Introduction:Changan Automobile is one of the four major automobile cluster companies in China. With the advancement of business development and digital intelligence, the requirements for the effectiveness of data are getting higher and higher. There are more and more Flink operations. Changan Automobile originally developed a set of flow processes. The application platform is used to meet the basic needs of developers for Flink job management and operation and maintenance. However, it faces many challenges and dilemmas in actual use. In the end, Apache StreamPark was used as a one-stop real-time computing platform, which effectively solved the previous problems. Faced with many difficulties, the solution provided by StreamPark simplifies the entire development process, saves a lot of time in Flink job development and deployment, gets out of the quagmire of job operation and maintenance management, and significantly improves efficiency.
Contributor | Changan Intelligent Research Institute Cloud Platform Development Institute
Editing and proofreading|Pan Yuepeng
Chongqing Changan Automobile Co., Ltd. (referred to as "Changan Automobile") was established on October 31, 1996. It is an enterprise among the four major automobile groups in China and has a history of 161 years. It currently includes Changan Qiyuan, Deep Blue Automobile, Avita , Changan Gravity, Changan Kaicheng and other independent brands as well as Changan Ford, Changan Mazda and other joint venture brands.
In recent years, with the continuous increase in car sales and the continuous improvement of intelligence, vehicles will generate hundreds of billions of CAN data every day, and the cleaned and processed data is also at the level of 5 billion. Faced with such a huge and continuously expanding data scale, how to quickly extract and mine valuable information from massive data and provide data support for R&D, production, sales and other departments has become an urgent problem that needs to be solved.
1.Challenges of real-time computing
The storage and analysis processing of Changan Automobile data mainly consists of two parts: the upper cloud and the lower cloud. The upper cloud refers to the big data cluster we deployed on Tencent Cloud Server, which is built by CDH and is used to store hot data; the lower cloud is deployed on the Tencent Cloud Server. The CDP cluster in the local computer room pulls synchronized data from the cloud for storage and analysis.Flink has always played an important role in Changan Automobile's real-time computing, and Changan Automobile has developed a streaming application platform to meet the basic needs of developers for Flink job management and O&M。However, in actual use, the streaming application platform has the following four problems:
①Single function: It only provides deployment functions, without user rights management, team management, role management, and project management, which cannot meet the needs of project and team management.
②Lack of ease of use: SQL writing is silent, log browsing is inconvenient, debugging is not supported, no error detection, no version management, no configuration center, etc.
③Poor scalability: Online expansion of Flink clusters, new or replacement of Flink versions, and addition of Flink Connectors and CDC are not supported.
④Poor maintainability: No log viewing, no version management, no configuration center, etc.
2.Why use StreamPark
In view of the difficulties faced by Flink operations, we decided to seek solutions from the open source field first. Therefore, we comprehensively investigated open source projects such as Apache StreamPark, Dxxky, and strxxing-xx-web,from the core capabilities, stability, ease of use, scalability, maintainability, operation experience and other dimensions of a comprehensive evaluation and comparison, combined with our current streaming job development needs and our company's big data platform follow-up planning, we found that Apache StreamPark is the most in line with our current needs. That's why we adopted StreamPark as our streaming computing platform,StreamPark has the following advantages:
Perfect basic management capabilities
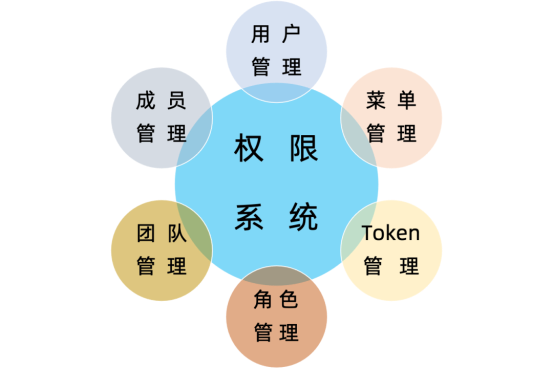
StreamPark solves the problems of our existing streaming application platform such as no user rights management, team management, role management, project management, team management, etc.
① The StreamPark platform provides user rights management capabilities. These features ensure that users only have access to the data and resources they need, and limit their modification rights to the system or job. This management capability is necessary for enterprise-level users because it helps protect the organization's data, maintain system stability, and ensure the smooth running of jobs. By properly setting and managing user permissions, organizations have more control over data access and operations, reducing risk and increasing productivity.
All-in-one streaming platform
StreamPark solves the problems of insufficient ease of use of the streaming application platform, such as no prompts for SQL writing, inconvenient log browsing, no error detection, no version management, and no configuration center.
① StreamPark has a complete SQL validation function, implements automatic build/push images, and uses custom classloaders,the Child-first loading mode solves the two running modes of YARN and K8s, and supports the free switching of Flink versions.
② StreamPark provides job monitoring and log management.It can help users monitor the running status of jobs in real time, view job log information, and perform troubleshooting.。This enables users to quickly find and resolve problems in job running.
Strong scalability
StreamPark solves problems such as poor scalability of the streaming application platform, inability to scale out Flink clusters online, add or replace Flink versions, and insufficient Flink connectors.
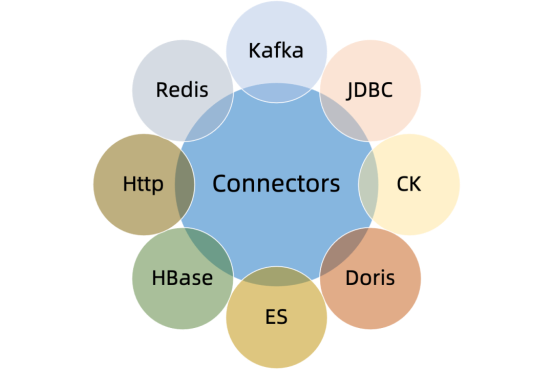
① StreamPark is designed to be scalable and flexible,can support large-scale Flink on Yarn job running, and can be seamlessly integrated with existing Yarn clusters,And can be customized and expanded as needed. In addition, StreamPark also provides a variety of configuration options and function extension points to meet the diverse needs of users.
② StreamPark has a complete set of tools for Flink job development。In StreamPark, it provides a better solution for writing Flink jobs, standardizing program configurations, simplifying the programming model, and providing a series of connectors that significantly reduce the difficulty of DataStream development.
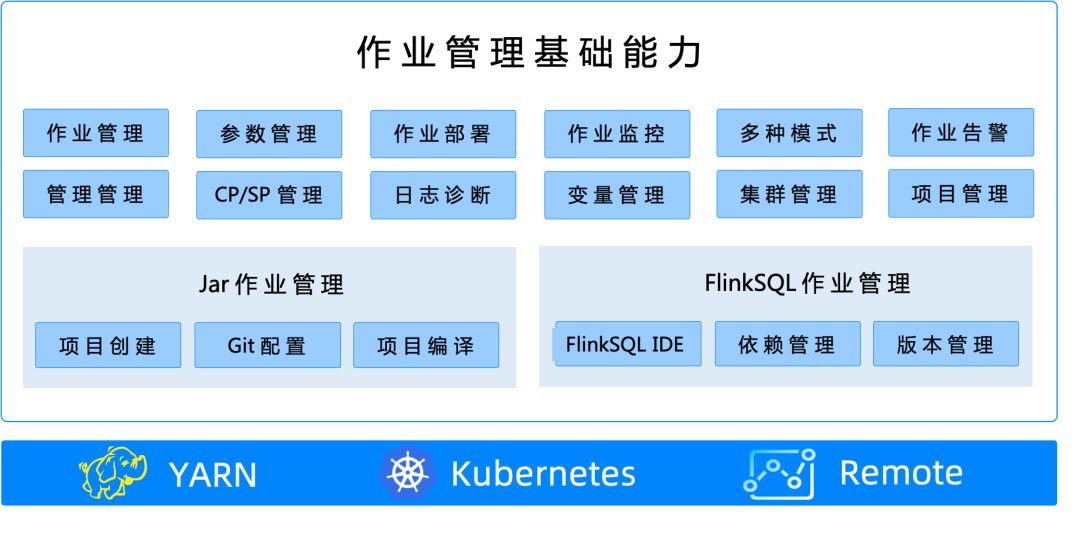
In addition to the above-mentioned advantages,StreamPark also manages the entire lifecycle of a job, including job development, deployment, operation, and problem diagnosis, so that developers can focus on the business itself without paying too much attention to the management and operation and maintenance of Flink jobs。The job development management module of StreamPark can be roughly divided into three parts: basic job management functions, JAR job management, and FlinkSQL job management.
3.StreamPark implementation practice
In order to make StreamPark more consistent with our needs in daily production practice, we have made certain adaptations to it:
Adaptable retrofits
Alarm information modification
For example, the alarms for StreamPark not only support email, Feishu, DingTalk, and WeCom push, but also support the classification of alarm information according to its importance, and push it to different alarm groups and relevant individuals, so that relevant O&M personnel can capture important alarm information in a timely manner and respond quickly.
Nocos configuration management support
In order to solve the inconvenience caused by the configuration information of Flink applications being written in the JAR package, which brings the following advantages:
① Centralized configuration management: Through StreamPark, developers can centrally manage the configuration information of all Flink applications, realize centralized management and update of configurations, and avoid switching and duplicating operations between multiple platforms. At the same time, the security of configuration management is strengthened, and the permission control of access and modification of configuration is carried out to prevent unauthorized access and modification.
② Dynamic configuration update: The integration of StreamPark and Nacos enables Flink applications to obtain the latest configuration information in a timely manner, realize dynamic configuration updates, avoid cumbersome processes such as recompiling, publishing, and restarting after modifying Flink configuration information, and improve the flexibility and response speed of the system. At the same time, StreamPark can use the configuration push function of Nacos to realize the automatic update of configuration information.
Problems encountered and solutions
Our current private cloud analysis cluster uses Cloudera CDP, and the Flink version is Cloudera Version 1.14. The overall Flink installation directory and configuration file structure are quite different from the community version. Deploying directly according to the official StreamPark documentation will make it impossible to configure Flink Home and submit subsequent overall Flink tasks to the cluster. Therefore, targeted adaptation and integration are required to provide a complete StreamPark usage experience to meet usage requirements.
1. Flink cluster cannot be accessed
① Problem description: The installation path of Cloudera Flink is inconsistent with the actual submission path, and the conf directory is missing in the actual submission path.
② Solution: The actual flink submission path is in
/opt/cloudera/parcels/Flink-$ {version}/lib/flink/bin/flink
Therefore the path
/opt/cloudera/parcels/Flink-$ {version}/1ib/flink
It can be understood as the real Flink Home, check the content under this directory for details.
It was found that the conf directory is missing. If the directory is configured as Flink Home in StreamPark, the cluster will not be accessible. Therefore, you can soft-link the Flink configuration or edit the Flink configuration file in the cluster under this path.
In summary, after the pre-configuration and packaging of the code (the code may involve optimization and modification for your own use), it can be deployed.
Note that if the version 2.0 is packaged, you can directly execute the build.sh in the source code, select hybrid deployment, and the generated package is in the dist directory.
2. Hadoop environment check failed
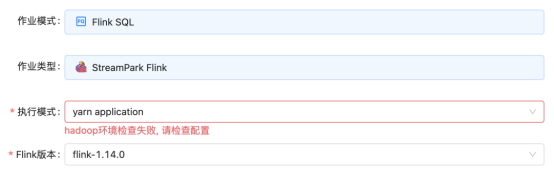
vi /etc/profile
Solution: Add the hadoop environment to the node where StreamPark is deployed.
export HADOOP_CONF_DIR=/etc/hadoop/conf
source to make it work, just restart StreamPark.
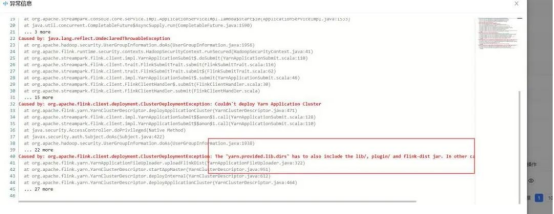
3. The lib directory is missing from the Flink path of HDFS
Solution: The lib directory in the working directory of StreamPark on HDFS after deployment is not uploaded normally. Find the initialized StremPark work path on HDFS and observe whether the lib directory under hdfs:///streampark/flink/.../ Complete, if not complete, manually put the lib in the local Flink Home directory.
4. The job is automatically pulled up after it fails, causing the job to be repeated.
StreamPark itself has the ability to restart the pull after the job is used. When a job failure is detected, it will be restarted. However, in practice, it is found that the same failed job will be started multiple times on YARN. After communicating with the community, it has been It was determined to be a bug, and the bug was finally resolved in 2.1.3.
4.Benefits
Currently, Changan Automobile has deployed StreamPark in cloud production/pre-production environment and local production/pre-production environment. As of press time, StreamPark manages a total of 150+ Flink jobs, including JAR and SQL jobs. It involves using technologies such as Flink and FlinkCDC to synchronize data from MySQL or Kafka to databases such as MySQL, Doris, HBase, and Hive. In the future, all Flink jobs in a total of 3,000+ environments will also be migrated to StreamPark in batches for centralized management.
The most obvious benefit of Apache StreamPark is that it provides a one-stop service, where business development students can complete job development, compilation and release on StreamPark, without using multiple tools to complete a FlinkSQL job development, simplifying the entire development process,StreamPark saves us a lot of time in Flink job development and deployment, and significantly improves the efficiency of Flink application development.