job deployment, we gradually realized that without logs, we cannot perform effective operations. Log retention, archiving, and viewing became an important part in our later problem-solving process. Therefore, in StreamPark version 2.0, we contributed the ability to archive startup logs in On Kubernetes mode and view them on the page [4]. Now, by clicking the log viewing button in the job list, it is very convenient to view the real-time logs of the job.
04 Integration of Grafana Monitoring Chart Links
In actual use, as the number of jobs increased, the number of users rose, and more departments were involved, we faced the problem of difficulty in self-troubleshooting. Our team's operational capabilities are actually very limited. Due to the difference in professional fields, when we tell users to view charts and logs on Grafana and ELK, users often feel at a loss and do not know how to find information related to their jobs.
To solve this problem, we proposed a demand in the community: we hoped that each job could directly jump to the corresponding monitoring chart and log archive page through a hyperlink, so that users could directly view the monitoring information and logs related to their jobs. This avoids tedious searches in complex system interfaces, thus improving the efficiency of troubleshooting.
We had a discussion in the community, and it was quickly responded to, as everyone thought it was a common need. Soon, a developer contributed a design and related PR, and the issue was quickly resolved. Now, to enable this feature in StreamPark has become very simple:
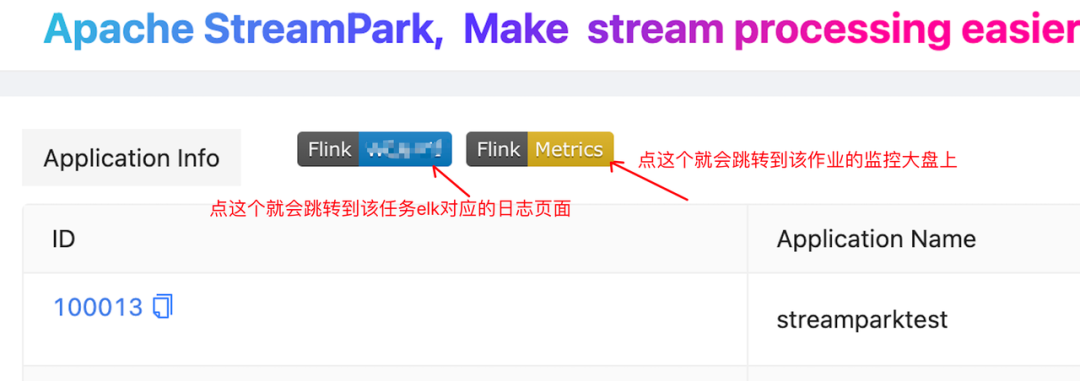
step1: Create a badge label
![]()
step2: Associate the badge label with a redirect link

step3: Click the badge label for link redirection
05 Integration of Flink SQL Security for Permission Control
In our system, lineage management is based on Apache Atlas, and permission management is based on the open-source project Flink-sql-security, which supports user-level data desensitization and row-level data access control, allowing specific users to only access desensitized data or authorized rows.
This design is to handle some complex inheritance logic. For example, when joining encrypted field age in Table A with Table B to obtain Table C, the age field in Table C should inherit the encryption logic of Table A to ensure the encryption status of data is not lost during processing. This way, we can better protect data security and ensure that data complies with security standards throughout the processing process.
For permission control, we developed a Flink-sql-security-streampark plugin based on Flink-s
ql-security. The basic implementation is as follows:
-
During submission check, the system parses the submitted SQL, obtaining InputTable and OutputTable datasets.
-
The system queries the remote permission service to obtain the user's bound RBAC (Role-Based Access Control) permissions.
-
Based on the RBAC permissions, the system gets the encryption rules for the corresponding tables.
-
The system rewrites the SQL, wrapping the original SQL query fields with a preset encryption algorithm, thereby reorganizing the logic.
-
Finally, the system submits according to the reorganized logic.
Through this integration and plugin development, we implemented permission control for user query requests, thereby ensuring data security.
01 Row-level Permission Conditions
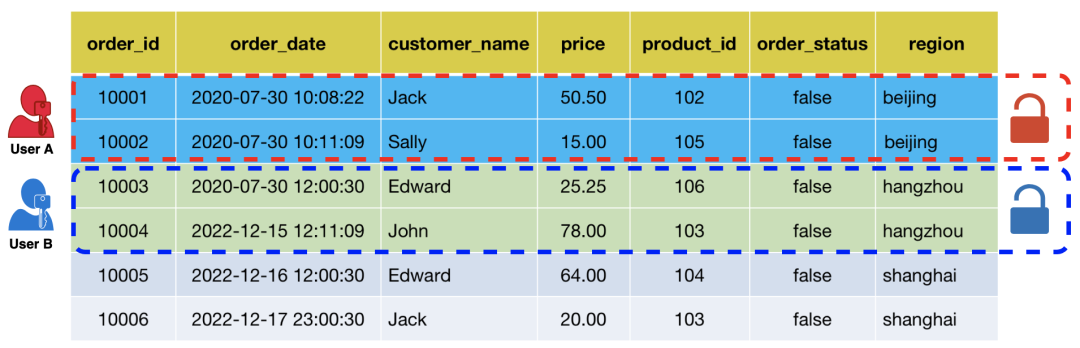

Input SQL
SELECT * FROM orders;
User A's actual execution SQL:
SELECT * FROM orders WHERE region = 'beijing';
User B's actual execution SQL:
SELECT * FROM orders WHERE region = 'hangzhou';
02 Field Desensitization Conditions
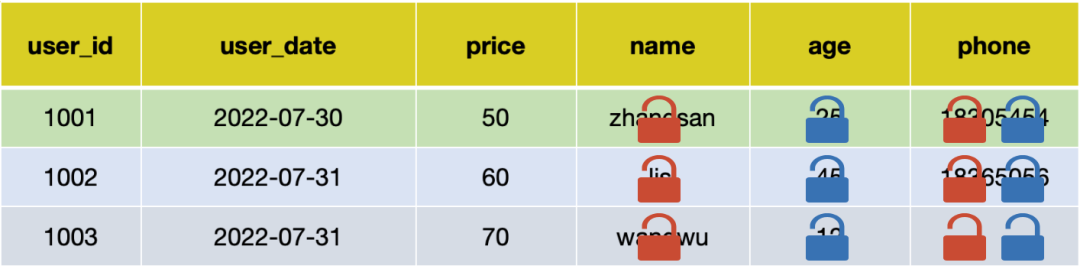

Input SQL
SELECT name, age, price, phone FROM user;
Execution SQL:
User A's actual execution SQL:
SELECT Encryption_function(name), age, price, Sensitive_field_functions(phone) FROM user;
User B's actual execution SQL:
SELECT name, Encryption_function(age), price, Sensitive_field_functions(phone) FROM user;
06 Data Synchronization Platform Based on Apache StreamPark™
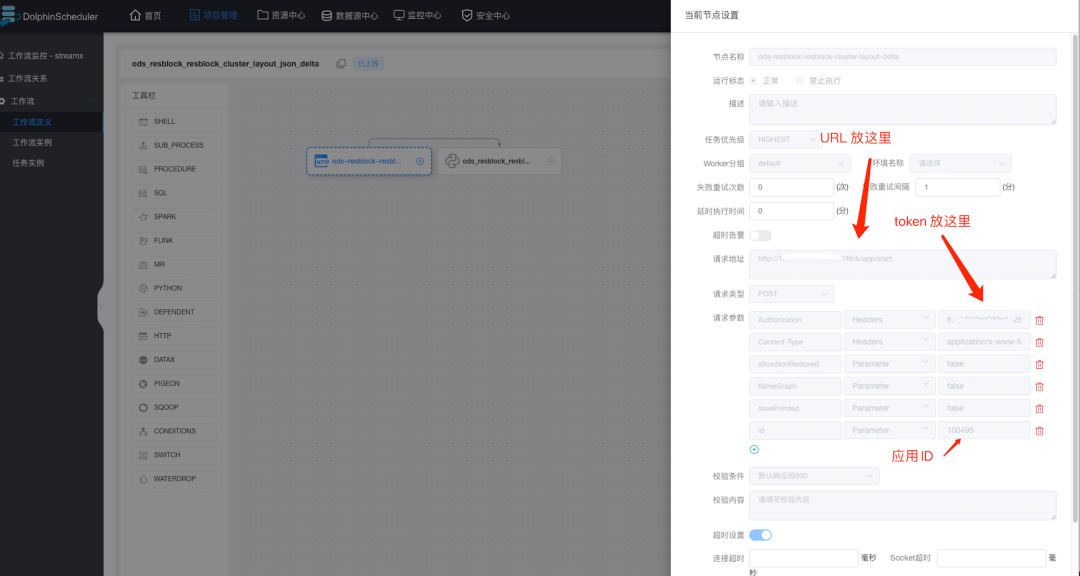
With the successful implementation of StreamPark's technical solutions in the company, we achieved deep support for Flink jobs, bringing a qualitative leap in data processing. This prompted us to completely revamp our past data synchronization logic, aiming to reduce operational costs through technical optimization and integration. Therefore, we gradually replaced historical Sqoop jobs, Canal jobs, and Hive JDBC Handler jobs with Flink CDC jobs, Flink stream, and batch jobs. In this process, we continued to optimize and strengthen StreamPark's interface capabilities, adding a status callback mechanism and achieving perfect integration with the DolphinScheduler [7] scheduling system, further enhancing our data processing capabilities.
External system integration with StreamPark is simple, requiring only a few steps:
- First, create a token for API access:
- View the external call link of the Application:
curl -X POST '/flink/app/start' \
-H 'Authorization: $token' \
-H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \
--data-urlencode 'savePoint=' \
--data-urlencode 'allowNonRestored=false' \
--data-urlencode 'savePointed=false' \
--data-urlencode 'id=100501'
- Configure Http scheduling in DolphinScheduler
Summary of Practical Experience
During our in-depth use of StreamPark, we summarized some common issues and explored solutions in the practice process, which we have compiled into examples for reference.
01 Building Base Images
To deploy a Flink job on Kubernetes using StreamPark, you first need to prepare a Base image built on Flink. Then, on the Kubernetes platform, the user-provided image is used to start the Flink job. If we continue to use the official "bare image," it is far from sufficient for actual development. Business logic developed by users often involves multiple upstream and downstream data sources, requiring related data source Connectors and dependencies like Hadoop. Therefore, these dependencies need to be included in the image. Below, I will introduce the specific operation steps.
step1: First, create a folder containing two folders and a Dockerfile file

conf folder: Contains HDFS configuration files, mainly for configuring Flink's Checkpoint writing and using Hive metadata in FlinkSQL
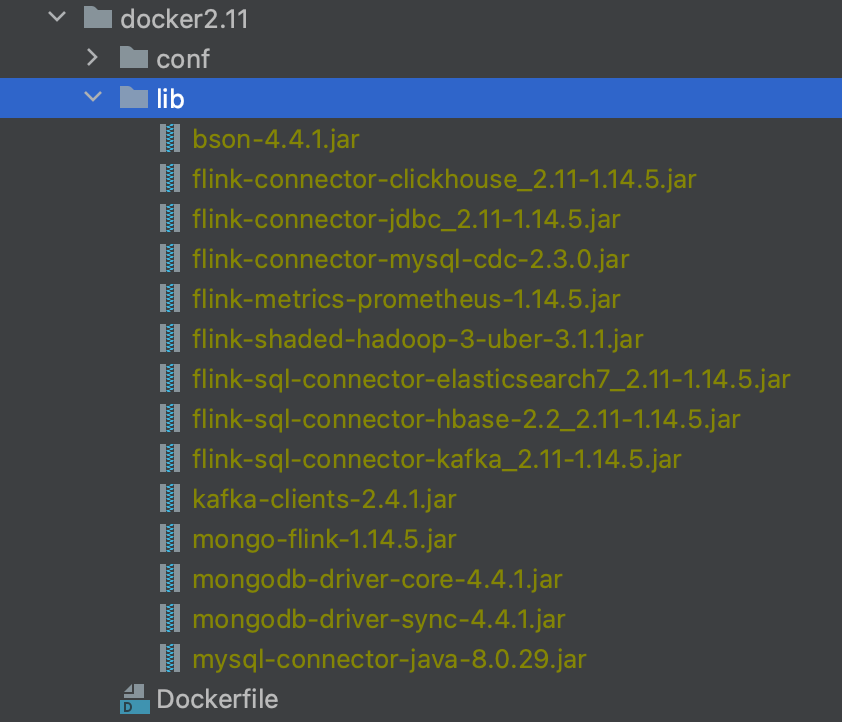
lib folder: Contains the related Jar dependency packages, as follows:
Dockerfile file for defining image construction
FROM apache/flink:1.14.5-scala_2.11-java8
ENV TIME_ZONE=Asia/Shanghai
COPY ./conf /opt/hadoop/conf
COPY lib $FLINK_HOME/lib/
step2: Image build command using multi-architecture build mode, as follows:
docker buildx build --push --platform linux/amd64 -t ${private image repository address}
02 Base Image Integration with Arthas Example
As more jobs are released and go live within our company, we often encounter performance degradation in long-running jobs, such as reduced Kafka consumption capacity, increased memory usage, and extended GC time. We recommend using Arthas, an open-source Java diagnostic tool by Alibaba. It allows real-time global viewing of Java application load, memory, GC, thread status, and without modifying application code, it enables viewing method call parameters, exceptions, monitoring method execution time, class loading information, etc., greatly enhancing our efficiency in troubleshooting online issues.
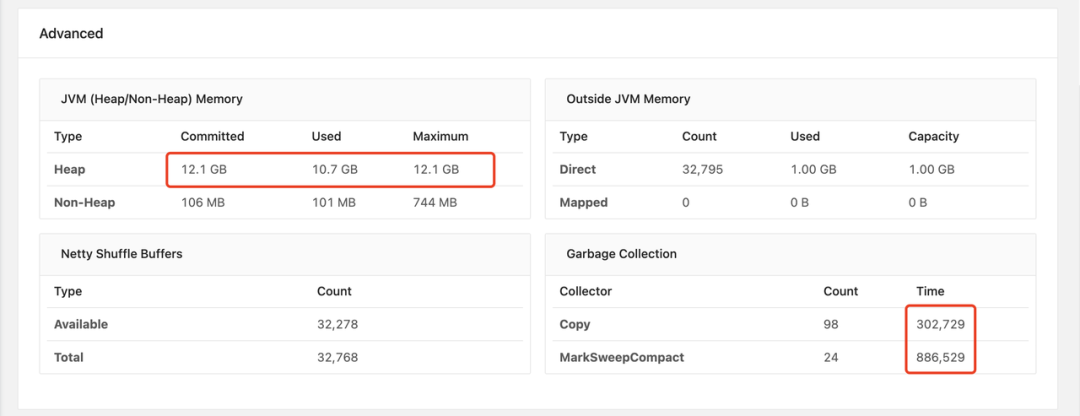
Therefore, we integrated Arthas into the base image to facilitate runtime problem troubleshooting.
FROM apache/flink:1.14.5-scala_2.11-java8
ENV TIME_ZONE=Asia/Shanghai
COPY ./conf /opt/hadoop/conf
COPY lib $FLINK_HOME/lib/
RUN apt-get update --fix-missing && apt-get install -y fontconfig --fix-missing && \
apt-get install -y openjdk-8-jdk && \
apt-get install -y ant && \
apt-get clean;
RUN apt-get install sudo -y
# Fix certificate issues
RUN apt-get update && \
apt-get install ca-certificates-java && \
apt-get clean && \
update-ca-certificates -f;
# Setup JAVA_HOME -- useful for docker commandline
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
RUN export JAVA_HOME
RUN apt-get install -y unzip
RUN curl -Lo arthas-packaging-latest-bin.zip 'https://arthas.aliyun.com/download/latest_version?mirror=aliyun'
RUN unzip -d arthas-latest-bin arthas-packaging-latest-bin.zip
03 Resolution of Dependency Conflicts in Images
In the process of using StreamPark, we often encounter dependency conflict exceptions like NoClassDefFoundError, ClassNotFoundException, and NoSuchMethodError in Flink jobs running on base images. The troubleshooting approach is to find the package path of the conflicting class indicated in the error. For example, if the error class is in org.apache.orc:orc-core, go to the corresponding module directory, run mvn dependency::tree, search for orc-core, see who brought in the dependency, and remove it using exclusion. Below, I will introduce in detail a method of custom packaging to resolve dependency conflicts, illustrated by a dependency conflict caused by the flink-shaded-hadoop-3-uber JAR package in a base image.
step1: Clone the flink-shaded project locally👇
git clone https://github.com/apache/flink-shaded.git
step2: Load the project into IDEA
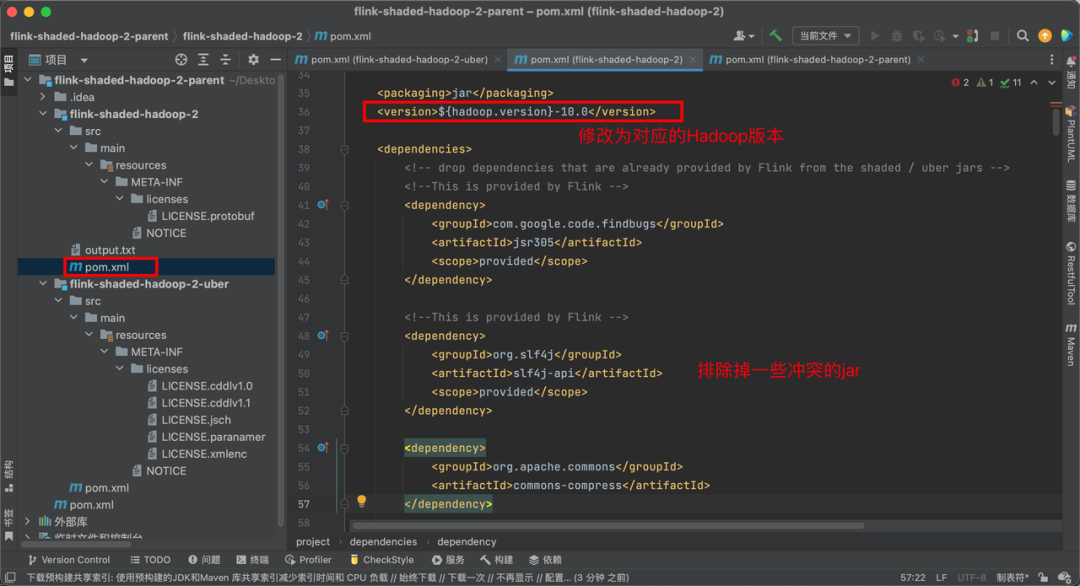
step3: Exclude the conflicting parts and then package them.
04 Centralized Job Configuration Example
One of the great conveniences of using StreamPark is centralized configuration management. You can configure all settings in the conf file in the Flink directory bound to the platform.
cd /flink-1.14.5/conf
vim flink-conf.yaml
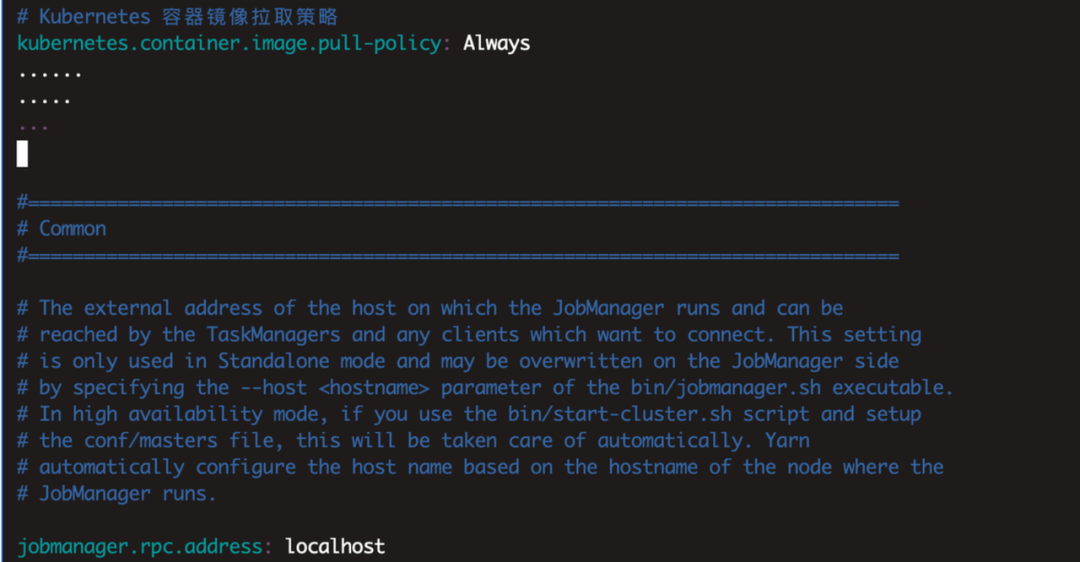
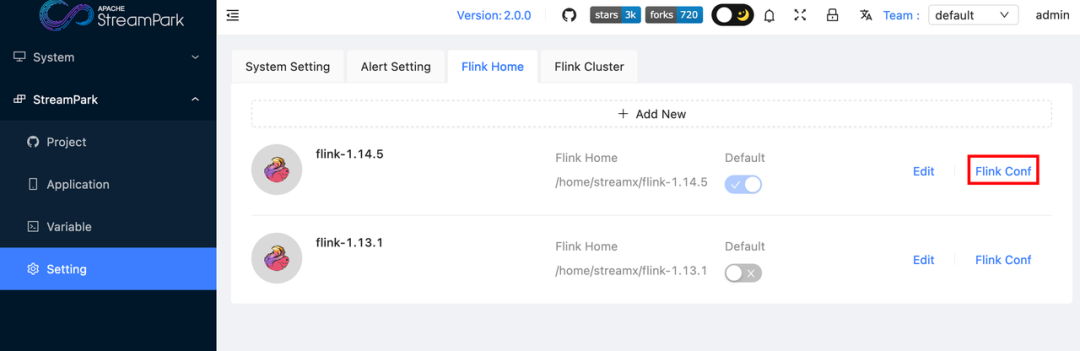
After completing the configuration, save it. Then go to the platform's Setting, and click on the Flink Conf icon.
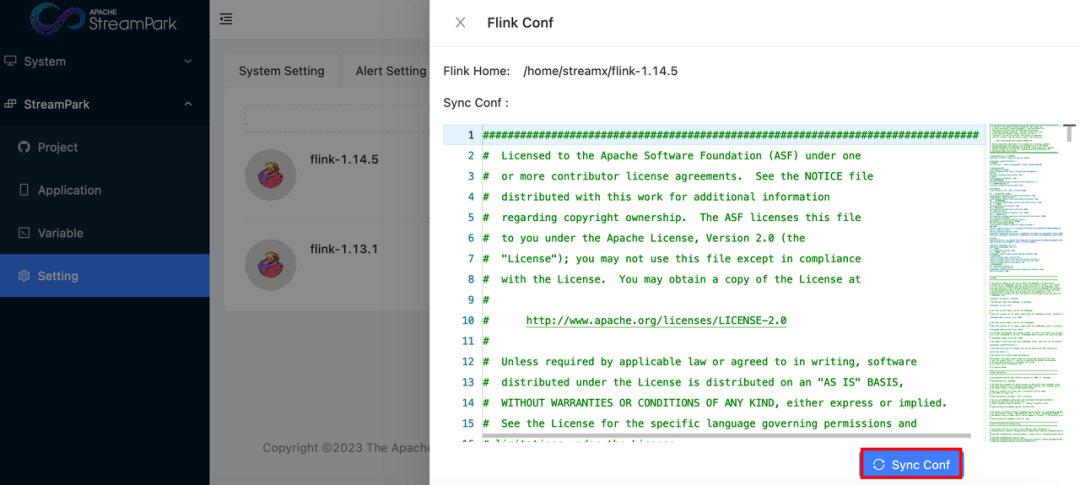
Clicking Sync Conf will synchronize the global configuration file, and new jobs will be submitted with the new configuration.
05 Apache StreamPark™ DNS Resolution Configuration
A correct and reasonable DNS resolution configuration is very important when submitting FlinkSQL on the StreamPark platform. It mainly involves the following points:
-
Flink jobs' Checkpoint writing to HDFS requires a snapshot write to an HDFS node obtained through ResourceManager. If there are expansions in the Hadoop cluster in the enterprise, and these new nodes are not covered by the DNS resolution service, this will directly lead to Checkpoint failure, affecting online stability.
-
Flink jobs typically need to configure connection strings for different internal data sources. Configuring the database's real IP address often leads to job exits due to IP changes during database migration. Therefore, in production, connection strings are often composed of domain names and attribute parameters, with DNS services resolving them to real IP addresses for access.
Initially, we maintained DNS configuration through Pod Template.
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
hostAliases:
- ip: 10.216.xxx.79
hostnames:
- handoop1
- host
names:
- handoop2
ip: 10.16.xx.48
- hostnames:
- handoop3
ip: 10.16.xx.49
- hostnames:
- handoop4
ip: 10.16.xx.50
.......
Although theoretically feasible, we encountered a series of problems in practice. When expanding HDFS, we found failures in Flink's Checkpoint function, and database migration also faced connection failures, causing sudden online service outages. After in-depth investigation, we found that the root cause was in DNS resolution.
Previously, we used hostAliases to maintain the mapping between domain names and IP addresses. However, this method was costly in practice, as every update of hostAliases required stopping all Flink jobs, undoubtedly increasing our operational costs. To seek a more flexible and reliable method to manage DNS resolution configuration and ensure the normal operation of Flink jobs, we decided to build dnsmasq for bidirectional DNS resolution.
After configuring and installing dnsmasq, we first needed to override the resolv.conf configuration file in the /etc directory of the Flink image. However, since resolv.conf is a read-only file, if we want to override it, we need to use mounting. Therefore, we first configured resolv.conf as a ConfigMap for use during the override. This way, we can more flexibly and reliably manage DNS resolution configuration, ensuring stable operation of Flink jobs.
apiVersion: v1
data:
resolv.conf: "nameserver 10.216.138.226" //DNS service
kind: ConfigMap
metadata:
creationTimestamp: "2022-07-13T10:16:18Z"
managedFields:
name: dns-configmap
namespace: native-flink
Mounting it through Pod Template.
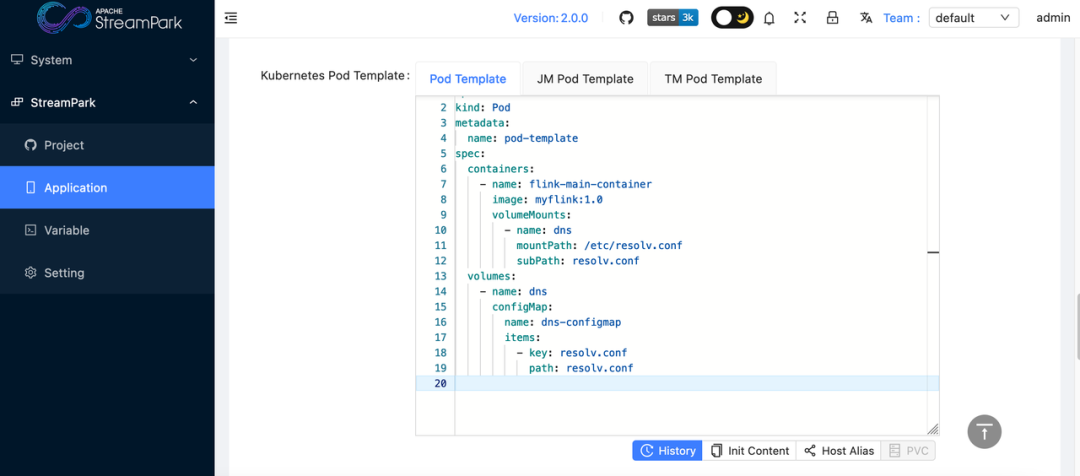
This way, DNS related to the big data platform can be maintained on dnsmasq, while the host machine running Flink jobs can follow the DNS resolution process.
-
First, check the local hosts file to see if there is a corresponding relationship, read the record for resolution, and proceed to the next step if not.
-
The operating system checks the local DNS cache, and if not found, moves to the next step.
-
The operating system searches the DNS server address defined in our network configuration.
This achieves dynamic recognition of DNS changes.
06 Multi-Instance Deployment Practice
In actual production environments, we often need to operate multiple clusters, including a set for testing and a set for official online use. Tasks are first verified and performance tested in the test cluster, then released to the official online cluster after ensuring accuracy.
step1: Modify the port number to avoid conflicts between multiple service ports
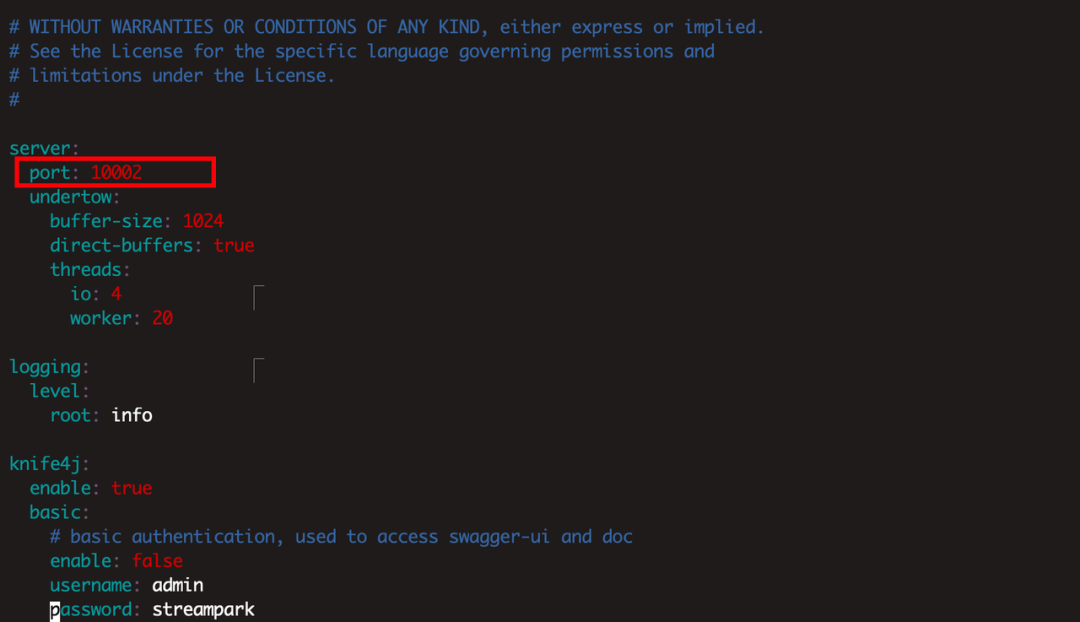
step2: Modify workspace
Different instance services need to configure different workspaces to avoid resource interference leading to strange bugs.
step3: Launch multi-instance services
To achieve isolation between production and testing environments, we introduced a key step at the beginning of the startup process. We input the command (for the Hadoop B cluster):
export HADOOP_CONF_DIR=/home/streamx/conf
This effectively cut off the default logic of Flink on K8s loading HDFS configuration. This operation ensures that A StreamPark only connects to A Hadoop environment, while B StreamPark connects to B Hadoop environment, thus achieving complete isolation between testing and production environments.
Specifically, after this command takes effect, we can ensure that Flink jobs submitted on port 10002 connect to the B Hadoop environment. Thus, the B Hadoop environment is isolated from the Hadoop environment used by Flink jobs submitted on port 10000 in the past, effectively preventing interference between different environments and ensuring system stability and reliability.
The following content is an analysis of Flink's logic for loading the Hadoop environment:
// Process of finding Hadoop configuration files
//1. First, check if the parameter kubernetes.hadoop.conf.config-map.name is added
@Override
public Optional<String> get
ExistingHadoopConfigurationConfigMap() {
final String existingHadoopConfigMap =
flinkConfig.getString(KubernetesConfigOptions.HADOOP_CONF_CONFIG_MAP);
if (StringUtils.isBlank(existingHadoopConfigMap)) {
return Optional.empty();
} else {
return Optional.of(existingHadoopConfigMap.trim());
}
}
@Override
public Optional<String> getLocalHadoopConfigurationDirectory() {
// 2. If parameter 1 is not specified, check for the HADOOP_CONF_DIR environment variable in the local environment where the native command is submitted
final String hadoopConfDirEnv = System.getenv(Constants.ENV_HADOOP_CONF_DIR);
if (StringUtils.isNotBlank(hadoopConfDirEnv)) {
return Optional.of(hadoopConfDirEnv);
}
// 3. If environment variable 2 is not present, continue to check for the HADOOP_HOME environment variable
final String hadoopHomeEnv = System.getenv(Constants.ENV_HADOOP_HOME);
if (StringUtils.isNotBlank(hadoopHomeEnv)) {
// Hadoop 2.2+
final File hadoop2ConfDir = new File(hadoopHomeEnv, "/etc/hadoop");
if (hadoop2ConfDir.exists()) {
return Optional.of(hadoop2ConfDir.getAbsolutePath());
}
// Hadoop 1.x
final File hadoop1ConfDir = a new File(hadoopHomeEnv, "/conf");
if (hadoop1ConfDir.exists()) {
return Optional.of(hadoop1ConfDir.getAbsolutePath());
}
}
return Optional.empty();
}
final List<File> hadoopConfigurationFileItems = getHadoopConfigurationFileItems(localHadoopConfigurationDirectory.get());
// If 1, 2, 3 are not found, it means there is no Hadoop environment
if (hadoopConfigurationFileItems.isEmpty()) {
LOG.warn(
"Found 0 files in directory {}, skip to mount the Hadoop Configuration ConfigMap.",
localHadoopConfigurationDirectory.get());
return flinkPod;
}
// If 2 or 3 exists, it will look for core-site.xml and hdfs-site.xml files in the path
private List<File> getHadoopConfigurationFileItems(String localHadoopConfigurationDirectory) {
final List<String> expectedFileNames = new ArrayList<>();
expectedFileNames.add("core-site.xml");
expectedFileNames.add("hdfs-site.xml");
final File directory = new File(localHadoopConfigurationDirectory);
if (directory.exists() and directory.isDirectory()) {
return Arrays.stream(directory.listFiles())
.filter(
file ->
file.isFile()
and expectedFileNames.stream()
.anyMatch(name -> file.getName().equals(name)))
.collect(Collectors.toList());
} else {
return Collections.emptyList();
}
}
// If a Hadoop environment is present, the above two files will be parsed as key-value pairs, and then constructed into a ConfigMap, with the name following this naming rule
public static String getHadoopConfConfigMapName(String clusterId) {
return Constants.HADOOP_CONF_CONFIG_MAP_PREFIX + clusterId;
}
Then conduct process port occupancy queries:
netstat -tlnp | grep 10000
netstat -tlnp | grep 10002
Benefits Brought
Our team has been using StreamX (the predecessor of StreamPark) and, after more than a year of practice and refinement, StreamPark has significantly improved our challenges in developing, managing, and operating Apache Flink® jobs. As a one-stop service platform, StreamPark greatly simplifies the entire development process. Now, we can complete job development, compilation, and release directly on the StreamPark platform, not only lowering the management and deployment threshold of Flink but also significantly improving development efficiency.
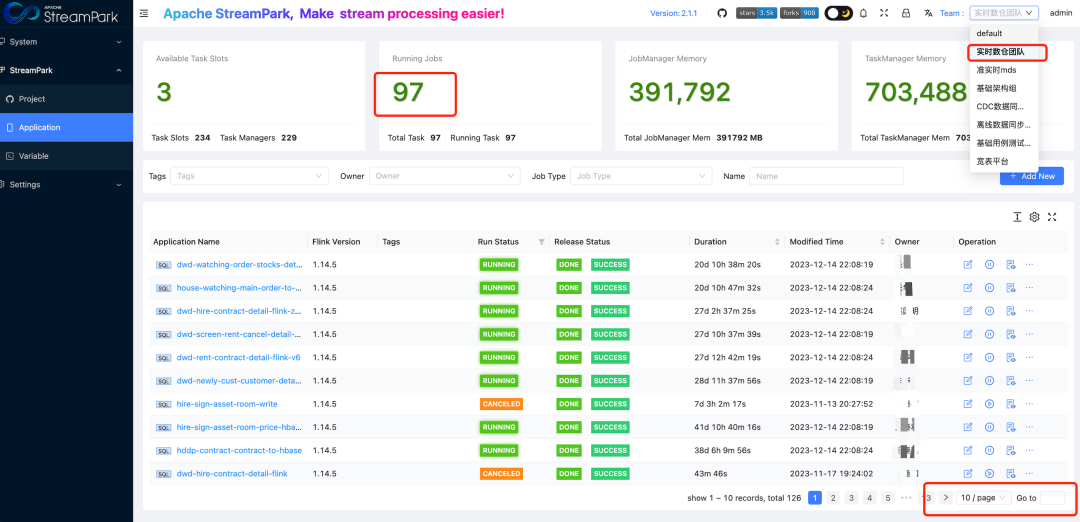
Since deploying StreamPark, we have been using the platform on a large scale in a production environment. From initially managing over 50 FlinkSQL jobs to nearly 500 jobs now, as shown in the diagram, StreamPark is divided into 7 teams, each with dozens of jobs. This transformation not only demonstrates StreamPark's scalability and efficiency but also fully proves its strong practical value in actual business.
Future Expectations
As one of the early users of StreamPark, we have maintained close communication with the community, participating in the stability improvement of StreamPark. We have submitted bugs encountered in production operation and new features to the community. In the future, we hope to manage the metadata information of Apache Paimon lake tables and the capability of auxiliary jobs for
Paimon's Actions on StreamPark. Based on the Flink engine, by interfacing with the Catalog of lake tables and Action jobs, we aim to realize the management and optimization of lake table jobs in one integrated capability. Currently, StreamPark is working on integrating the capabilities with Paimon data, which will greatly assist in real-time data lake ingestion in the future.
We are very grateful for the technical support that the StreamPark team has provided us all along. We wish Apache StreamPark continued success, more users, and its early graduation to become a top-level Apache project.