Summary: The author of this article, "StreamPark: An All-in-One Computation Tool in Haibo Tech's Production Practice and facilitation in Smart City Construction," is the Big Data Architect at Haibo Tech. The main topics covered include:
- Choosing StreamPark
- Getting Started Quickly
- Application Scenarios
- Feature Extensions
- Future Expectations
Haibo Tech is an industry-leading company offering AI IoT products and solutions. Currently, they provide full-stack solutions, including algorithms, software, and hardware products, to clients nationwide in public safety, smart cities, and smart manufacturing domains.
01. Choosing Apache StreamPark™
Haibo Tech started using Flink SQL to aggregate and process various real-time IoT data since 2020. With the accelerated pace of smart city construction in various cities, the types and volume of IoT data to be aggregated are also increasing. This has resulted in an increasing number of Flink SQL tasks being maintained online, making a dedicated platform for managing numerous Flink SQL tasks an urgent need.
After evaluating Apache Zeppelin and StreamPark, we chose StreamPark as our real-time computing platform. Compared to Apache Zeppelin, StreamPark may not be as well-known. However, after experiencing the initial release of StreamPark and reading its design documentation, we recognized that its all-in-one design philosophy covers the entire lifecycle of Flink task development. This means that configuration, development, deployment, and operations can all be accomplished on a single platform. Our developers, operators, and testers can collaboratively work on StreamPark. The low-code + all-in-one design principles solidified our confidence in using StreamPark.
// Video link (streampark official video)
02. Practical Implementation
1. Quick Start
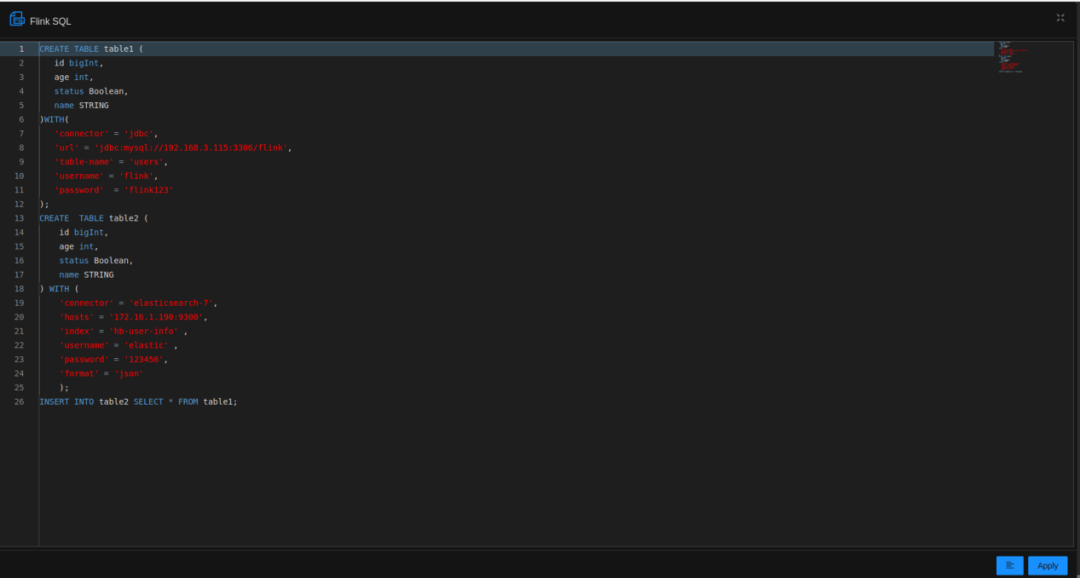
Using StreamPark to accomplish a real-time aggregation task is as simple as putting an elephant into a fridge, and it can be done in just three steps:
- Edit SQL
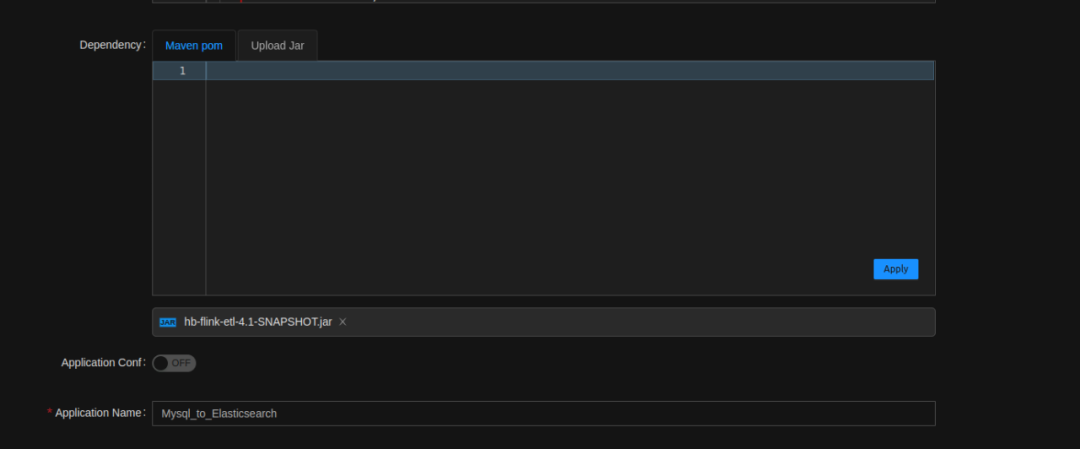
- Upload dependency packages
- Deploy and run
With just the above three steps, you can complete the aggregation task from Mysql to Elasticsearch, significantly improving data access efficiency.
2. Production Practice
StreamPark is primarily used at Haibo for running real-time Flink SQL tasks: reading data from Kafka, processing it, and outputting to Clickhouse or Elasticsearch.
Starting from October 2021, the company gradually migrated Flink SQL tasks to the StreamPark platform for centralized management. It supports the aggregation, computation, and alerting of our real-time IoT data.
As of now, StreamPark has been deployed in various government and public security production environments, aggregating and processing real-time IoT data, as well as capturing data on people and vehicles. Below is a screenshot of the StreamPark platform deployed on a city's dedicated network:
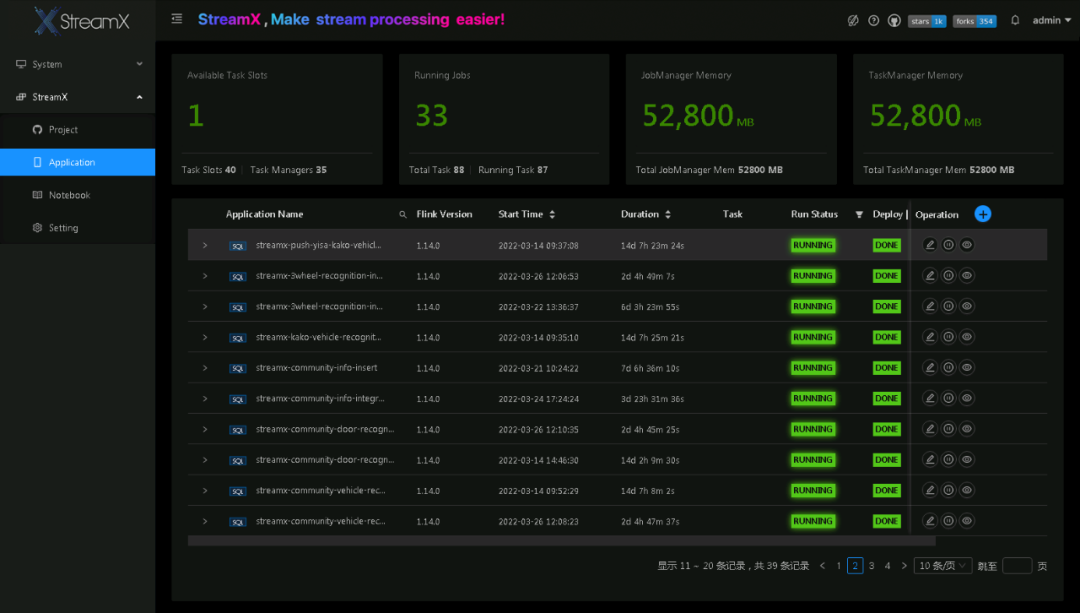
03. Application Scenarios
1. Real-time IoT Sensing Data Aggregation
For aggregating real-time IoT sensing data, we directly use StreamPark to develop Flink SQL tasks. For methods not provided by Flink SQL, StreamPark also supports UDF-related functionalities. Users can upload UDF packages through StreamPark, and then call the relevant UDF in SQL to achieve more complex logical operations.
The "SQL+UDF" approach meets most of our data aggregation scenarios. If business changes in the future, we only need to modify the SQL statement in StreamPark to complete business changes and deployment.

2. Flink CDC Database Synchronization
To achieve synchronization between various databases and data warehouses, we use StreamPark to develop Flink CDC SQL tasks. With the capabilities of Flink CDC, we've implemented data synchronization between Oracle and Oracle, as well as synchronization between Mysql/Postgresql and Clickhouse.
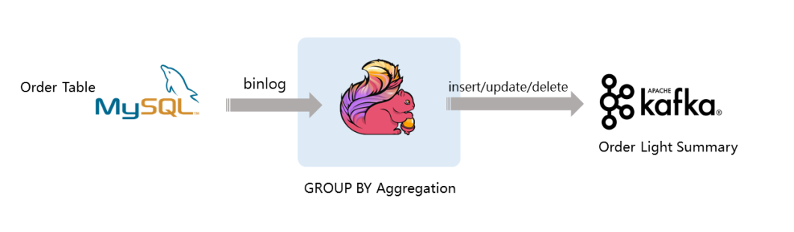
3. Data Analysis Model Management
For tasks that can't use Flink SQL and need Flink code development, such as real-time control models and offline data analysis models, StreamPark offers a Custom code approach, allowing users to upload executable Flink Jar packages and run them.
Currently, we have uploaded over 20 analysis models, such as personnel and vehicles, to StreamPark, which manages and operates them.
In Summary: Whether it's Flink SQL tasks or Custom code tasks, StreamPark provides excellent support to meet various business scenarios. However, StreamPark lacks task scheduling capabilities. If you need to schedule tasks regularly, StreamPark currently cannot meet this need. Community members are actively developing scheduling-related modules, and the soon-to-be-released version 1.2.3 will support task scheduling capabilities, so stay tuned.
04. Feature Extension
Datahub is a metadata management platform developed by Linkedin, offering data source management, data lineage, data quality checks, and more. Haibo Tech has developed an extension based on StreamPark and Datahub, implementing table-level/field-level lineage features. With the data lineage feature, users can check the field lineage relationship of Flink SQL and save the lineage relationship to the Linkedin/Datahub metadata management platform.
// Two video links (Data lineage feature developed based on streampark)
05. Future Expectations
Currently, the StreamPark community's Roadmap indicates that StreamPark 1.3.0 will usher in a brand new Workbench experience, a unified resource management center (unified management of JAR/UDF/Connectors), batch task scheduling, and more. These are also some of the brand-new features we are eagerly anticipating.
The Workbench will use a new workbench-style SQL development style. By selecting a data source, SQL can be generated automatically, further enhancing Flink task development efficiency. The unified UDF resource center will solve the current problem where each task has to upload its dependency package. The batch task scheduling feature will address StreamPark's current inability to schedule tasks.
Below is a prototype designed by StreamPark developers, so please stay tuned.