Abstract: This article is compiled from the sharing of Mu Chunjin, the head of China Union Data Science's real-time computing team and Apache StreamPark Committer, at the Flink Forward Asia 2022 platform construction session. The content of this article is mainly divided into four parts:
- Introduction to the Real-Time Computing Platform Background
- Operational Challenges of Flink Real-Time Jobs
- Integrated Management Based on StreamPark
- Future Planning and Evolution
Introduction to the Real-Time Computing Platform Background
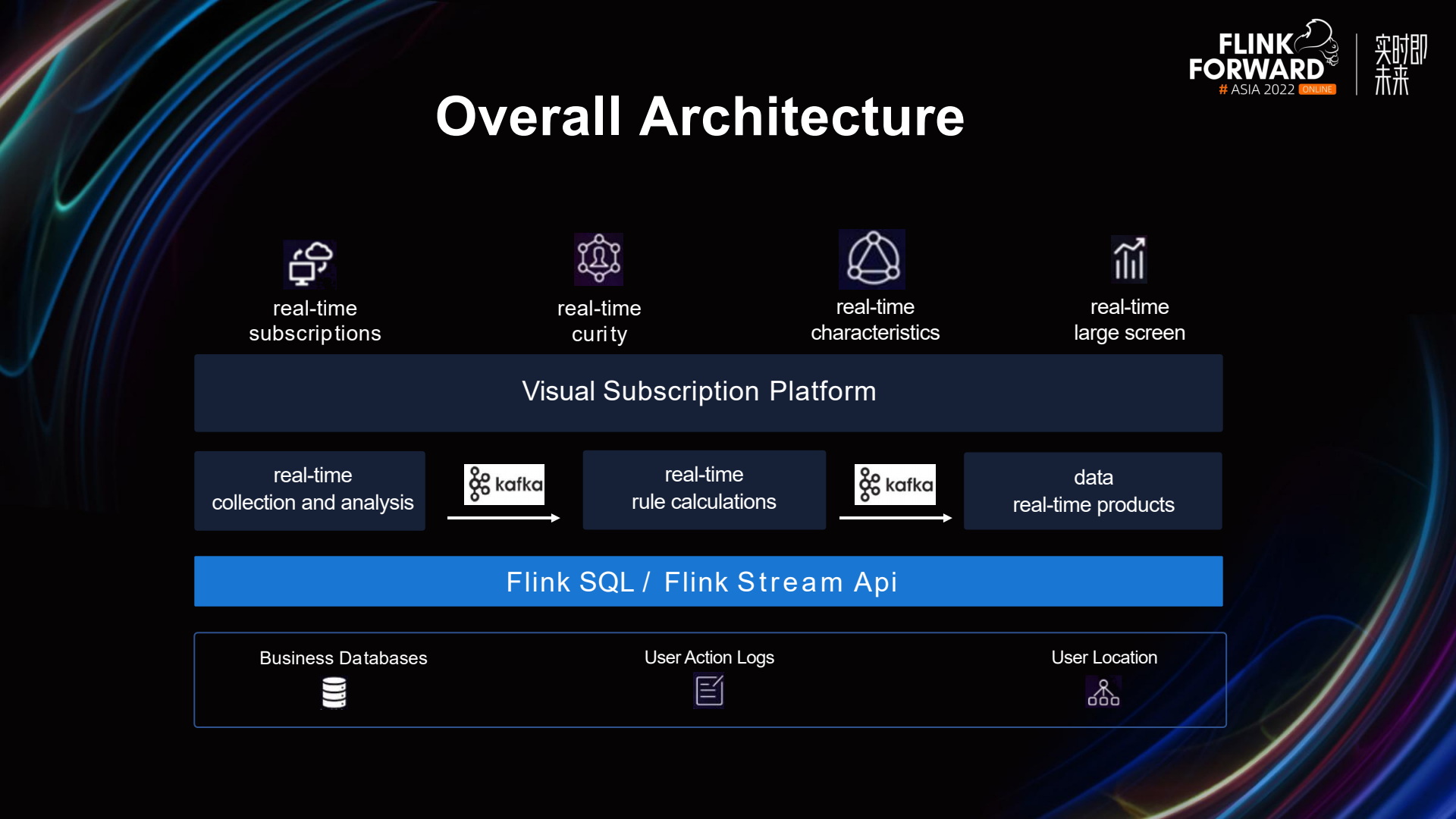
The image above depicts the overall architecture of the real-time computing platform. At the bottom layer, we have the data sources. Due to some sensitive information, the detailed information of the data sources is not listed. It mainly includes three parts: business databases, user behavior logs, and user location. China Union has a vast number of data sources, with just the business databases comprising tens of thousands of tables. The data is primarily processed through Flink SQL and the DataStream API. The data processing workflow includes real-time parsing of data sources by Flink, real-time computation of rules, and real-time products. Users perform real-time data subscriptions on the visualization subscription platform. They can draw an electronic fence on the map and set some rules, such as where the data comes from, how long it stays inside the fence, etc. They can also filter some features. User information that meets these rules will be pushed in real-time. Next is the real-time security part. If a user connects to a high-risk base station or exhibits abnormal operational behavior, we may suspect fraudulent activity and take actions such as shutting down the phone number, among other things. Additionally, there are some real-time features of users and a real-time big screen display.
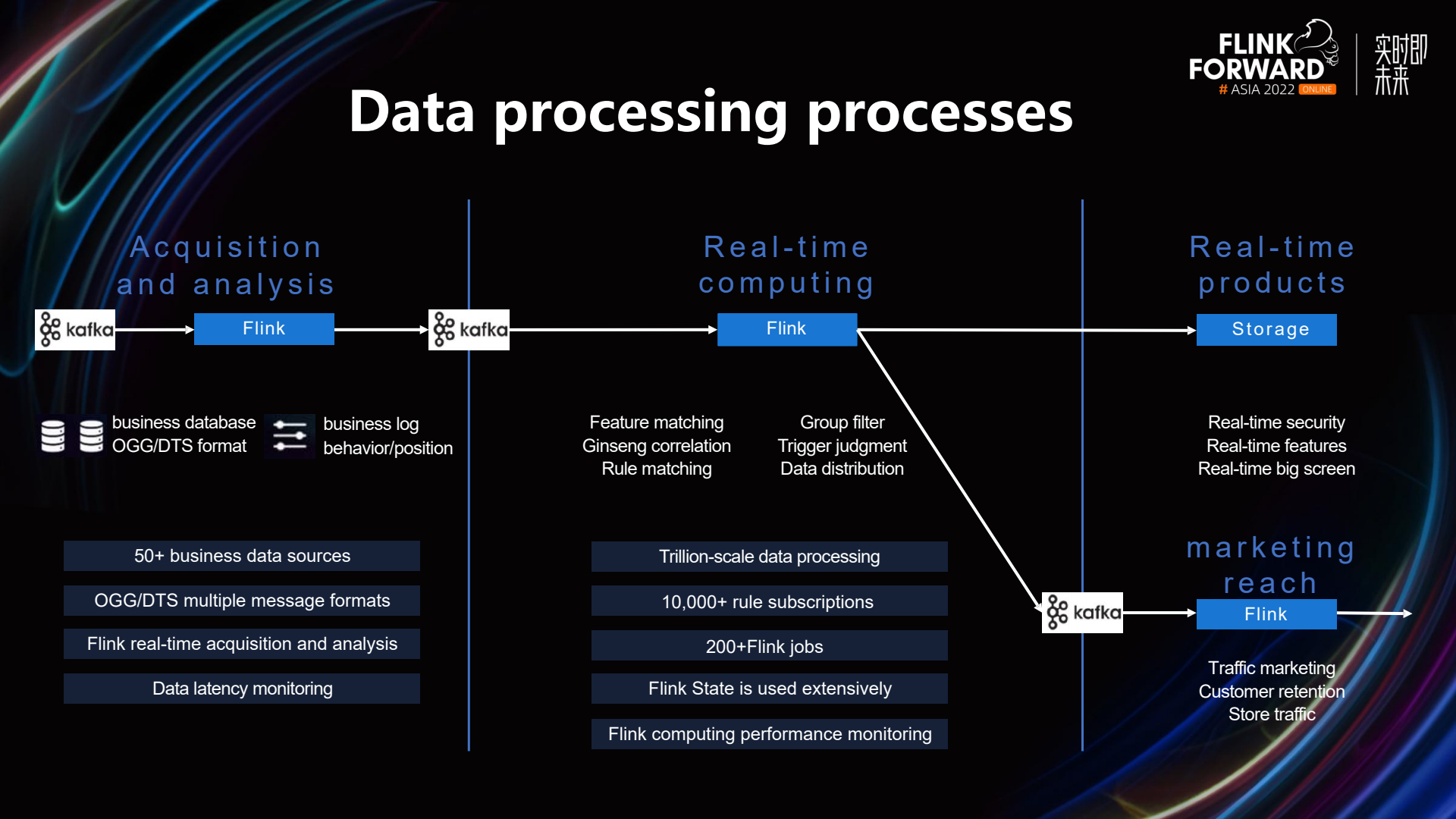
The image above provides a detailed workflow of data processing.
The first part is collection and parsing. Our data sources come from business databases, including OGG and DTS format messages, log messages, user behavior, and user location data, totaling over 50 different data sources. This number is expected to gradually increase. All data sources are processed in real-time using Flink, and Metrics have been added to monitor the latency of data sources.
The second part is real-time computing. This stage deals with a massive amount of data, in the trillions, supporting over 10,000 real-time data subscriptions. There are more than 200 Flink tasks. We encapsulate a certain type of business into a scenario, and a single Flink job can support multiple subscriptions in the same scenario. Currently, the number of Flink jobs is continuously increasing, and in the future, it might increase to over 500. One of the major challenges faced here is the real-time association of trillion-level data with electronic fences and user features on a daily basis. There are tens of thousands of electronic fences, and user features involve hundreds of millions of users. Initially, we stored electronic fence information and user features in HBase, but this led to significant pressure on HBase, frequent performance issues, and data latency. Furthermore, once data backlog occurred, it took a long time to clear. Thanks to the powerful Flink State, we have now stored the electronic fence information and user features in the state, which has adequately supported high-concurrency scenarios. We have also added performance monitoring for data processing. Finally, there are some applications for real-time products and marketing touchpoints on the front end.
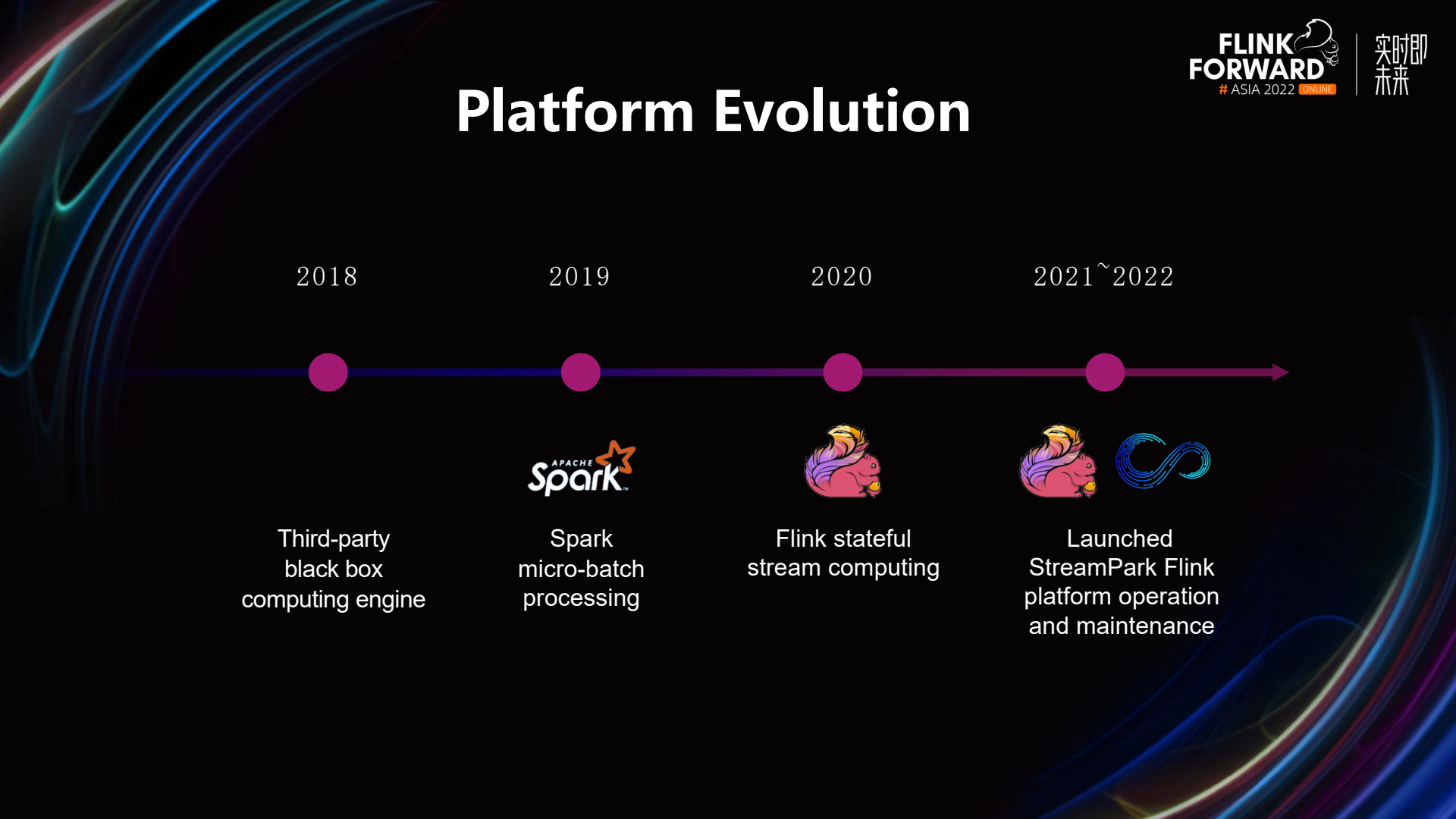
In 2018, we adopted a third-party black-box computing engine, which did not support flexible customization of personalized functions, and depended heavily on external systems, resulting in high loads on these external systems and complex operations and maintenance. In 2019, we utilized Spark Streaming's micro-batch processing. From 2020, we began to use Flink for stream computing. Starting from 2021, almost all Spark Streaming micro-batch processing tasks have been replaced by Flink. At the same time, Apache StreamPark was launched to manage our Flink jobs.

To summarize the platform background, it mainly includes the following parts:
- Large data volume: processing an average of trillions of data per day.
- Numerous data sources: integrated with more than 50 types of real-time data sources.
- Numerous subscriptions: supported more than 10,000 data service subscriptions.
- Numerous users: supported the usage of more than 30 internal and external users.

The operational maintenance background can also be divided into the following parts:
- High support demand: More than 50 types of data sources, and over 10,000 data service subscriptions.
- Numerous real-time jobs: Currently, there are 200+ Flink production jobs, and the number is continuously and rapidly increasing, potentially reaching 500+ in the future.
- High frequency of launches: There are new or enhanced Flink jobs going live every day.
- Numerous developers: Over 50 R&D personnel are involved in developing Flink real-time computing tasks.
- Numerous users: Over 30 internal and external organizations' users are utilizing the platform.
- Low monitoring latency: Once an issue is identified, we must address it immediately to avoid user complaints.
Flink Real-Time Job Operation and Maintenance Challenges
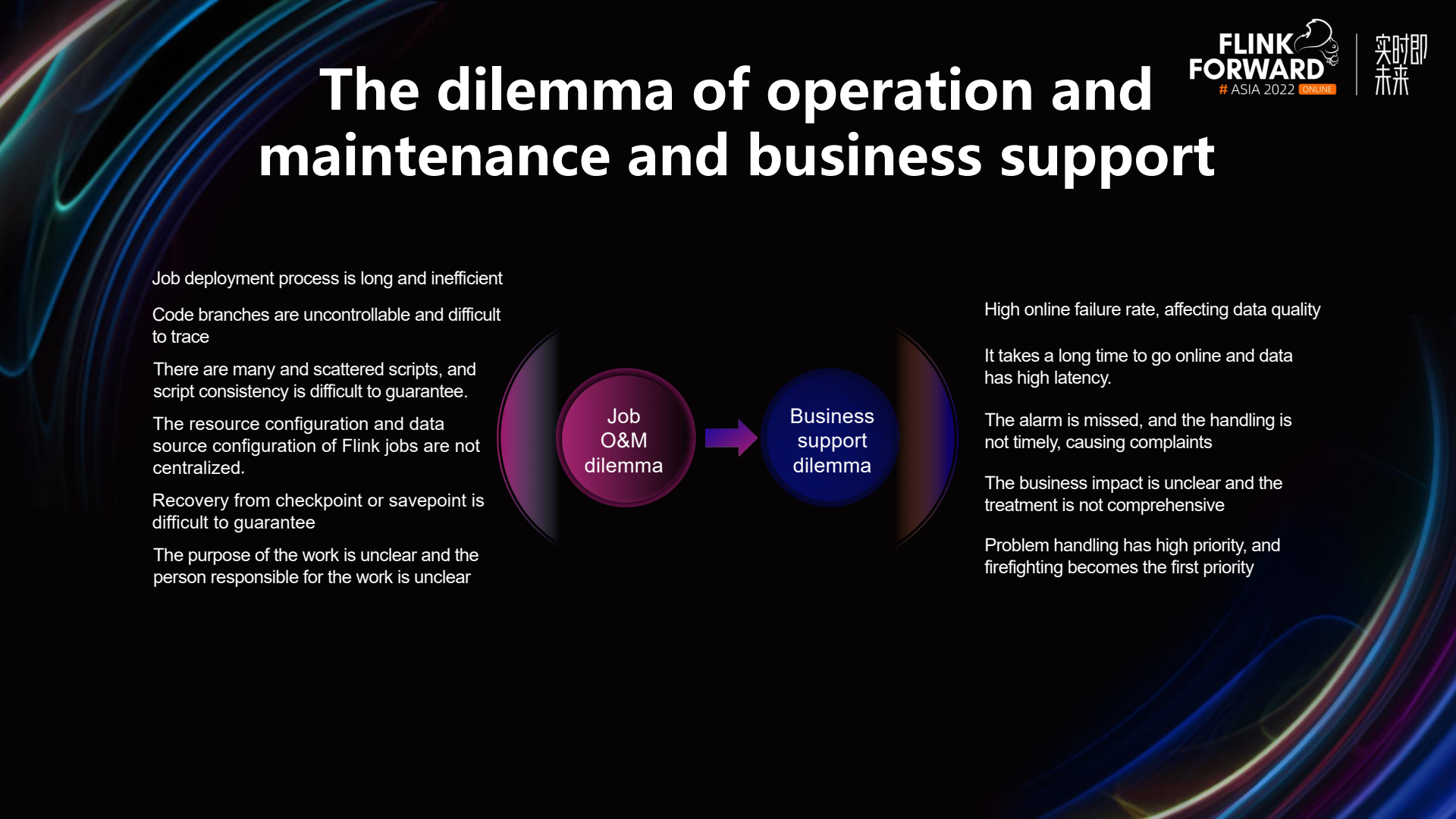
Given the platform and operational maintenance background, particularly with the increasing number of Flink jobs, we have encountered significant challenges in two main areas: job operation and maintenance dilemmas, and business support difficulties.
In terms of job operation and maintenance dilemmas, firstly, the job deployment process is lengthy and inefficient. Under China Union's principle that security is the top priority, deploying programs on servers involves connecting to a VPN, logging in through the 4A system, packaging and compiling, deploying, and then starting the program. This entire process is quite long. Initially, when developing Flink, we started jobs using scripts, leading to uncontrollable code branches. After deployment, it was also difficult to trace back. Moreover, it's challenging to synchronize scripts with code on git because developers tend to prefer directly modifying scripts on the server, easily forgetting to upload changes to git.
Due to various factors in the job operation and maintenance difficulties, business support challenges arise, such as a high rate of failures during launch, impact on data quality, lengthy launch times, high data latency, and issues with missed alarm handling, leading to complaints. In addition, the impact on our business is unclear, and once a problem arises, addressing the issue becomes the top priority.
Integrated Management based on Apache StreamPark™
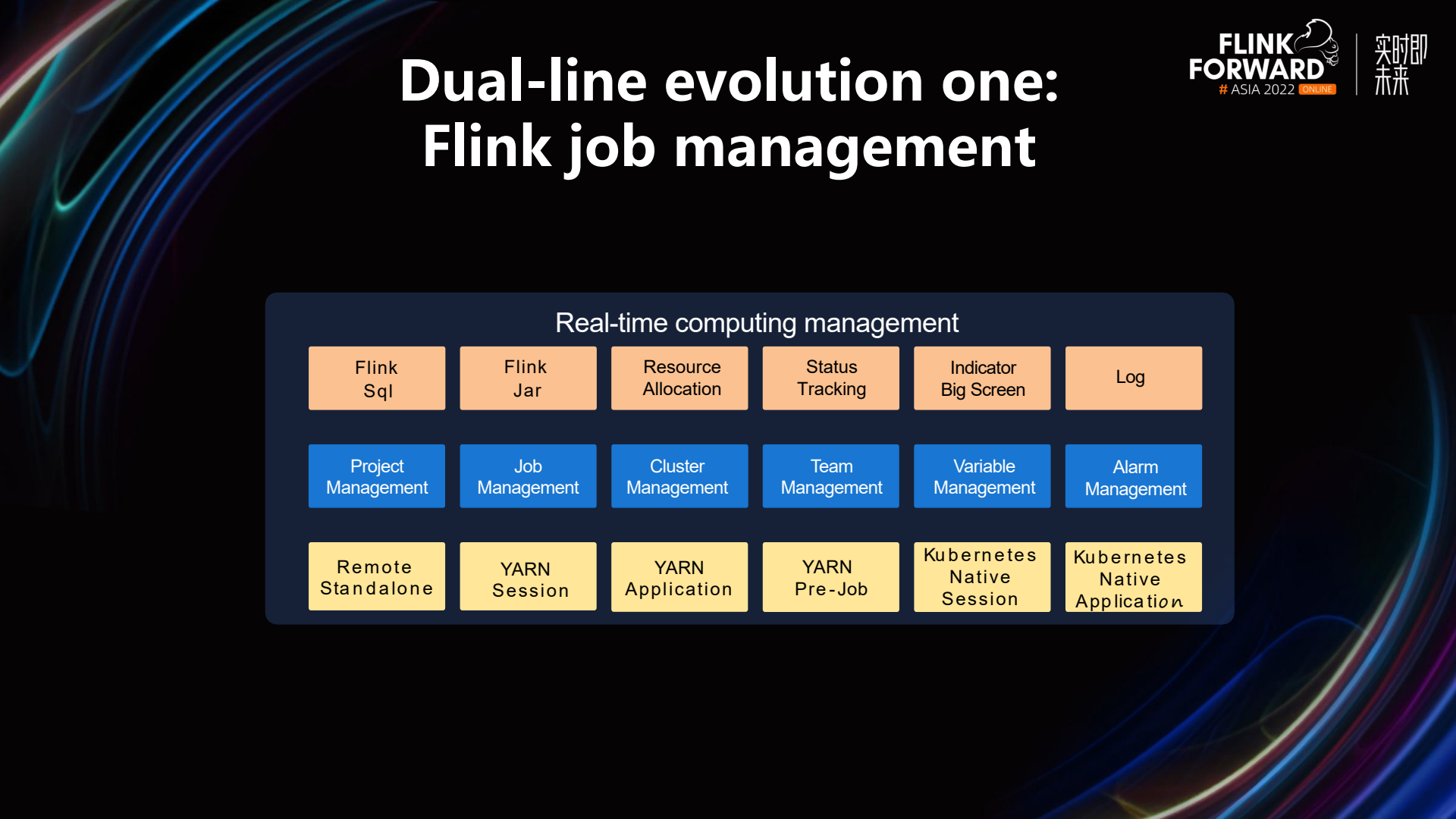
In response to the two dilemmas mentioned above, we have resolved many issues through StreamPark's integrated management. First, let's take a look at the dual evolution of StreamPark, which includes Flink Job Management and Flink Job DevOps Platform. In terms of job management, StreamPark supports deploying Flink real-time jobs to different clusters, such as Flink's native Standalone mode, and the Session, Application, and PerJob modes of Flink on Yarn. In the latest version, it will support Kubernetes Native Session mode. The middle layer includes project management, job management, cluster management, team management, variable management, and alarm management.
- Project Management: When deploying a Flink program, you can fill in the git address in project management and select the branch you want to deploy.
- Job Management: You can specify the execution mode of the Flink job, such as which type of cluster you want to submit to. You can also configure some resources, such as the number of TaskManagers, the memory size of TaskManager/JobManager, parallelism, etc. Additionally, you can set up some fault tolerance measures; for instance, if a Flink job fails, StreamPark can support automatic restarts, and it also supports the input of some dynamic parameters.
- Cluster Management: You can add and manage big data clusters through the interface.
- Team Management: In the actual production process of an enterprise, there are multiple teams, and these teams are isolated from each other.
- Variable Management: You can maintain some variables in one place. For example, you can define Kafka's Broker address as a variable. When configuring Flink jobs or SQL, you can replace the Broker's IP with a variable. Moreover, if this Kafka needs to be decommissioned later, you can also use this variable to check which jobs are using this cluster, facilitating some subsequent processes.
- Alarm Management: Supports multiple alarm modes, such as WeChat, DingTalk, SMS, and email.
StreamPark supports the submission of Flink SQL and Flink Jar, allows for resource configuration, and supports state tracking, indicating whether the state is running, failed, etc. Additionally, it provides a metrics dashboard and supports the viewing of various logs.
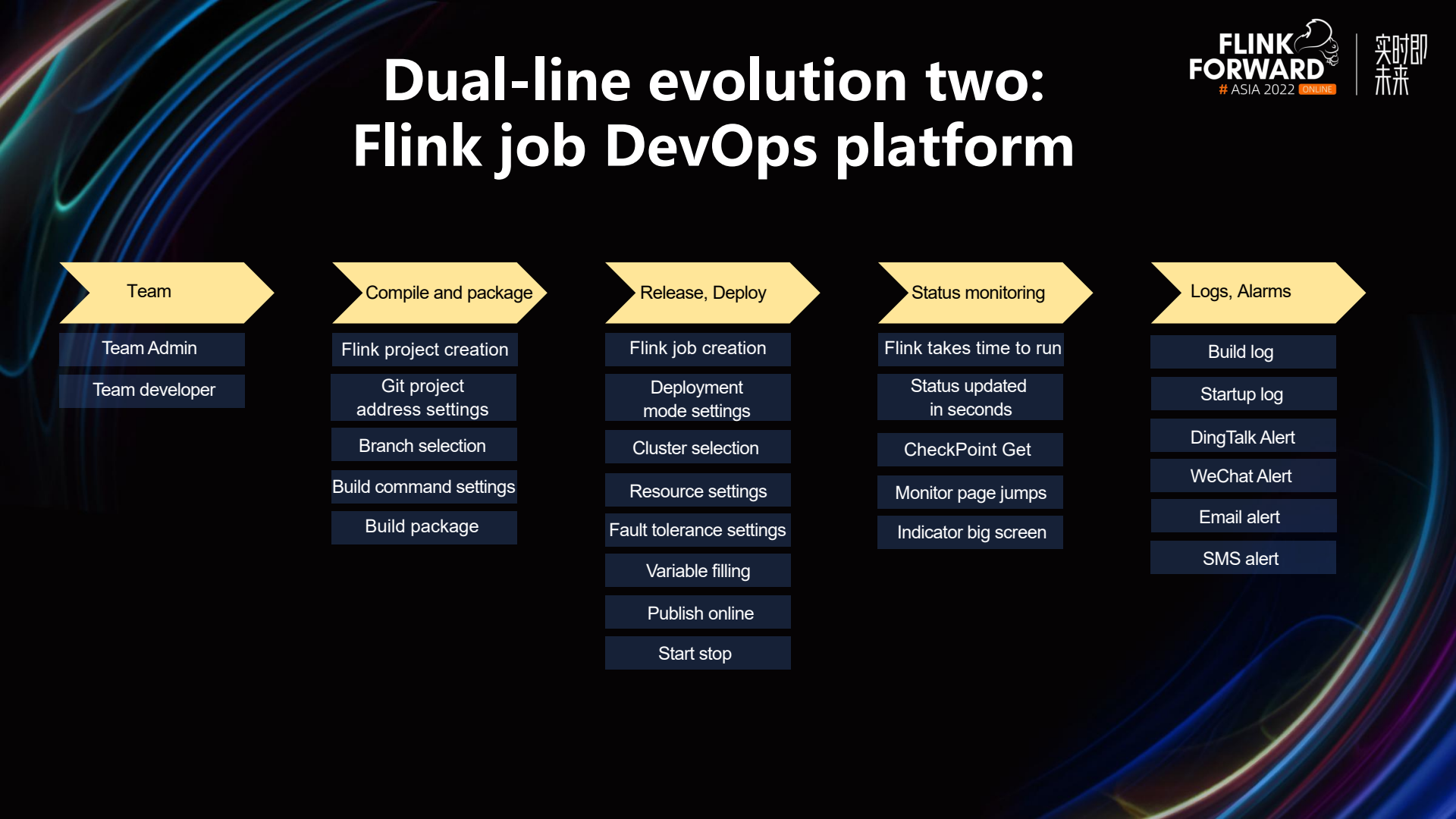
The Flink Job DevOps platform primarily consists of the following parts:
- Teams: StreamPark supports multiple teams, each with its team administrator who has all permissions. There are also team developers who only have a limited set of permissions.
- Compilation and Packaging: When creating a Flink project, you can configure the git address, branch, and packaging commands in the project, and then compile and package with a single click of the build button.
- Release and Deployment: During release and deployment, a Flink job is created. Within the Flink job, you can choose the execution mode, deployment cluster, resource settings, fault tolerance settings, and fill in variables. Finally, the Flink job can be started or stopped with a single click.
- State Monitoring: After the Flink job is started, real-time tracking of its state begins, including Flink's running status, runtime duration, Checkpoint information, etc. There is also support for one-click redirection to Flink's Web UI.
- Logs and Alerts: This includes logs from the build and start-up processes and supports alerting methods such as DingTalk, WeChat, email, and SMS.

Companies generally have multiple teams working on real-time jobs simultaneously. In our company, this includes a real-time data collection team, a data processing team, and a real-time marketing team. StreamPark supports resource isolation for multiple teams.
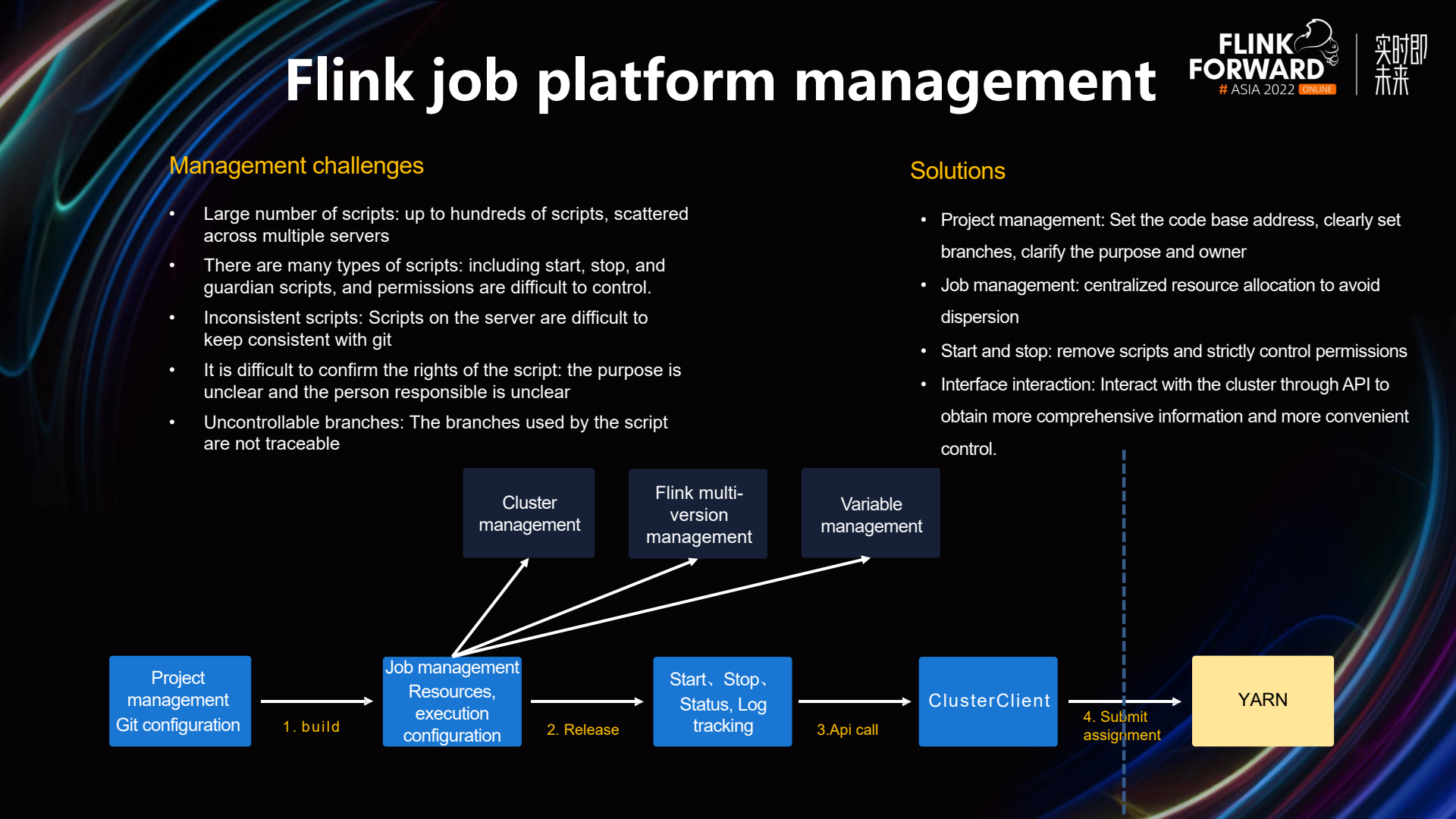
Management of the Flink job platform faces the following challenges:
- Numerous scripts: There are several hundred scripts on the platform, scattered across multiple servers.
- Various types of scripts: When starting Flink jobs, there are start scripts, stop scripts, and daemon scripts, and it is very difficult to control operation permissions.
- Inconsistent scripts: The scripts on the server are inconsistent with the scripts on git.
- Difficult to ascertain script ownership: It is unclear who is responsible for the Flink jobs and their purpose.
- Uncontrollable branches: When starting a job, you need to specify the git branch in the script, resulting in untraceable branches.
Based on the challenges mentioned above, StreamPark has addressed the issues of unclear ownership and untraceable branches through project management. This is because when creating a project, you need to manually specify certain branches. Once the packaging is successful, these branches are recorded. Job management centralizes configurations, preventing scripts from being too dispersed. Additionally, there is strict control over the permissions for starting and stopping jobs, preventing an uncontrollable state due to script permissions. StreamPark interacts with clusters through interfaces to obtain job information, allowing for more precise job control.
Referring to the image above, you can see at the bottom of the diagram that packaging is conducted through project management, configuration is done via job management, and then it is released. This process allows for one-click start and stop operations, and jobs can be submitted through the API.

In the early stages, we needed to go through seven steps for deployment, including connecting to a VPN, logging in through 4A, executing compile scripts, executing start scripts, opening Yarn, searching for the job name, and entering the Flink UI. StreamPark supports one-click deployment for four of these steps, including one-click packaging, one-click release, one-click start, and one-click access to the Flink UI.
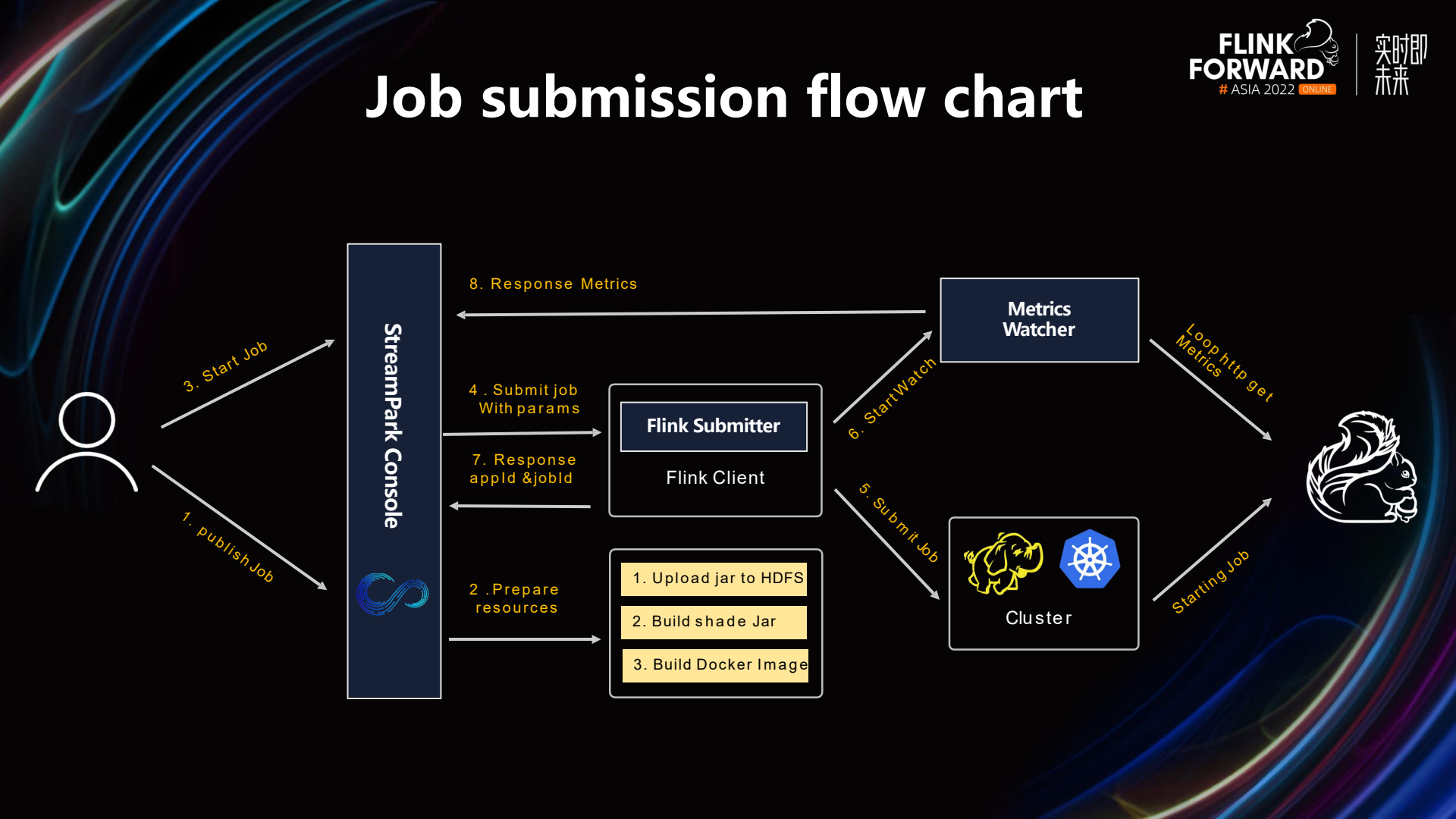
The image above illustrates the job submission process of our StreamPark platform. Firstly, StreamPark proceeds to release the job, during which some resources are uploaded. Following that, the job is submitted, accompanied by various configured parameters, and it is published to the cluster using the Flink Submit method via an API call. At this point, there are multiple Flink Submit instances corresponding to different execution modes, such as Yarn Session, Yarn Application, Kubernetes Session, Kubernetes Application, and so on; all of these are controlled here. After submitting the job, if it is a Flink on Yarn job, the platform will acquire the Application ID or Job ID of the Flink job. This ID is then stored in our database. Similarly, if the job is executed based on Kubernetes, a Job ID will be obtained. Subsequently, when tracking the job status, we primarily use these stored IDs to monitor the state of the job.
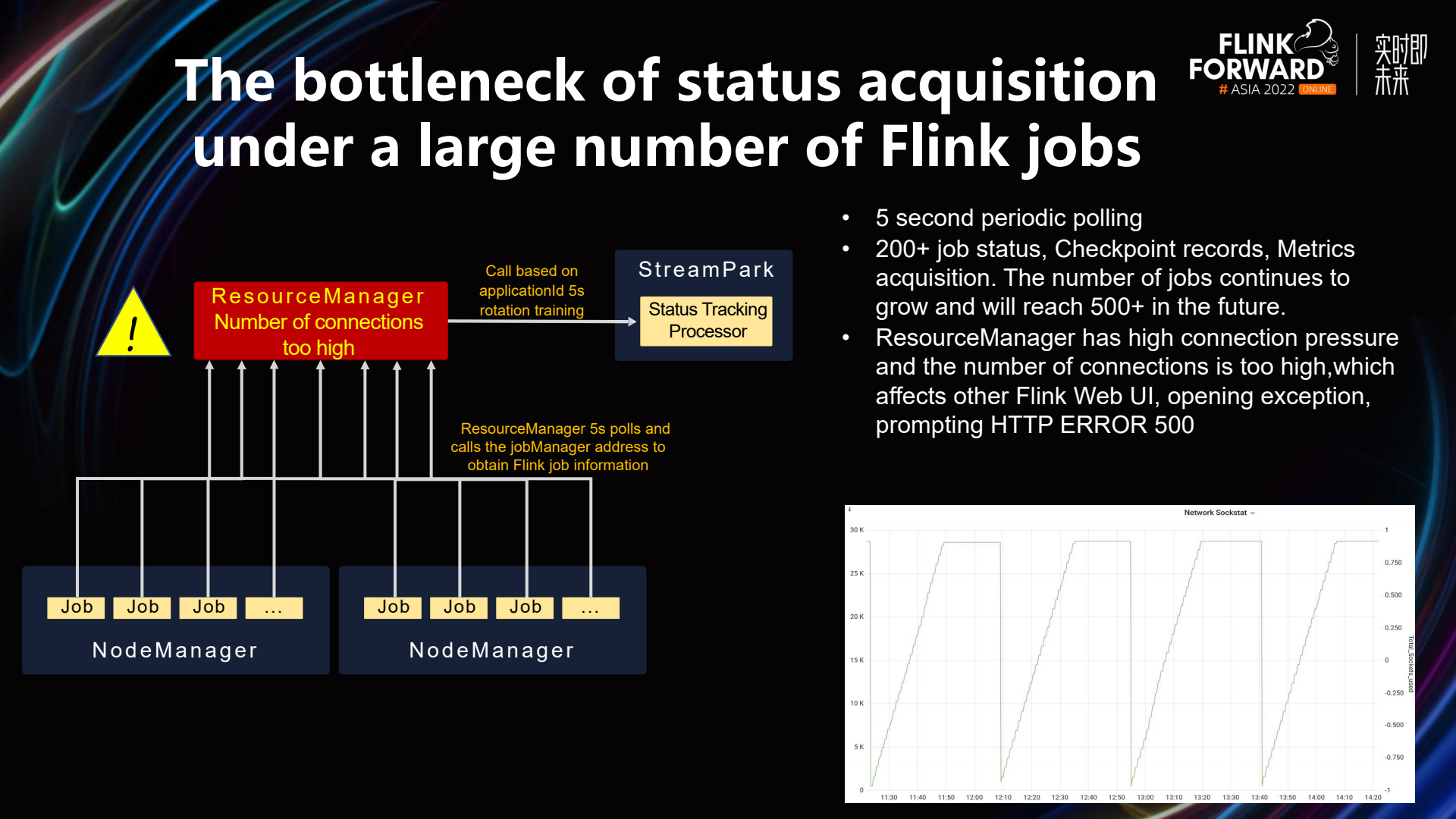
As mentioned above, in the case of Flink on Yarn jobs, two IDs are acquired upon job submission: the Application ID and the Job ID. These IDs are used to retrieve the job status. However, when there is a large number of Flink jobs, certain issues may arise. StreamPark utilizes a status retriever that periodically sends requests to the ResourceManager every five seconds, using the Application ID or Job ID stored in our database. If there are a considerable number of jobs, during each polling cycle, the ResourceManager is responsible for calling the Job Manager's address to access its status. This can lead to significant pressure on the number of connections to the ResourceManager and an overall increase in the number of connections.
In the diagram mentioned earlier, the connection count to the ResourceManager shows periodic and sustained increases, indicating that the ResourceManager is in a relatively critical state. This is evidenced by monitoring data from the server, which indeed shows a higher number of connections to the ResourceManager.
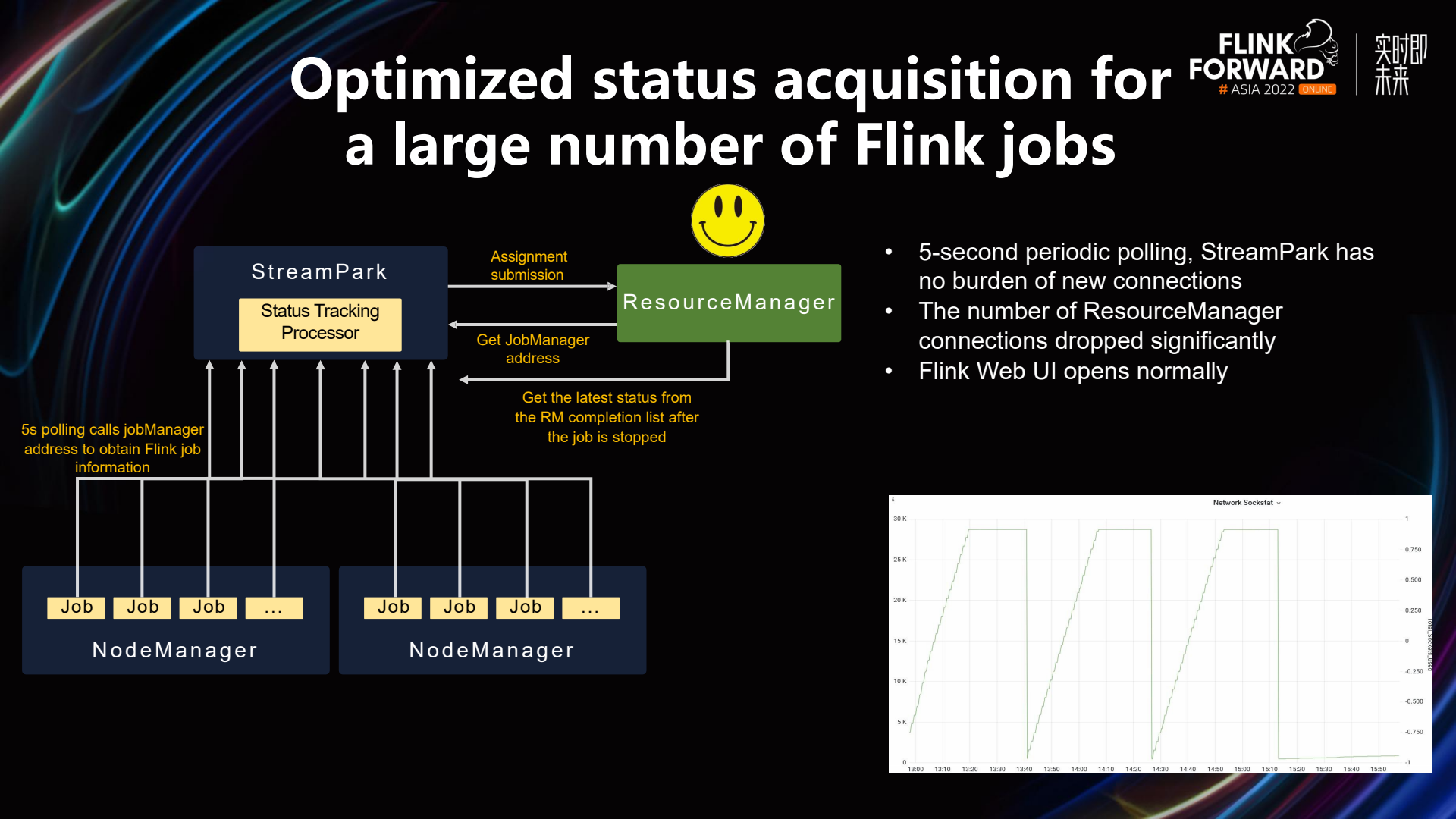
To address the issues mentioned above, we have made some optimizations in StreamPark. Firstly, after submitting a job, StreamPark saves the Application ID or Job ID, and it also retrieves and stores the direct access address of the Job Manager in the database. Therefore, instead of polling the ResourceManager for job status, it can directly call the addresses of individual Job Managers to obtain the real-time status. This significantly reduces the number of connections to the ResourceManager. As can be seen from the latter part of the diagram above, there are basically no significant spikes in connection counts, which substantially alleviates the pressure on the ResourceManager. Moreover, this ensures that as the number of Flink jobs continues to grow, the system will not encounter bottlenecks in status retrieval.
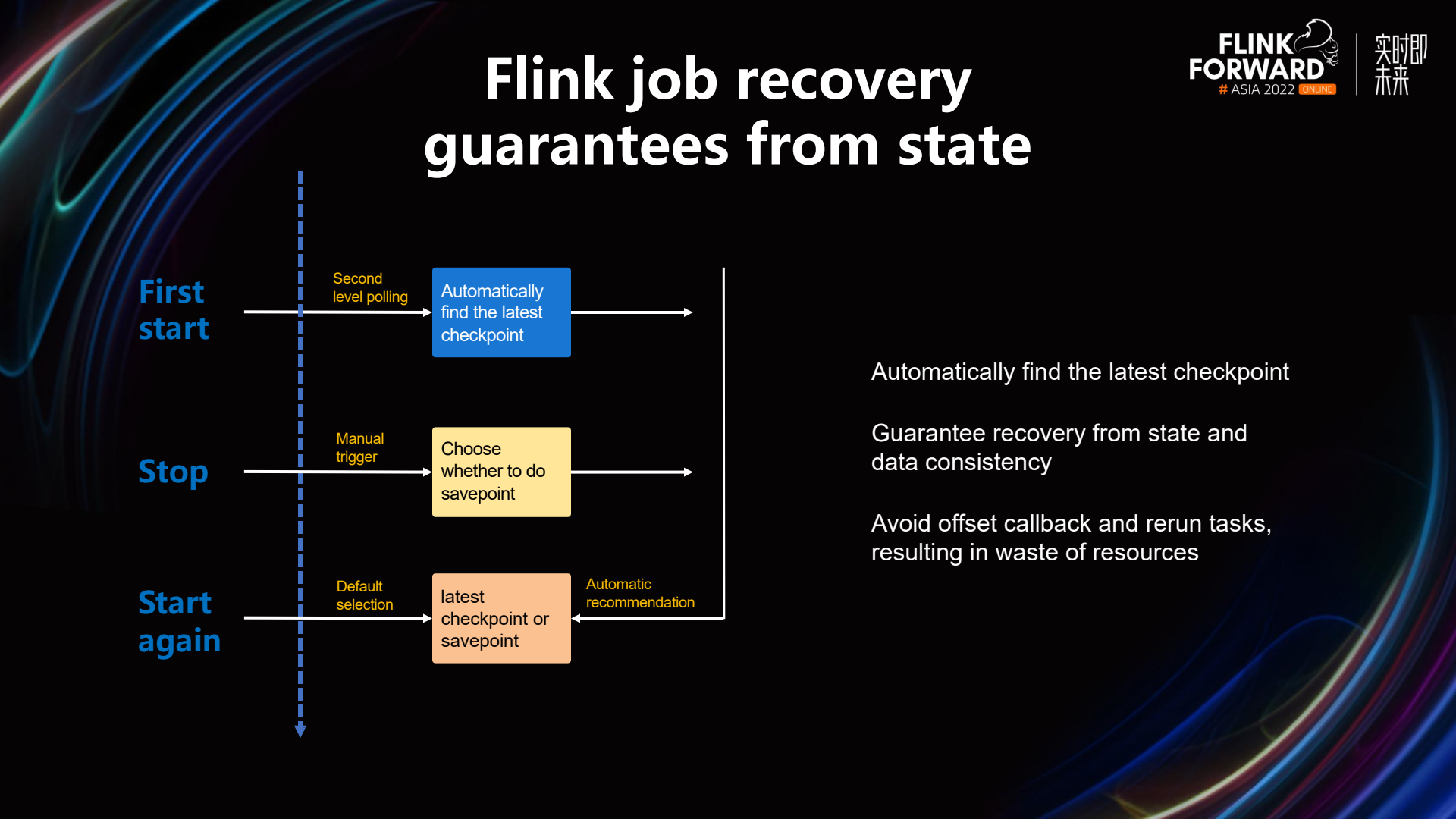
Another issue that StreamPark resolves is safeguarding Flink's state recovery. In the past, when we used scripts for operations and maintenance, especially during business upgrades, it was necessary to recover from the latest checkpoint when starting Flink. However, developers often forgot to recover from the previous checkpoint, leading to significant data quality issues and complaints. StreamPark's process is designed to mitigate this issue. Upon the initial start of a Flink job, it polls every five seconds to retrieve checkpoint records, saving them in a database. When manually stopping a Flink job through StreamPark, users have the option to perform a savepoint. If this option is selected, the path of the savepoint is saved in the database. In addition, records of each checkpoint are also stored in the database. When restarting a Flink job, the system defaults to using the latest checkpoint or savepoint record. This effectively prevents issues associated with failing to recover from the previous checkpoint. It also avoids the resource wastage caused by having to rerun jobs with offset rollbacks to address problems, while ensuring consistency in data processing.
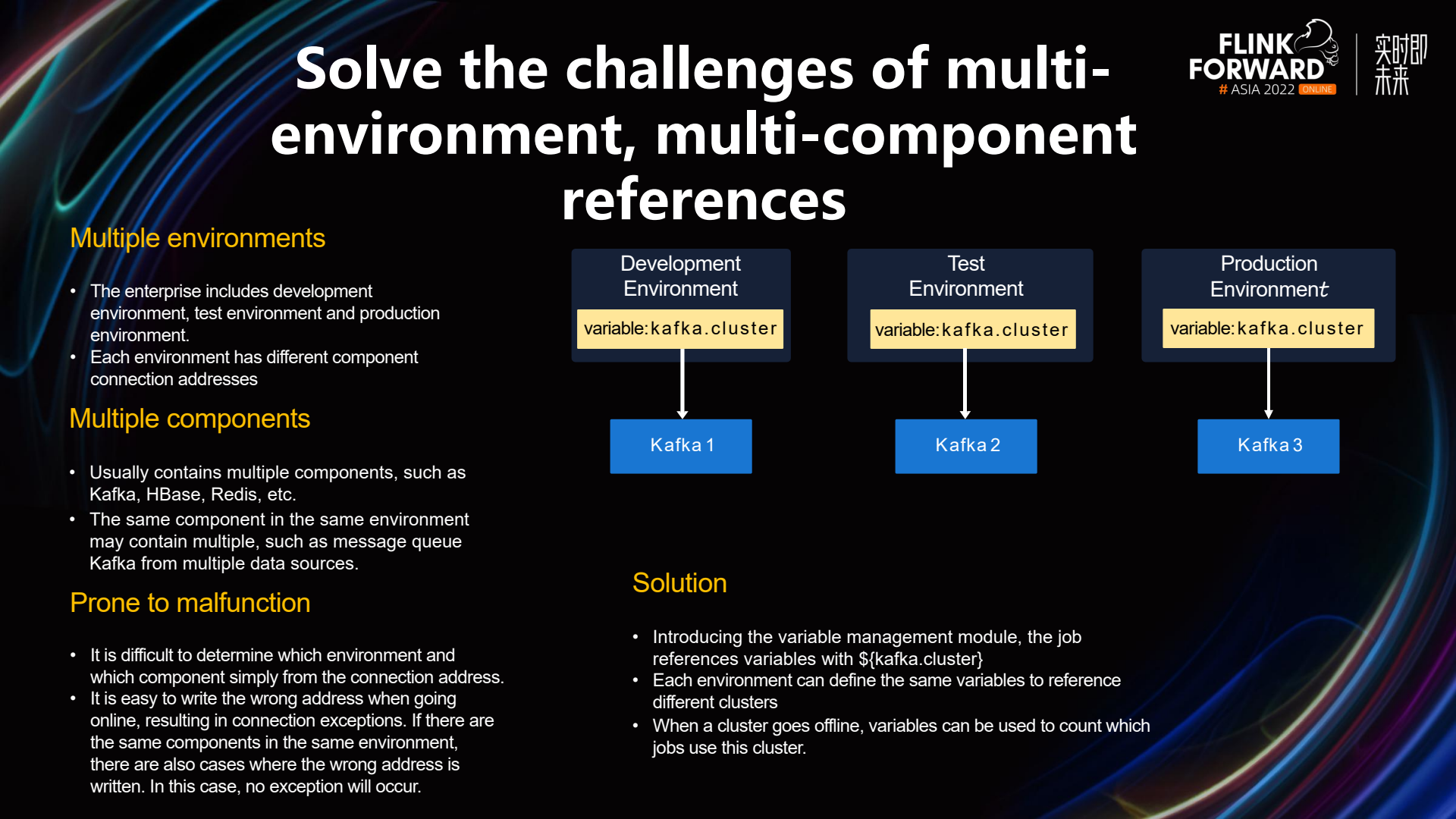
StreamPark also addresses the challenges associated with referencing multiple components across various environments. In a corporate setting, there are typically multiple environments, such as development, testing, and production. Each environment generally includes multiple components, such as Kafka, HBase, Redis, etc. Additionally, within a single environment, there may be multiple instances of the same component. For example, in a real-time computing platform at China Union, when consuming data from an upstream Kafka cluster and writing the relevant data to a downstream Kafka cluster, two sets of Kafka are involved within the same environment. It can be challenging to determine the specific environment and component based solely on IP addresses. To address this, we define the IP addresses of all components as variables. For instance, the Kafka cluster variable, Kafka.cluster, exists in development, testing, and production environments, but it points to different Broker addresses in each. Thus, regardless of the environment in which a Flink job is configured, referencing this variable is sufficient. This approach significantly reduces the incidence of operational failures in production environments.

StreamPark supports multiple execution modes for Flink, including three deployment modes based on Yarn: Application, Perjob, and Session. Additionally, it supports two deployment modes for Kubernetes: Application and Session, as well as some Remote modes.

StreamPark also supports multiple versions of Flink. For example, while our current version is 1.14.x, we would like to experiment with the new 1.16.x release. However, it’s not feasible to upgrade all existing jobs to 1.16.x. Instead, we can opt to upgrade only the new jobs to 1.16.x, allowing us to leverage the benefits of the new version while maintaining compatibility with the older version.
Future Planning and Evolution

In the future, we will increase our involvement in the development of StreamPark, and we have planned the following directions for enhancement:
- High Availability: StreamPark currently does not support high availability, and this aspect needs further strengthening.
- State Management: In enterprise practices, each operator in a Flink job has a UID. If the Flink UID is not set, it could lead to situations where state recovery is not possible when upgrading the Flink job. This issue cannot be solved through the platform at the moment. Therefore, we plan to add this functionality to the platform. We will introduce a feature that checks whether the operator has a UID set when submitting a Flink Jar. If not, a reminder will be issued to avoid state recovery issues every time a Flink job is deployed. Previously, when facing such situations, we had to use the state processing API to deserialize from the original state, and then create a new state using the state processing API for the upgraded Flink to load.
- More Detailed Monitoring: Currently, StreamPark supports sending alerts when a Flink job fails. We hope to also send alerts when a Task fails, and need to know the reason for the failure. In addition, enhancements are needed in job backpressure monitoring alerts, Checkpoint timeout alerts, failure alerts, and performance metric collection.
- Stream-Batch Integration: Explore a platform that integrates both streaming and batch processing, combining the Flink stream-batch unified engine with data lake storage that supports stream-batch unification.
The above diagram represents the Roadmap for StreamPark.
- Data Source: StreamPark will support rapid integration with more data sources, achieving one-click data onboarding.
- Operation Center: Acquire more Flink Metrics to further enhance the capabilities in monitoring and operation.
- K8S-operator: The existing Flink on K8S is somewhat cumbersome, having gone through the processes of packaging Jars, building images, and pushing images. There is a need for future improvements and optimization, and we are actively embracing the upstream K8S-operator integration.
- Streaming Data Warehouse: Enhance support for Flink SQL job capabilities, simplify the submission of Flink SQL jobs, and plan to integrate with Flink SQL Gateway. Enhance capabilities in the SQL data warehouse domain, including metadata storage, unified table creation syntax validation, runtime testing, and interactive queries, while actively embracing Flink upstream to explore real-time data warehouses and streaming data warehouses.