
**Foreword: **This article mainly introduces the implementation of a streaming data warehouse by Bondex, a supply chain logistics service provider, in the process of digital transformation using the Paimon + StreamPark platform. We provide an easy-to-follow operational manual with the Apache StreamPark integrated stream-batch platform to help users submit Flink tasks and quickly master the use of Paimon.
- Introduction to Company Business
- Pain Points and Selection in Big Data Technology
- Production Practice
- Troubleshooting Analysis
- Future Planning
01 Introduction to Company Business
Bondex Group has always focused on the field of supply chain logistics. By creating an excellent international logistics platform, it provides customers with end-to-end one-stop intelligent supply chain logistics services. The group currently has over 2,000 employees, an annual turnover of more than 12 billion RMB, a network covering over 200 ports globally, and more than 80 branches and subsidiaries at home and abroad, aiding Chinese enterprises to connect with the world.
Business Background
As the company continues to expand and the complexity of its business increases, in order to better achieve resource optimization and process improvement, the Operations and Process Management Department needs to monitor the company's business operations in real time to ensure the stability and efficiency of business processes.
The Operations and Process Management Department is responsible for overseeing the execution of various business processes within the company, including the volume of orders for sea, air, and rail transport across different regions and business divisions, large customer order volumes, route order volumes, the amount of business entrusted to each operation site for customs, warehousing, and land transportation, as well as the actual revenue and expenses of each region and business division on the day. Through monitoring and analysis of these processes, the company can identify potential issues and bottlenecks, propose measures for improvement and suggestions, in order to optimize operational efficiency.
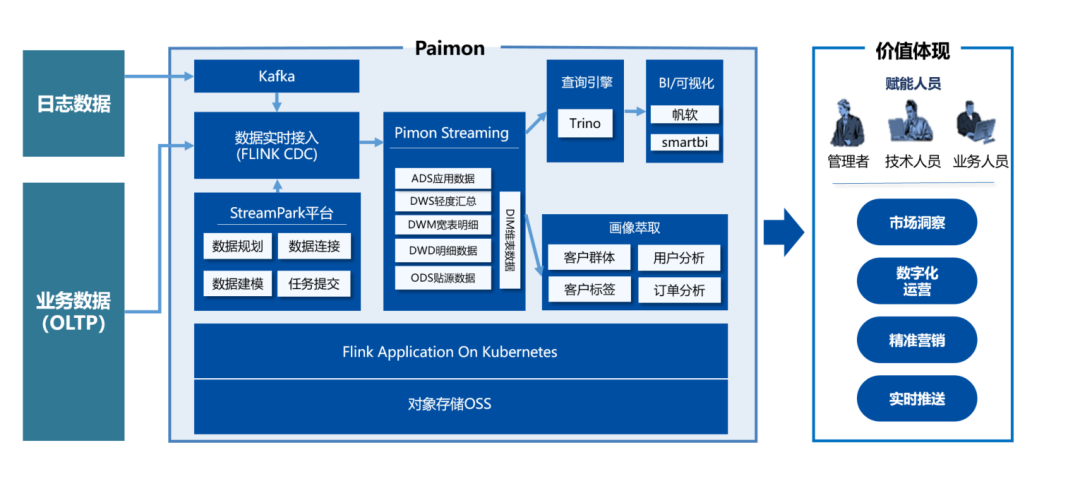
Real-Time Data Warehouse Architecture:
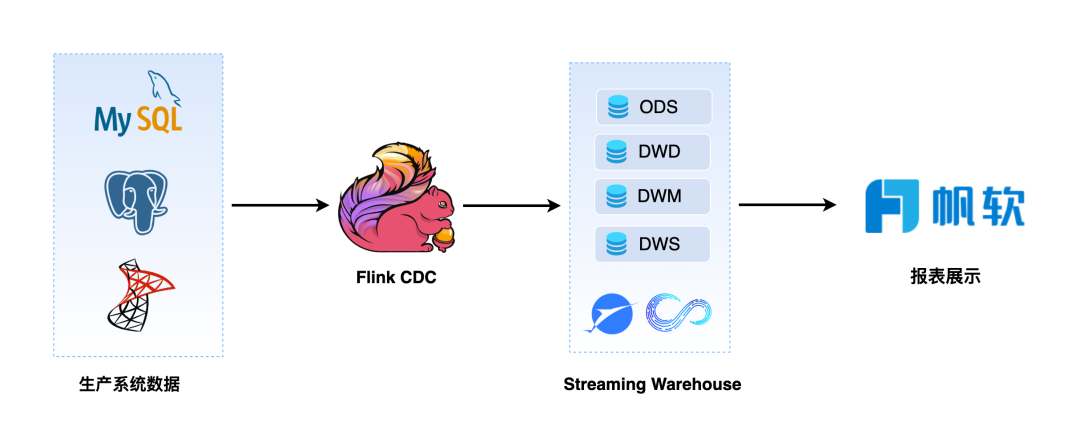
The current system requires direct collection of real-time data from the production system, but there are multiple data sources that need to be associated for queries. The Fanruan report is not user-friendly when dealing with multiple data sources and cannot re-aggregate multiple data sources. Scheduled queries to the production system database can put pressure on it, affecting the stable operation of the production system. Therefore, we need to introduce a warehouse that can handle real-time data through Flink CDC technology for stream processing. This data warehouse needs to be able to collect real-time data from multiple data sources and on this basis, perform complex associated SQL queries, machine learning, etc., and avoid unscheduled queries to the production system, thereby reducing the load on the production system and ensuring its stable operation.
02 Big Data Technology Pain Points and Selection
Since its establishment, the Bondex big data team has always focused on using efficient operational tools or platforms to achieve effective staffing arrangements, optimize repetitive labor, and reduce manual operations.
While offline batch data processing has been able to support the group's basic cockpit and management reporting, the Transportation Management Department of the group has proposed the need for real-time statistics on order quantities and operational volumes. The finance department has expressed the need for a real-time display of cash flow. In this context, a big data-based integrated stream-batch solution became imperative.
Although the big data department has already utilized Apache Doris for integrated storage and computing of lakehouse architecture and has published articles on lakehouse construction in the Doris community, there are some issues that need to be addressed, such as the inability to reuse streaming data storage, the inaccessibility of intermediate layer data, and the inability to perform real-time aggregation calculations.
Sorted by the evolution of architecture over recent years, the common architectural solutions are as follows:
Hadoop Architecture
The demarcation point between traditional data warehouses and internet data warehouses dates back to the early days of the internet when the requirements for data analysis were not high, mainly focusing on reports with low real-time needs to support decision-making. This gave rise to offline data analysis solutions.
**Advantages: **Supports a rich variety of data types, capable of massive computations, low requirements for machine configurations, low timeliness, fault-tolerant.
**Disadvantages: **Does not support real-time; complex to maintain; the query optimizer is not as good as MPP, slow response.
Selection Basis: Does not support real-time; maintenance is complex, which does not conform to the principle of streamlined staffing; poor performance.
Lambda Architecture
Lambda Architecture is a real-time big data processing framework proposed by Nathan Marz, the author of Storm. Marz developed the famous real-time big data processing framework Apache Storm while working at Twitter, and the Lambda Architecture is the culmination of his years of experience in distributed big data systems.
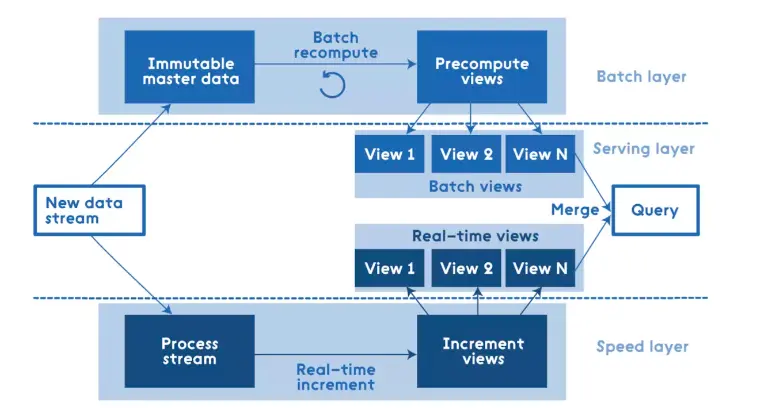
Data stream processing is divided into three layers: Serving Layer, Speed Layer, and Batch Layer:
- Batch Layer: Processes offline data and eventually provides a view service to the business;
- Speed Layer: Processes real-time incremental data and eventually provides a view service to the business;
- Serving Layer: Responds to user requests, performs aggregation calculations on offline and incremental data, and ultimately provides the service;
The advantage is that offline and real-time computations are separated, using two sets of frameworks, which makes the architecture stable.
The disadvantage is that it is difficult to maintain consistency between offline and real-time data, and operational staff need to maintain two sets of frameworks and three layers of architecture. Developers need to write three sets of code.
Selection Basis: Data consistency is uncontrollable; operations and development require significant workload, which does not conform to the principle of streamlined staffing.
Kappa Architecture
The Kappa Architecture uses a single stream-processing framework to address both offline and real-time data, solving all problems with a real-time stream, with the goal of providing fast and reliable query access to results. It is highly suitable for various data processing workloads, including continuous data pipelines, real-time data processing, machine learning models and real-time analytics, IoT systems, and many other use cases with a single technology stack.
It is typically implemented using a streaming processing engine such as Apache Flink, Apache Storm, Apache Kinesis, Apache Kafka, designed to handle large data streams and provide fast and reliable query results.
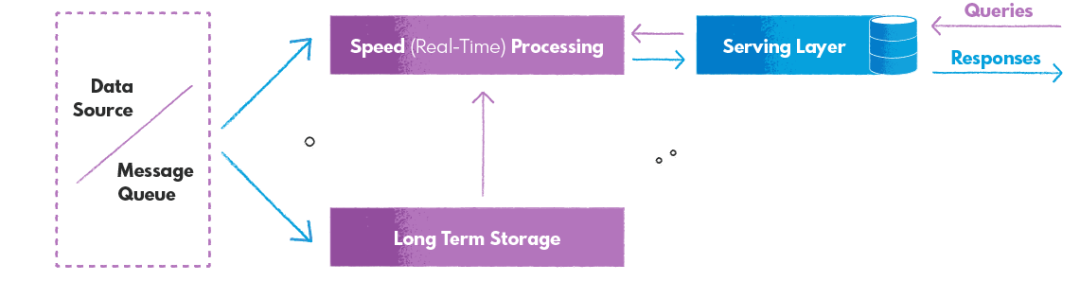
**Advantages: **Single data stream processing framework.
**Disadvantages: **Although its architecture is simpler compared to Lambda Architecture, the setup and maintenance of the streaming processing framework are relatively complex, and it lacks true offline data processing capabilities; storing large amounts of data in streaming platforms can be costly.
Selection Basis: The capability for offline data processing needs to be retained, and costs controlled.
Iceberg
Therefore, we also researched Apache Iceberg, whose snapshot feature can to some extent achieve streaming-batch integration. However, the issue with it is that the real-time table layer based on Kafka is either not queryable or cannot reuse existing tables, with a strong dependency on Kafka. It requires the use of Kafka to write intermediate results to Iceberg tables, increasing system complexity and maintainability.
Selection Basis: A Kafka-free real-time architecture has been implemented, intermediate data cannot be made queryable or reusable.
Streaming Data Warehouse (Continuation of the Kappa Architecture)
Since the FTS0.3.0 version, the BonDex big data team has participated in the construction of a streaming data warehouse, aiming to further reduce the complexity of the data processing framework and streamline personnel configuration. The initial principle was to get involved with the trend, to continuously learn and improve, and to move closer to cutting-edge technology. The team unanimously believes that it is essential to embrace challenges and "cross the river by feeling the stones." Fortunately, after several iterations, the problems that initially arose have been gradually resolved with the efficient cooperation of the community.
The architecture of the streaming data warehouse is as follows:
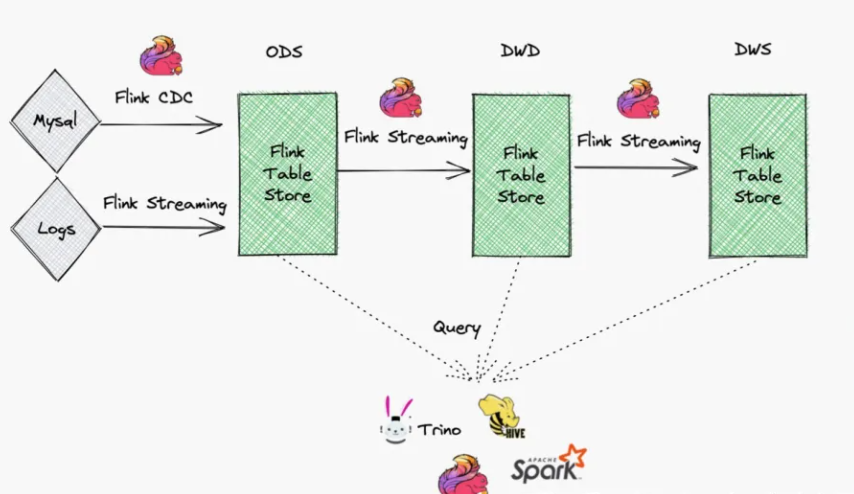
Continuing the characteristics of the Kappa architecture with a single stream processing framework, the advantage lies in the fact that the underlying Paimon technology support makes the data traceable throughout the entire chain. The data warehouse layer architecture can be reused, while also considering the processing capabilities of both offline and real-time data, reducing the waste of storage and computing resources.
03 Production Practices
This solution adopts Flink Application on K8s clusters, with Flink CDC for real-time ingestion of relational database data from business systems. Tasks for Flink + Paimon Streaming Data Warehouse are submitted through the StreamPark task platform, with the Trino engine ultimately used to access Finereport for service provision and developer queries. Paimon's underlying storage supports the S3 protocol, and as the company's big data services rely on Alibaba Cloud, Object Storage Service (OSS) is used as the data filesystem.
StreamPark is a real-time computing platform that leverages the powerful capabilities of Paimon to process real-time data streams. This platform offers the following key features:
**Real-time Data Processing: **StreamPark supports the submission of real-time data stream tasks, capable of real-time acquisition, transformation, filtering, and analysis of data. This is extremely important for applications that require rapid response to real-time data, such as real-time monitoring, real-time recommendations, and real-time risk control.
**Scalability: **Capable of efficiently processing large-scale real-time data with good scalability. It can operate in a distributed computing environment, automatically handling parallelization, fault recovery, and load balancing to ensure efficient and reliable data processing.
**Flink Integration: **Built on Apache Flink, it leverages Flink’s powerful stream processing engine for high performance and robustness. Users can fully utilize the features and ecosystem of Flink, such as its extensive connectors, state management, and event-time processing.
**Ease of Use: **Provides a straightforward graphical interface and simplified API, enabling easy construction and deployment of data processing tasks without needing to delve into underlying technical details.
By submitting Paimon tasks on the StreamPark platform, we can establish a full-link real-time flowing, queryable, and layered reusable Pipline.
The main components versions used are as follows:
- flink-1.16.0-scala-2.12
- paimon-flink-1.16-0.4-20230424.001927-40.jar
- apache-streampark_2.12-2.0.0
- kubernetes v1.18.3
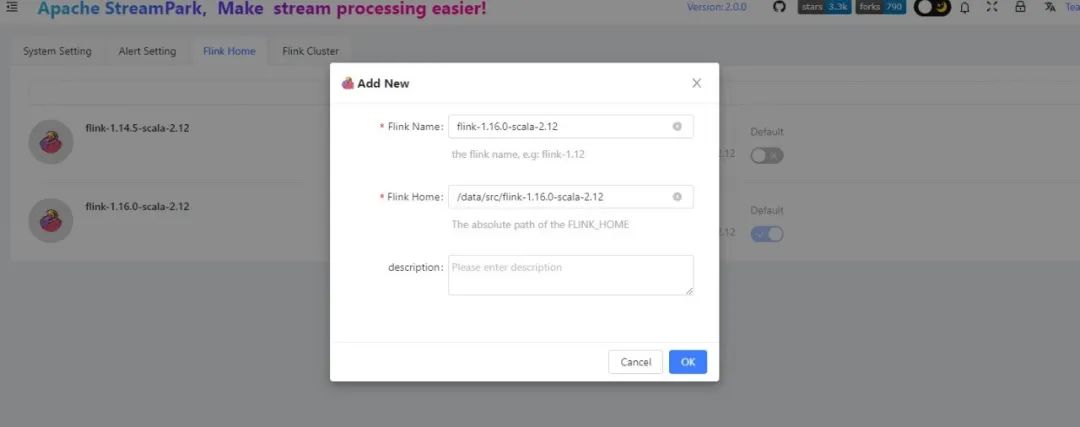
Environment Setup
Download flink-1.16.0-scala-2.12.tar.gz which can be obtained from the official Flink website. Download the corresponding version of the package to the StreamPark deployment server.
# Unzip
tar zxvf flink-1.16.0-scala-2.12.tar.gz
# Modify the flink-conf configuration file and start the cluster
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: localhost
jobmanager.memory.process.size: 4096m
taskmanager.bind-host: localhost
taskmanager.host: localhost
taskmanager.memory.process.size: 4096m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 4
akka.ask.timeout: 100s
web.timeout: 1000000
#checkpoints&&savepoints
state.checkpoints.dir: file:///opt/flink/checkpoints
state.savepoints.dir: file:///opt/flink/savepoints
execution.checkpointing.interval: 2min
# When the job is manually canceled/paused, the Checkpoint state information of the job will be retained
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
state.backend: rocksdb
# Number of completed Checkpoints to retain
state.checkpoints.num-retained: 2000
state.backend.incremental: true
execution.checkpointing.checkpoints-after-tasks-finish.enabled: true
#OSS
fs.oss.endpoint: oss-cn-zhangjiakou-internal.aliyuncs.com
fs.oss.accessKeyId: xxxxxxxxxxxxxxxxxxxxxxx
fs.oss.accessKeySecret: xxxxxxxxxxxxxxxxxxxxxxx
fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem
jobmanager.execution.failover-strategy: region
rest.port: 8081
rest.address: localhost
It is suggested to add FLINK_HOME locally for convenient troubleshooting before deploying on k8s.
vim /etc/profile
#FLINK
export FLINK_HOME=/data/src/flink-1.16.0-scala-2.12
export PATH=$PATH:$FLINK_HOME/bin
source /etc/profile
In StreamPark, add Flink conf:
To build the Flink 1.16.0 base image, pull the corresponding version of the image from Docker Hub.
# Pull the image
docker pull flink:1.16.0-scala_2.12-java8
# Tag the image
docker tagflink:1.16.0-scala_2.12-java8 registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
# Push to the company repository
docker pushregistry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
Create a Dockerfile & target directory to place the flink-oss-fs-hadoop JAR package in that directory. Download the shaded Hadoop OSS file system jar package from:
https://repository.apache.org/snapshots/org/apache/paimon/paimon-oss/
.
├── Dockerfile
└── target
└── flink-oss-fs-hadoop-1.16.0.jar
touch Dockerfile
mkdir target
#vim Dockerfile
FROM registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
RUN mkdir /opt/flink/plugins/oss-fs-hadoop
COPY target/flink-oss-fs-hadoop-1.16.0.jar /opt/flink/plugins/oss-fs-hadoop
Build base image
docker build -t flink-table-store:v1.16.0 .
docker tag flink-table-store:v1.16.0 registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
docker push registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
Next, prepare the Paimon jar package. You can download the corresponding version from the Apache Repository. It's important to note that it should be consistent with the major version of Flink.
Managing Jobs with Apache StreamPark™
Prerequisites:
- Kubernetes client connection configuration
- Kubernetes RBAC configuration
- Container image repository configuration (the free version of Alibaba Cloud image is used in this case)
- Create a PVC resource to mount checkpoints/savepoints
Kubernetes Client Connection Configuration:
Copy the k8s master node's ~/.kube/config configuration directly to the directory on the StreamPark server, then execute the following command on the StreamPark server to display the k8s cluster as running, which indicates successful permission and network verification.
kubectl cluster-info
Kubernetes RBAC Configuration, create the streampark namespace:
kubectl create ns streampark
Use the default account to create the clusterrolebinding resource:
kubectl create secret docker-registry streamparksecret
--docker-server=registry-vpc.cn-zhangjiakou.aliyuncs.com
--docker-username=xxxxxx
--docker-password=xxxxxx -n streamx```
Container Image Registry Configuration:
In this case, Alibaba Cloud's Container Registry Service (ACR) is used, but you can also substitute it with a self-hosted image service such as Harbor.
Create a namespace named StreamPark (set the security setting to private).
Configure the image repository in StreamPark; task build images will be pushed to the repository.
Create a k8s secret key to pull images from ACR; streamparksecret is the name of the secret, customizable.
kubectl create secret docker-registry streamparksecret
--docker-server=registry-vpc.cn-zhangjiakou.aliyuncs.com
--docker-username=xxxxxx
--docker-password=xxxxxx -n streamx
Creation of PVC Resources for Checkpoints/Savepoints, Utilizing Alibaba Cloud's OSS for K8S Persistence
OSS CSI Plugin:
The OSS CSI plugin can be used to help simplify storage management. You can use the CSI configuration to create a PV, and define PVCs and pods as usual. For the YAML file reference, visit: https://bondextest.oss-cn-zhangjiakou.aliyuncs.com/ossyaml.zip
Configuration Requirements:
- Create a service account with the necessary RBAC permissions, please refer as below:
https://github.com/kubernetes-sigs/alibaba-cloud-csi-driver/blob/master/docs/oss.md
kubectl -f rbac.yaml
- Deploy the OSS CSI Plugin:
kubectl -f oss-plugin.yaml
- Create PV for CP (Checkpoints) & SP (Savepoints):
kubectl -f checkpoints_pv.yaml kubectl -f savepoints_pv.yaml
- Create PVC for CP & SP:
kubectl -f checkpoints_pvc.yaml kubectl -f savepoints_pvc.yaml
Once the dependent environment is configured, we can start using Paimon for layered development of the streaming data warehouse.
Case Study
Real-time calculation of sea and air freight consignment volumes.
Job Submission: Initialize Paimon catalog configuration.
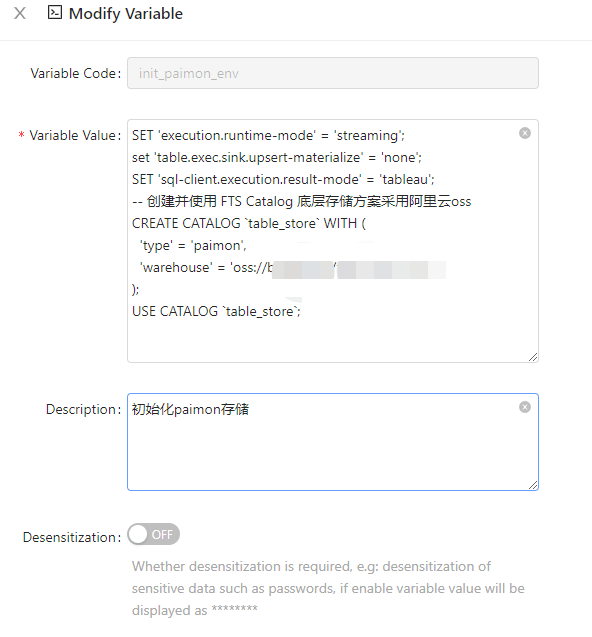
SET 'execution.runtime-mode' = 'streaming';
set 'table.exec.sink.upsert-materialize' = 'none';
SET 'sql-client.execution.result-mode' = 'tableau';
-- Create and use FTS Catalog with underlying storage solution using Alibaba Cloud OSS
CREATE CATALOG `table_store` WITH (
'type' = 'paimon',
'warehouse' = 'oss://xxxxx/xxxxx' # customize oss storage path
);
USE CATALOG `table_store`;
A single job extracts table data from postgres, mysql, and sqlserver databases and writes it into Paimon.
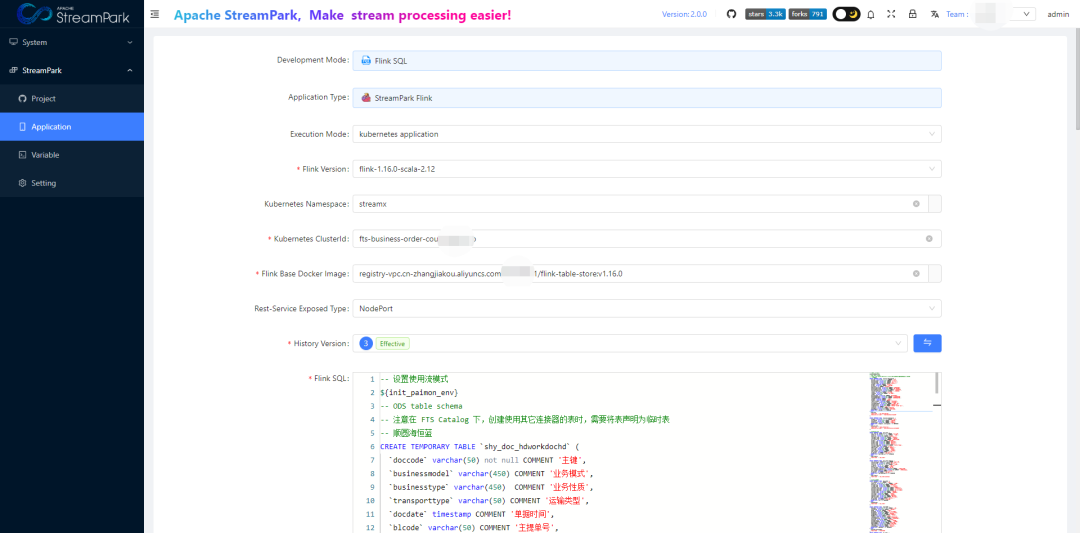
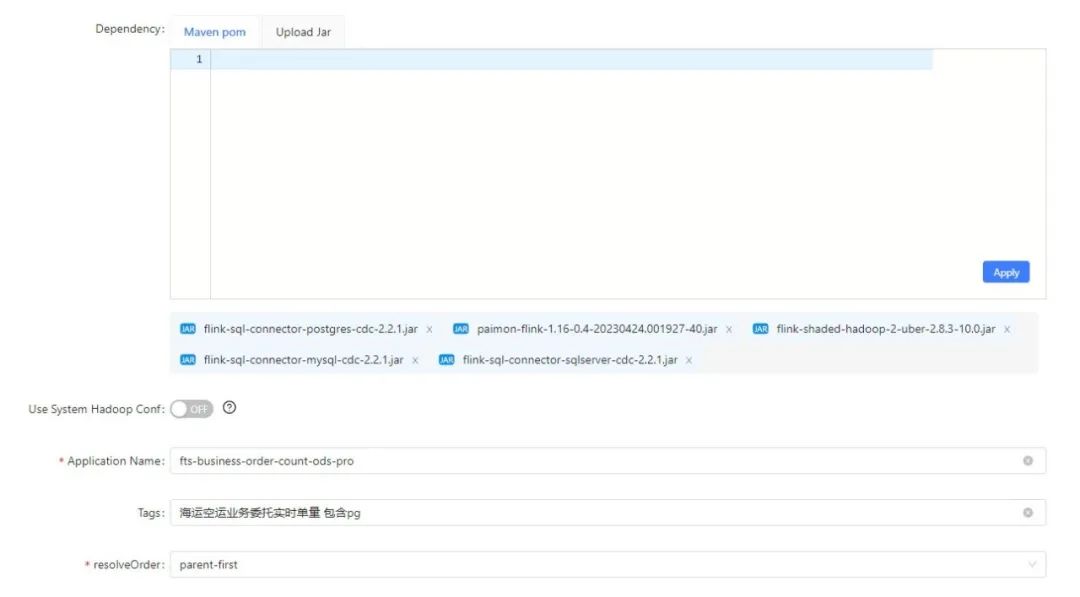
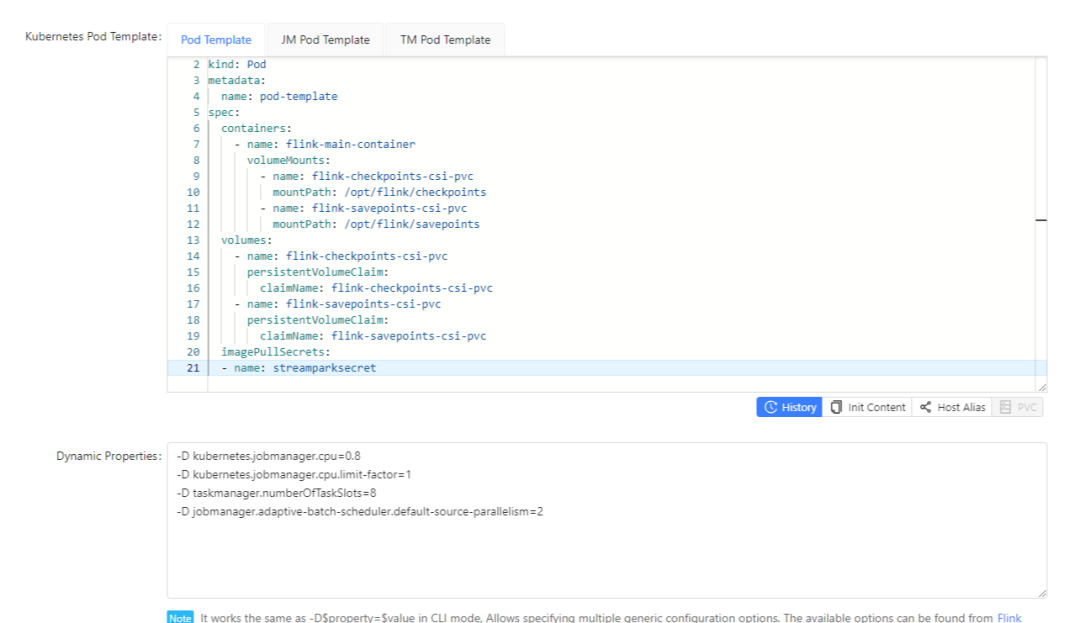
Details are as follows:
Development Mode:Flink SQL
Execution Mode :kubernetes application
Flink Version :flink-1.16.0-scala-2.12
Kubernetes Namespace :streamx
Kubernetes ClusterId :(Task name can be customized)
# Base image uploaded to Alibaba Cloud Image Repository
Flink Base Docker Image :registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
Rest-Service Exposed Type:NodePort
# Paimon base dependency package:
paimon-flink-1.16-0.4-20230424.001927-40.jar
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
# FlinkCDC dependency package download address:
https://github.com/ververica/flink-cdc-connectors/releases/tag/release-2.2.0
pod template:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
containers:
- name: flink-main-container
volumeMounts:
- name: flink-checkpoints-csi-pvc
mountPath: /opt/flink/checkpoints
- name: flink-savepoints-csi-pvc
mountPath: /opt/flink/savepoints
volumes:
- name: flink-checkpoints-csi-pvc
persistentVolumeClaim:
claimName: flink-checkpoints-csi-pvc
- name: flink-savepoints-csi-pvc
persistentVolumeClaim:
claimName: flink-savepoints-csi-pvc
imagePullSecrets:
- name: streamparksecret
Flink sql:
- Establish the relationship between the source table and the ODS table in Paimon, here it is a one-to-one mapping between the source table and the target table.
-- PostgreSQL database example
CREATE TEMPORARY TABLE `shy_doc_hdworkdochd` (
`doccode` varchar(50) not null COMMENT 'Primary Key',
`businessmodel` varchar(450) COMMENT 'Business Model',
`businesstype` varchar(450) COMMENT 'Business Type',
`transporttype` varchar(50) COMMENT 'Transportation Type',
......
`bookingguid` varchar(50) COMMENT 'Operation Number',
PRIMARY KEY (`doccode`) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'Database server IP address',
'port' = 'Port number',
'username' = 'Username',
'password' = 'Password',
'database-name' = 'Database name',
'schema-name' = 'dev',
'decoding.plugin.name' = 'wal2json',,
'table-name' = 'doc_hdworkdochd',
'debezium.slot.name' = 'hdworkdochdslotname03'
);
CREATE TEMPORARY TABLE `shy_base_enterprise` (
`entguid` varchar(50) not null COMMENT 'Primary Key',
`entorgcode` varchar(450) COMMENT 'Customer Code',
`entnature` varchar(450) COMMENT 'Customer Type',
`entfullname` varchar(50) COMMENT 'Customer Full Name',
PRIMARY KEY (`entguid`,`entorgcode`) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'Database server IP address',
'port' = 'Port number',
'username' = 'Username',
'password' = 'Password',
'database-name' = 'Database name',
'schema-name' = 'dev',
'decoding.plugin.name' = 'wal2json',
'table-name' = 'base_enterprise',
'debezium.snapshot.mode'='never', -- Incremental synchronization (ignore this property for full + incremental)
'debezium.slot.name' = 'base_enterprise_slotname03'
);
-- Create the corresponding target table in the ods layer on Paimon according to the source table structure
CREATE TABLE IF NOT EXISTS ods.`ods_shy_jh_doc_hdworkdochd` (
`o_year` BIGINT NOT NULL COMMENT 'Partition Field',
`create_date` timestamp NOT NULL COMMENT 'Creation Time',
PRIMARY KEY (`o_year`, `doccode`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `shy_doc_hdworkdochd` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
CREATE TABLE IF NOT EXISTS ods.`ods_shy_base_enterprise` (
`create_date` timestamp NOT NULL COMMENT 'Creation Time',
PRIMARY KEY (`entguid`,`entorgcode`) NOT ENFORCED
)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `shy_base_enterprise` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- Set the job name, execute the job task to write the source table data into the corresponding Paimon table in real time
SET 'pipeline.name' = 'ods_doc_hdworkdochd';
INSERT INTO
ods.`ods_shy_jh_doc_hdworkdochd`
SELECT
*
,YEAR(`docdate`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
`shy_doc_hdworkdochd` where `docdate` is not null and `docdate` > '2023-01-01';
SET 'pipeline.name' = 'ods_shy_base_enterprise';
INSERT INTO
ods.`ods_shy_base_enterprise`
SELECT
*
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
`shy_base_enterprise` where entorgcode is not null and entorgcode <> '';
-- MySQL database example
CREATE TEMPORARY TABLE `doc_order` (
`id` BIGINT NOT NULL COMMENT 'Primary Key',
`order_no` varchar(50) NOT NULL COMMENT 'Order Number',
`business_no` varchar(50) COMMENT 'OMS Service Number',
......
`is_deleted` int COMMENT 'Is Deleted',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'Database server address',
'port' = 'Port number',
'username' = 'Username',
'password' = 'Password',
'database-name' = 'Database name',
'table-name' = 'doc_order'
);
-- Create the corresponding target table in the ods layer on Paimon according to the source table structure
CREATE TABLE IF NOT EXISTS ods.`ods_bondexsea_doc_order` (
`o_year` BIGINT NOT NULL COMMENT 'Partition Field',
`create_date` timestamp NOT NULL COMMENT 'Creation Time',
PRIMARY KEY (`o_year`, `id`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `doc_order` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- Set the job name, execute the job task to write the source table data into the corresponding Paimon table in real time
SET 'pipeline.name' = 'ods_bondexsea_doc_order';
INSERT INTO
ods.`ods_bondexsea_doc_order`
SELECT
*
,YEAR(`gmt_create`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM `doc_order` where gmt_create > '2023-01-01';
-- SQL Server database example
CREATE TEMPORARY TABLE `OrderHAWB` (
`HBLIndex` varchar(50) NOT NULL COMMENT 'Primary Key',
`CustomerNo` varchar(50) COMMENT 'Customer Number',
......
`CreateOPDate` timestamp COMMENT 'Billing Date',
PRIMARY KEY (`HBLIndex`) NOT ENFORCED
) WITH (
'connector' = 'sqlserver-cdc',
'hostname' = 'Database server address',
'port' = 'Port number',
'username' = 'Username',
'password' = 'Password',
'database-name' = 'Database name',
'schema-name' = 'dbo',
-- 'debezium.snapshot.mode' = 'initial' -- Extract both full and incremental
'scan.startup.mode' = 'latest-offset',-- Extract only incremental data
'table-name' = 'OrderHAWB'
);
-- Create the corresponding target table in the ods layer on Paimon according to the source table structure
CREATE TABLE IF NOT EXISTS ods.`ods_airsea_airfreight_orderhawb` (
`o_year` BIGINT NOT NULL COMMENT 'Partition Field',
`create_date` timestamp NOT NULL COMMENT 'Creation Time',
PRIMARY KEY (`o_year`, `HBLIndex`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `OrderHAWB` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- Set the job name, execute the job task to write the source table data into the corresponding Paimon table in real time
SET 'pipeline.name' = 'ods_airsea_airfreight_orderhawb';
INSERT INTO
ods.`ods_airsea_airfreight_orderhawb`
SELECT
RTRIM(`HBLIndex`) as `HBLIndex`
......
,`CreateOPDate`
,YEAR(`CreateOPDate`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM `OrderHAWB` where CreateOPDate > '2023-01-01';
The real-time data writing effect of the business table into the Paimon ods table is as follows:
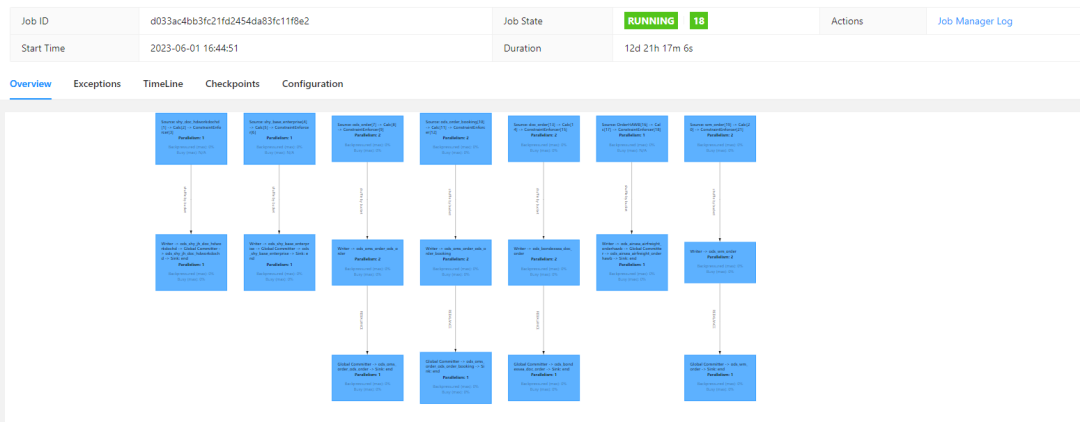
- Flatten the data from the ods layer tables and write it into the dwd layer. This process is essentially about merging the related business tables from the ods layer into the dwd layer. The main focus here is on processing the value of the count_order field. Since the data in the source table may be logically or physically deleted, using the count function for statistics may lead to issues. Therefore, we use the sum aggregate to calculate the order quantity. Each reference_no corresponds to a count_order of 1. If it is logically voided, it will be processed as 0 through SQL, and Paimon will automatically handle physical deletions.
For the dim dimension table, we directly use the dimension table processed in Doris, as the update frequency of the dimension table is low, so there was no need for secondary development within Paimon.
-- Create a wide table at the paimon-dwd layer
CREATE TABLE IF NOT EXISTS dwd.`dwd_business_order` (
`reference_no` varchar(50) NOT NULL COMMENT 'Primary key for the consignment order number',
`bondex_shy_flag` varchar(8) NOT NULL COMMENT 'Differentiator',
`is_server_item` int NOT NULL COMMENT 'Whether it has been linked to an order',
`order_type_name` varchar(50) NOT NULL COMMENT 'Business category',
`consignor_date` DATE COMMENT 'Statistic date',
`consignor_code` varchar(50) COMMENT 'Customer code',
`consignor_name` varchar(160) COMMENT 'Customer name',
`sales_code` varchar(32) NOT NULL COMMENT 'Sales code',
`sales_name` varchar(200) NOT NULL COMMENT 'Sales name',
`delivery_center_op_id` varchar(32) NOT NULL COMMENT 'Delivery number',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT 'Delivery name',
`pol_code` varchar(100) NOT NULL COMMENT 'POL code',
`pot_code` varchar(100) NOT NULL COMMENT 'POT code',
`port_of_dest_code` varchar(100) NOT NULL COMMENT 'POD code',
`is_delete` int not NULL COMMENT 'Whether it is void',
`order_status` varchar(8) NOT NULL COMMENT 'Order status',
`count_order` BIGINT not NULL COMMENT 'Order count',
`o_year` BIGINT NOT NULL COMMENT 'Partition field',
`create_date` timestamp NOT NULL COMMENT 'Creation time',
PRIMARY KEY (`o_year`,`reference_no`,`bondex_shy_flag`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
-- Set 2 buckets under each partition
'bucket' = '2',
'changelog-producer' = 'full-compaction',
'snapshot.time-retained' = '2h',
'changelog-producer.compaction-interval' = '2m'
);
-- Set the job name to merge the related business tables from the ods layer into the dwd layer
SET 'pipeline.name' = 'dwd_business_order';
INSERT INTO
dwd.`dwd_business_order`
SELECT
o.doccode,
......,
YEAR (o.docdate) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.ods_shy_jh_doc_hdworkdochd o
INNER JOIN ods.ods_shy_base_enterprise en ON o.businessguid = en.entguid
LEFT JOIN dim.dim_hhl_user_code sales ON o.salesguid = sales.USER_GUID
LEFT JOIN dim.dim_hhl_user_code op ON o.bookingguid = op.USER_GUID
UNION ALL
SELECT
business_no,
......,
YEAR ( gmt_create ) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.ods_bondexsea_doc_order
UNION ALL
SELECT
HBLIndex,
......,
YEAR ( CreateOPDate ) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.`ods_airsea_airfreight_orderhawb`
;
In the Flink UI, you can see the ods data is joined and cleansed in real-time through Paimon to the table dwd_business_order.
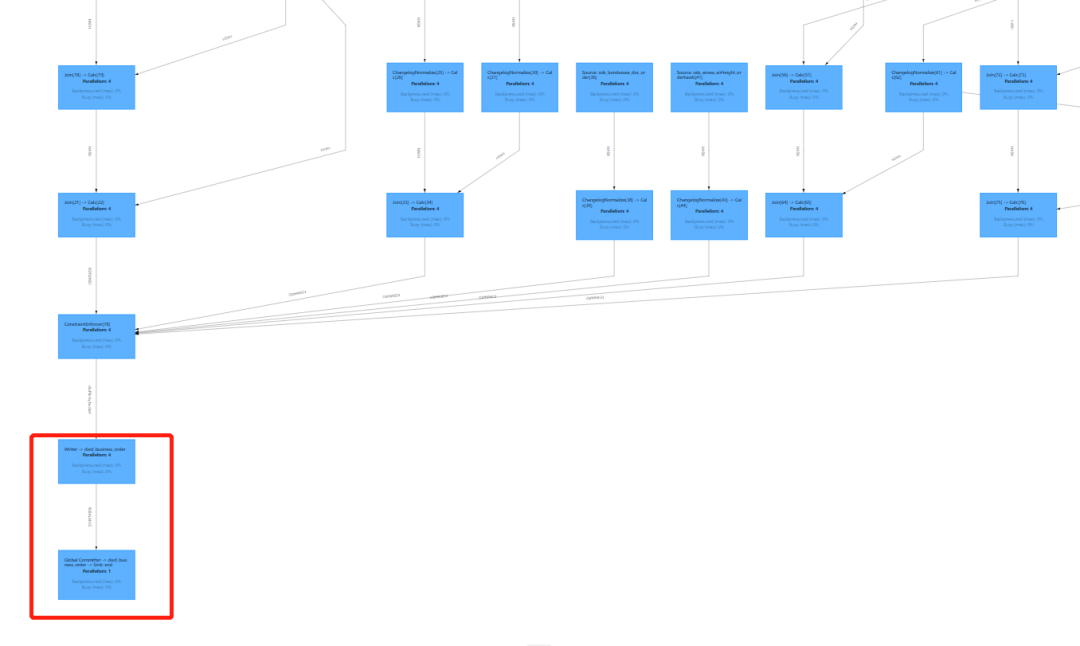
- The data from the dwd layer is lightly aggregated to the dwm layer, and the related data is written into the dwm.dwm_business_order_count table. The data in this table will perform a sum on the aggregated fields based on the primary key, with the sum_orderCount field being the result of the aggregation. Paimon will automatically handle the data that is physically deleted during the sum.
-- Create a lightweight summary table on the dwm layer, summarizing the order volume by date, sales, operation, business category, customer, port of loading, and destination port
CREATE TABLE IF NOT EXISTS dwm.`dwm_business_order_count` (
`l_year` BIGINT NOT NULL COMMENT 'Statistic year',
`l_month` BIGINT NOT NULL COMMENT 'Statistic month',
`l_date` DATE NOT NULL COMMENT 'Statistic date',
`bondex_shy_flag` varchar(8) NOT NULL COMMENT 'Identifier',
`order_type_name` varchar(50) NOT NULL COMMENT 'Business category',
`is_server_item` int NOT NULL COMMENT 'Whether an order has been associated',
`customer_code` varchar(50) NOT NULL COMMENT 'Customer code',
`sales_code` varchar(50) NOT NULL COMMENT 'Sales code',
`delivery_center_op_id` varchar(50) NOT NULL COMMENT 'Delivery ID',
`pol_code` varchar(100) NOT NULL COMMENT 'Port of loading code',
`pot_code` varchar(100) NOT NULL COMMENT 'Transshipment port code',
`port_of_dest_code` varchar(100) NOT NULL COMMENT 'Destination port code',
`customer_name` varchar(200) NOT NULL COMMENT 'Customer name',
`sales_name` varchar(200) NOT NULL COMMENT 'Sales name',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT 'Delivery name',
`sum_orderCount` BIGINT NOT NULL COMMENT 'Order count',
`create_date` timestamp NOT NULL COMMENT 'Creation time',
PRIMARY KEY (`l_year`,
`l_month`,
`l_date`,
`order_type_name`,
`bondex_shy_flag`,
`is_server_item`,
`customer_code`,
`sales_code`,
`delivery_center_op_id`,
`pol_code`,
`pot_code`,
`port_of_dest_code`) NOT ENFORCED
) WITH (
'changelog-producer' = 'full-compaction',
'changelog-producer.compaction-interval' = '2m',
'merge-engine' = 'aggregation', -- Use aggregation to calculate sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true',
'fields.sales_name.ignore-retract'='true',
'fields.customer_name.ignore-retract'='true',
'snapshot.time-retained' = '2h',
'fields.delivery_center_op_name.ignore-retract'='true'
);
-- Set the job name
SET 'pipeline.name' = 'dwm_business_order_count';
INSERT INTO
dwm.`dwm_business_order_count`
SELECT
YEAR(o.`consignor_date`) AS `l_year`
,MONTH(o.`consignor_date`) AS `l_month`
......,
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS create_date
FROM
dwd.`dwd_business_order` o
;
The Flink UI effect is as follows: the data from dwd_business_orders is aggregated into dwm_business_order_count:
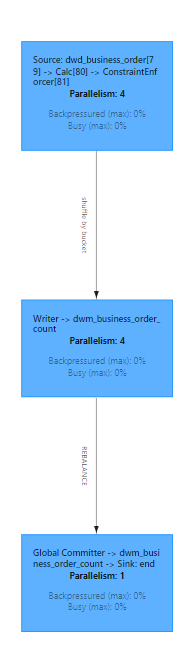
- Aggregate the data from the dwm layer to the dws layer, where the dws layer performs summaries at even finer dimensions.
-- Create a table to aggregate daily order counts by operator and business type
CREATE TABLE IF NOT EXISTS dws.`dws_business_order_count_op` (
`l_year` BIGINT NOT NULL COMMENT 'Statistic Year',
`l_month` BIGINT NOT NULL COMMENT 'Statistic Month',
`l_date` DATE NOT NULL COMMENT 'Statistic Date',
`order_type_name` varchar(50) NOT NULL COMMENT 'Business Category',
`delivery_center_op_id` varchar(50) NOT NULL COMMENT 'Delivery ID',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT 'Delivery Name',
`sum_orderCount` BIGINT NOT NULL COMMENT 'Order Count',
`create_date` timestamp NOT NULL COMMENT 'Creation Time',
PRIMARY KEY (`l_year`, `l_month`,`l_date`,`order_type_name`,`delivery_center_op_id`) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation', -- Use aggregation to compute sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true',
'snapshot.time-retained' = '2h',
'fields.delivery_center_op_name.ignore-retract'='true'
);
-- Set the job name
SET 'pipeline.name' = 'dws_business_order_count_op';
INSERT INTO
dws.`dws_business_order_count_op`
SELECT
o.`l_year`
,o.`l_month`
,o.`l_date`
,o.`order_type_name`
,o.`delivery_center_op_id`
,o.`delivery_center_op_name`
,o.`sum_orderCount`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS create_date
FROM
dwm.`dwm_business_order_count` o
;
The Flink UI reflects the following: Data from dws_business_order_count_op is written to dws_business_order_count_op:
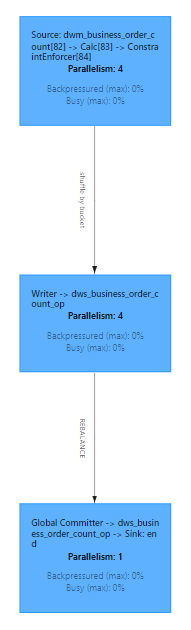
Overall Data Flow Example
Source Table:

paimon-ods:

paimon-dwd:

paimon-dwm:
![]()
paimon-dws:

A special reminder: When extracting from SQL Server databases, if the source table is too large, a full extraction will lock the table. It is recommended to use incremental extraction if the business allows. For a full extraction, SQL Server can use an interim approach where the full data is imported into MySQL, then from MySQL to Paimon-ODS, and later incremental extraction is done through SQL Server.
04 Troubleshooting and Analysis
1. Inaccurate Aggregated Data Calculation
SQL Server CDC collects data into the Paimon table, explanation:
DWD table:
'changelog-producer' = 'input'
ADS table:
'merge-engine' = 'aggregation', -- Using aggregation to compute sum
'fields.sum_amount.aggregate-function' = 'sum'
The ADS layer's aggregated table uses agg sum, which can result in the DWD data stream not generating update_before, creating an incorrect data stream with update_after. For example, if the upstream source table updates from 10 to 30, the DWD layer's data will change to 30, and the ADS aggregation layer's data will also change to 30. But now it turns into an append data, resulting in incorrect data of 10+30=40.
Solution:
By specifying 'changelog-producer' = 'full-compaction', Table Store will compare the results between full compactions and produce the differences as changelog. The latency of changelog is affected by the frequency of full compactions.
By specifying changelog-producer.compaction-interval table property (default value 30min), users can define the maximum interval between two full compactions to ensure latency. This table property does not affect normal compactions and they may still be performed once in a while by writers to reduce reader costs.
This approach can solve the above mentioned issue. However, it has led to a new problem. The default changelog-producer.compaction-interval is 30 minutes, meaning that it takes 30 minutes for changes upstream to be reflected in the ads query. During production, it has been found that changing the compaction interval to 1 minute or 2 minutes can cause inaccuracies in the ADS layer aggregation data again.
'changelog-producer.compaction-interval' = '2m'
When writing into the Flink Table Store, it is necessary to configure table.exec.sink.upsert-materialize= none to avoid generating an upsert stream, ensuring that the Flink Table Store can retain a complete changelog for subsequent stream read operations.
set 'table.exec.sink.upsert-materialize' = 'none'
2. The same sequence.field causes the dwd detailed wide table to not receive data updates
mysql cdc collects data into the paimon table
Explanation:
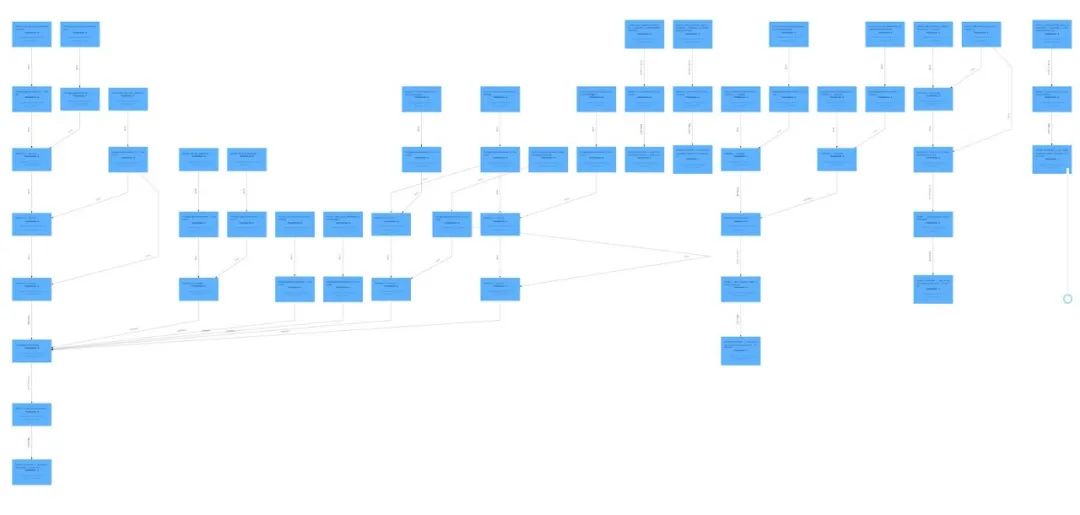
After executing an update on the MySQL source, the data modifications are successfully synchronized to the dwd_orders table.
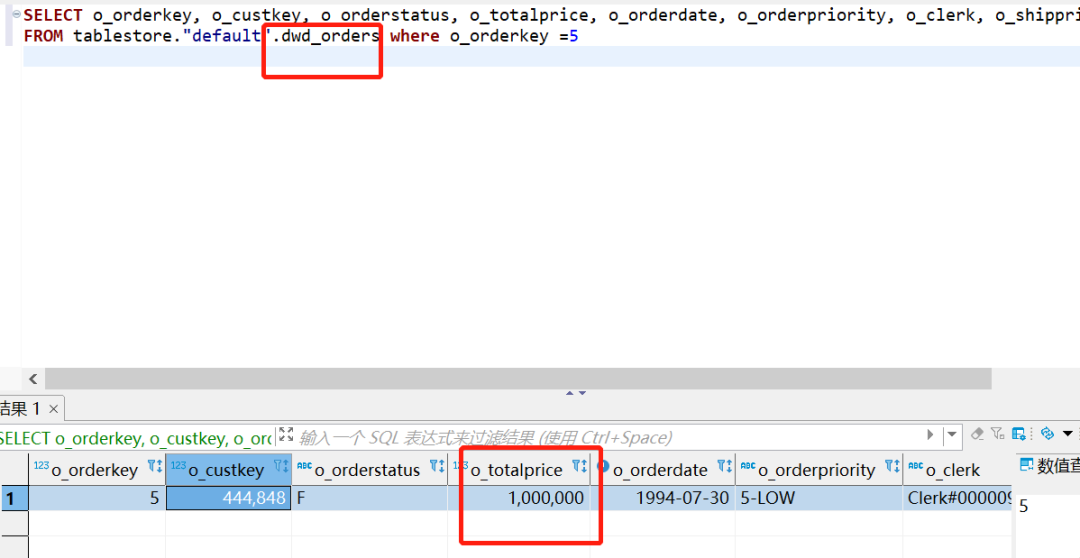
However, upon examining the dwd_enriched_orders table data, it is found to be unsynchronized. When starting the stream mode to observe the data, it is discovered that there is no data flow.
Solution:
Upon investigation, it was discovered that the issue was caused by the configuration of the parameter 'sequence.field' = 'o_orderdate' (using o_orderdate to generate a sequence ID, and when merging records with the same primary key, the record with the larger sequence ID is chosen). Since the o_orderdate field does not change when modifying the price, the 'sequence.field' remains the same, leading to an uncertain order. Therefore, for ROW1 and ROW2, since their o_orderdate are the same, the update will randomly select between them. By removing this parameter, the system will normally generate a sequence number based on the input order, which will not affect the synchronization result.
3. Aggregate function 'last_non_null_value' does not support retraction
Error:
Caused by: java.lang.UnsupportedOperationException: Aggregate function 'last_non_null_value' does not support retraction, If you allow this function to ignore retraction messages, you can configure 'fields.${field_name}.ignore-retract'='true'.
An explanation can be found in the official documentation:
Only sum supports retraction (UPDATE_BEFORE and DELETE), other aggregate functions do not support retraction.
This can be understood as: except for the SUM function, other Agg functions do not support Retraction. To avoid errors when receiving DELETE and UPDATEBEFORE messages, it is necessary to configure 'fields.${field_name}.ignore-retract'='true' for the specified field to ignore retraction and solve this error.
WITH (
'merge-engine' = 'aggregation', -- Use aggregation to compute sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true' #field create_date
);
4. Paimon Task Interruption Failure
Task abnormal interruption leads to pod crash, viewing loki logs shows akka.pattern.AskTimeoutException: Ask timed out on
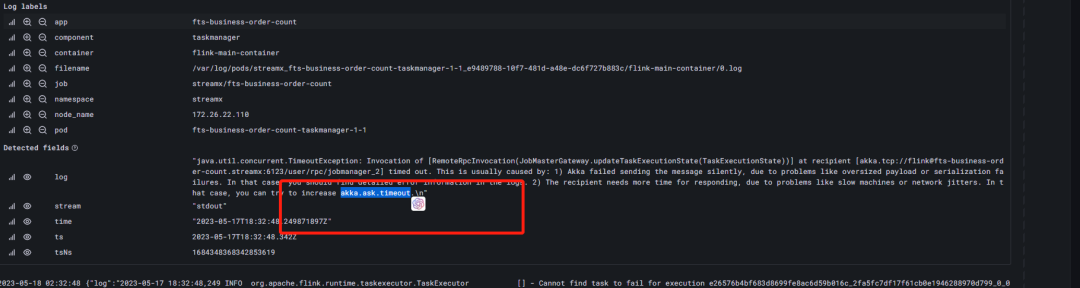
java.util.concurrent.TimeoutException: Invocation of [RemoteRpcInvocation(JobMasterGateway.updateTaskExecutionState(TaskExecutionState))] at recipient [akka.tcp://flink@fts-business-order-count.streampark:6123/user/rpc/jobmanager_2] timed out. This is usually caused by: 1) Akka failed sending the message silently, due to problems like oversized payload or serialization failures. In that case, you should find detailed error information in the logs. 2) The recipient needs more time for responding, due to problems like slow machines or network jitters. In that case, you can try to increase akka.ask.timeout.\n"
The preliminary judgment is that the triggering of akka's timeout mechanism is likely due to the above two reasons. Therefore, adjust the cluster's akka timeout settings and carry out individual task segmentation or increase resource configuration.
To proceed, let's first see how to modify the parameters:
| key | default | describe |
|---|---|---|
| akka.ask.timeout | 10s | Timeout used for all futures and blocking Akka calls. If Flink fails due to timeouts then you should try to increase this value. Timeouts can be caused by slow machines or a congested network. The timeout value requires a time-unit specifier (ms/s/min/h/d). |
| web.timeout | 600000 | Timeout for asynchronous operations by the web monitor in milliseconds. |
In conf/flink-conf.yaml, add the following parameters at the end:
akka.ask.timeout: 100s
web.timeout:1000000
Then manually refresh the flink-conf.yaml in Streampark to verify if the parameters have synchronized successfully.
5. snapshot no such file or directory
It was discovered that cp (checkpoint) is failing.
[Image showing failure of cp]
Corresponding logs at the time show Snapshot missing, with the task status shown as running, but data from the MySQL source table cannot be written into the paimon ods table.
[Image showing status log]
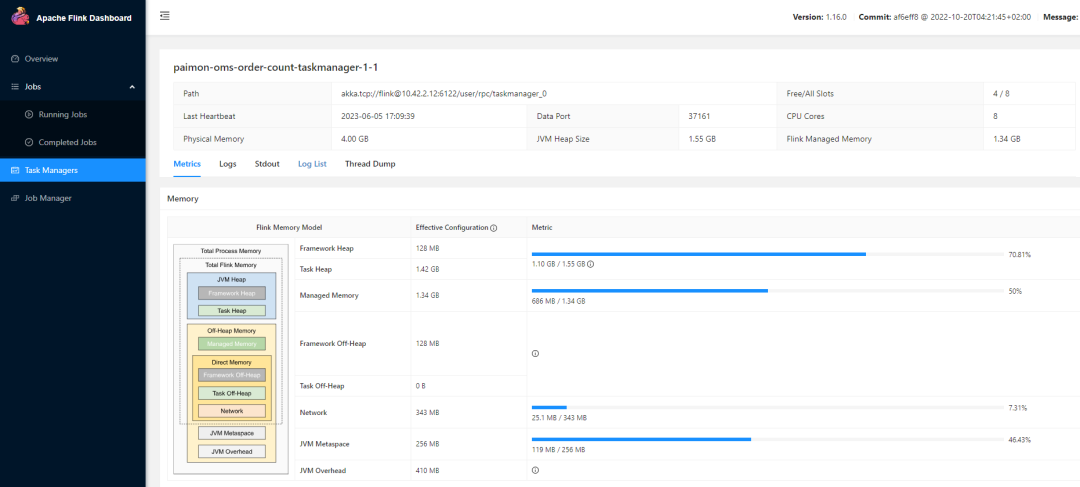
The reason for cp failure is identified as: due to high computation and CPU intensity, threads within the TaskManager are constantly processing elements, without having time to perform the checkpoint.
The reason for being unable to read the Snapshot is: insufficient resources in the Flink cluster, leading to competition between Writer and Committer. During Full-Compaction, an incomplete Snapshot of an expired part was read. The official response to this issue has been fixed:
https://github.com/apache/incubator-paimon/pull/1308
And the solution to the checkpoint failure is to increase parallelism, by adding more deployment taskmanager slots and enhancing the jobmanager CPU resources.
-D kubernetes.jobmanager.cpu=0.8
-D kubernetes.jobmanager.cpu.limit-factor=1
-D taskmanager.numberOfTaskSlots=8
-D jobmanager.adaptive-batch-scheduler.default-source-parallelism=2
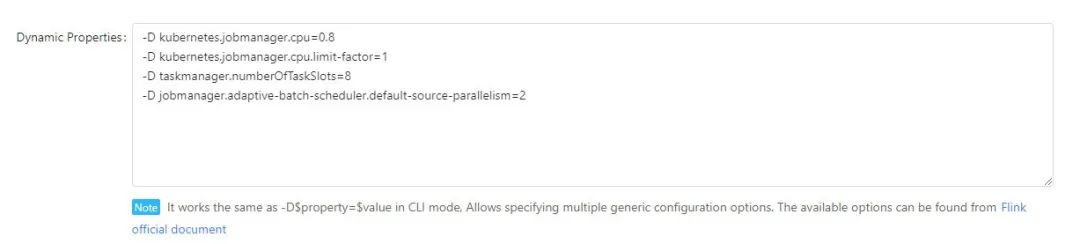
In complex real-time tasks, resources can be increased by modifying dynamic parameters.
05 Future Planning
- Our self-built data platform, Bondata, is integrating Paimon's metadata information, data metric system, lineage, and one-click pipeline features. This integration aims to form HCBondata's data assets and will serve as the foundation for a one-stop data governance initiative.
- Subsequently, we will integrate with Trino Catalog to access Doris, realizing a one-service solution for both offline and real-time data.
- We will continue to advance the pace of building an integrated streaming and batch data warehouse within the group, adopting the architecture of Doris + Paimon.
Here, I would like to thank Teacher Zhixin and the StreamPark community for their strong support during the use of StreamPark + Paimon. The problems encountered in the learning process are promptly clarified and resolved. We will also actively participate in community exchanges and contributions in the future, enabling Paimon to provide more developers and enterprises with integrated stream and batch data lake solutions.