
Preface: This article primarily discusses the challenges encountered by Shunwang Technology in using the Flink computation engine, and how StreamPark is leveraged as a real-time data platform to address these challenges, thus supporting the company's business on a large scale.
- Introduction to the company's business
- Challenges encountered
- Why choose StreamPark
- Implementation in practice
- Benefits Brought
- Future planning
Introduction to the Company's Business
Hangzhou Shunwang Technology Co., Ltd. was established in 2005. Upholding the corporate mission of connecting happiness through technology, it is one of the influential pan-entertainment technology service platforms in China. Over the years, the company has always been driven by products and technology, dedicated to creating immersive entertainment experiences across all scenes through digital platform services.
Since its inception, Shunwang Technology has experienced rapid business growth, serving 80,000 offline physical stores, owning more than 50 million internet users, reaching over 140 million netizens annually, with 7 out of every 10 public internet service venues using Shunwang Technology's products.
With a vast user base, Shunwang Technology has been committed to providing a superior product experience and achieving digital transformation of the enterprise. Since 2015, it has vigorously developed big data capabilities, with Flink playing a crucial role in Shunwang Technology’s real-time computing. At Shunwang Technology, real-time computing is roughly divided into four application scenarios:
- Real-time update of user profiles: This includes internet cafe profiles and netizen profiles.
- Real-time risk control: This includes activity anti-brushing, monitoring of logins from different locations, etc.
- Data synchronization: This includes data synchronization from Kafka to Hive / Iceberg / ClickHouse, etc.
- Real-time data analysis: This includes real-time big screens for games, voice, advertising, live broadcasts, and other businesses.
To date, Shunwang Technology has to process TB-level data daily, with a total of more than 700 real-time tasks, of which FlinkSQL tasks account for over 95%. With the rapid development of the company's business and the increased demand for data timeliness, it is expected that the number of Flink tasks will reach 900+ by the end of this year.
Challenges Encountered
Flink, as one of the most popular real-time computing frameworks currently, boasts powerful features such as high throughput, low latency, and stateful computations. However, in our exploration, we found that while Flink has strong computational capabilities, the community has not provided effective solutions for job development management and operational issues. We have roughly summarized some of the pain points we encountered in Flink job development management into four aspects, as follows:
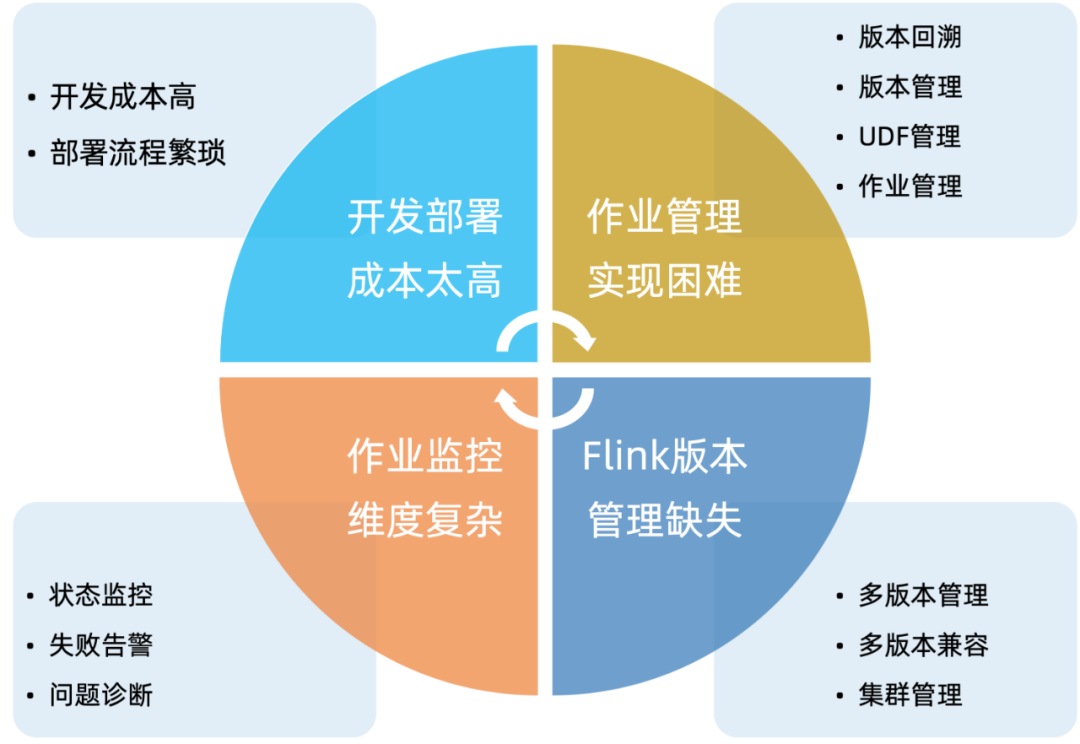
Facing a series of pain points in the management and operation of Flink jobs, we have been looking for suitable solutions to lower the barrier to entry for our developers using Flink and improve work efficiency.
Before we encountered StreamPark, we researched some companies' Flink management solutions and found that they all developed and managed Flink jobs through self-developed real-time job platforms. Consequently, we decided to develop our own real-time computing management platform to meet the basic needs of our developers for Flink job management and operation. Our platform is called Streaming-Launcher, with the following main functions:
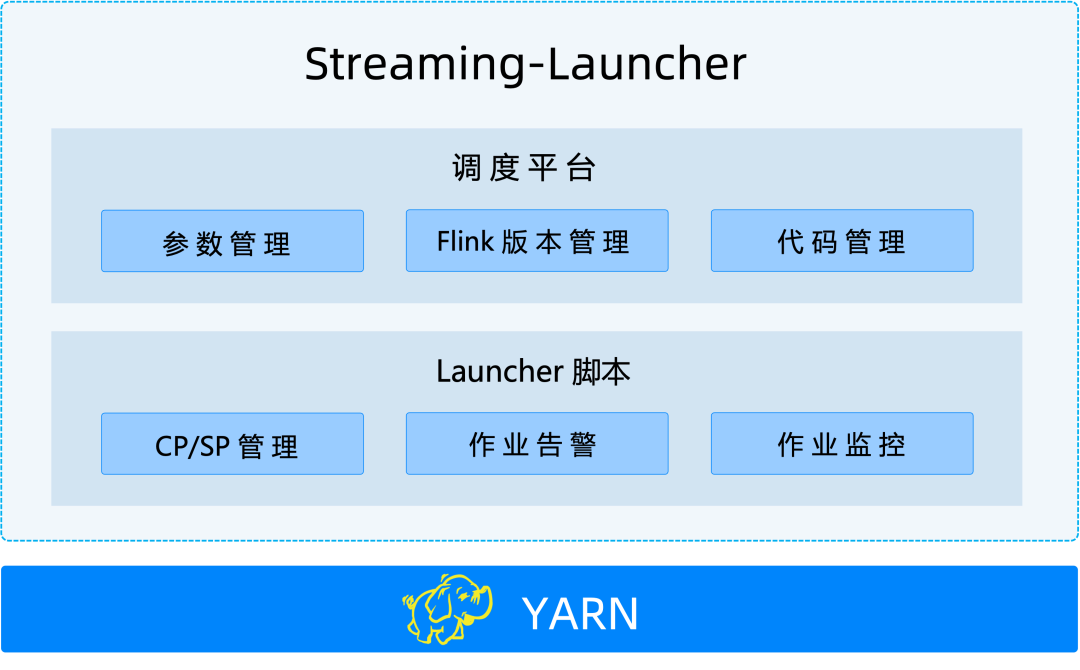
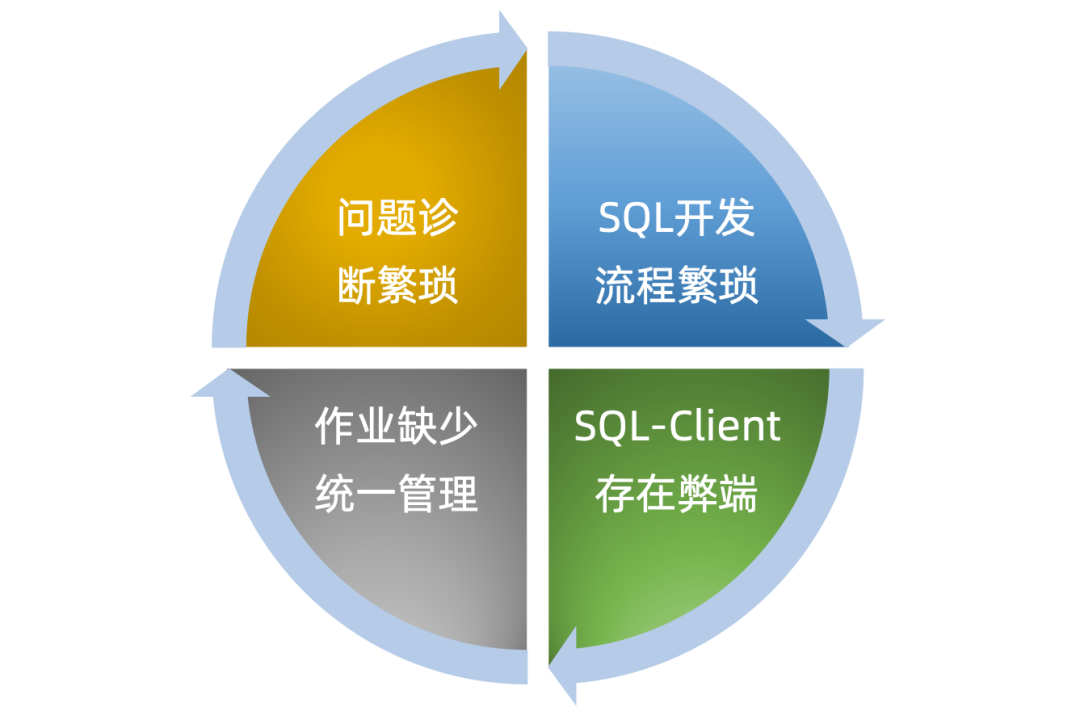
However, as our developers continued to use Streaming-Launcher, they discovered quite a few deficiencies: the development cost for Flink remained too high, work efficiency was poor, and troubleshooting was difficult. We summarized the defects of Streaming-Launcher as follows:
Cumbersome SQL Development Process
Business developers need multiple tools to complete the development of a single SQL job, increasing the barrier to entry for our developers.
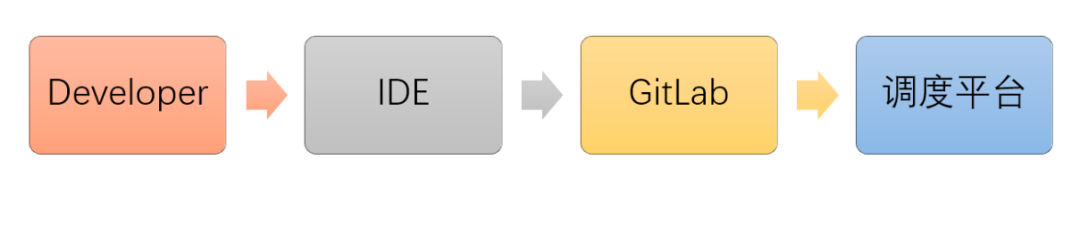
Drawbacks of SQL-Client
The SQL-Client provided by Flink currently has certain drawbacks regarding the support for job execution modes.

Lack of Unified Job Management
Within Streaming-Launcher, there is no provision of a unified job management interface. Developers cannot intuitively see the job running status and can only judge the job situation through alarm information, which is very unfriendly to developers. If a large number of tasks fail at once due to Yarn cluster stability problems or network fluctuations and other uncertain factors, it is easy for developers to miss restoring a certain task while manually recovering jobs, which can lead to production accidents.
Cumbersome Problem Diagnosis Process
To view logs for a job, developers must go through multiple steps, which to some extent reduces their work efficiency.

Why Use Apache StreamPark™
Faced with the defects of our self-developed platform Streaming-Launcher, we have been considering how to further lower the barriers to using Flink and improve work efficiency. Considering the cost of human resources and time, we decided to seek help from the open-source community and look for an appropriate open-source project to manage and maintain our Flink tasks.
01 Apache StreamPark™: A Powerful Tool for Solving Flink Issues
Fortunately, in early June 2022, we stumbled upon StreamPark on GitHub and embarked on a preliminary exploration full of hope. We found that StreamPark's capabilities can be broadly divided into three areas: user permission management, job operation and maintenance management, and development scaffolding.
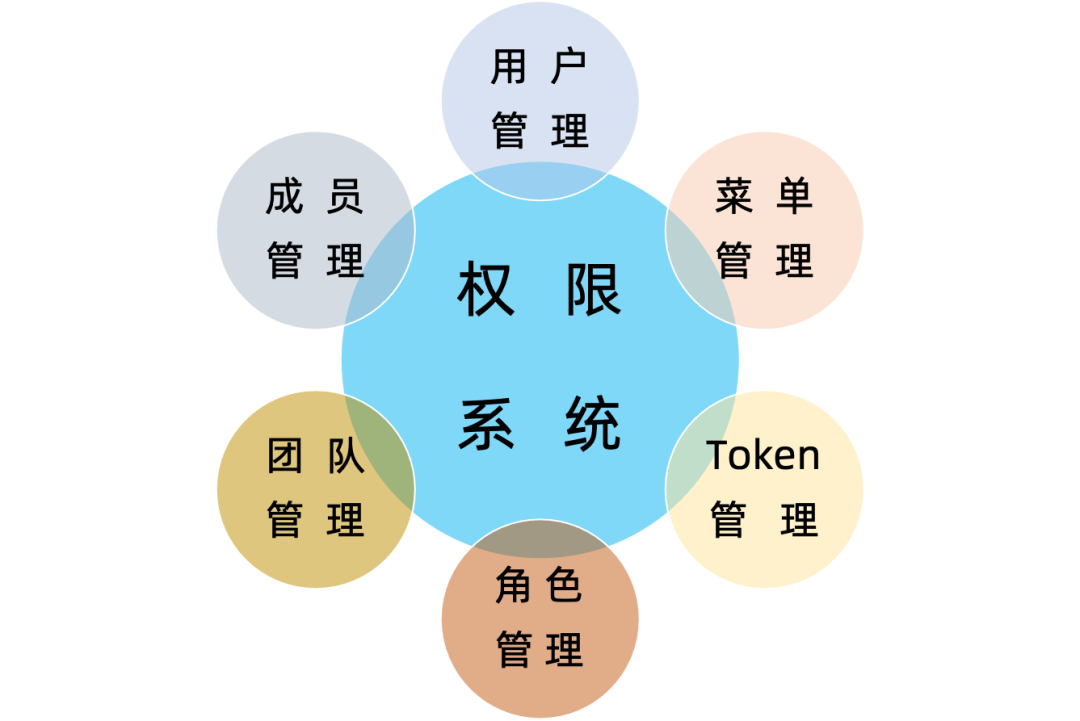
User Permission Management
In the StreamPark platform, to avoid the risk of users having too much authority and making unnecessary misoperations that affect job stability and the accuracy of environmental configurations, some user permission management functions are provided. This is very necessary for enterprise-level users.
Job Operation and Maintenance Management
Our main focus during the research on StreamPark was its capability to manage the entire lifecycle of jobs: from development and deployment to management and problem diagnosis. Fortunately, StreamPark excels in this aspect, relieving developers from the pain points associated with Flink job management and operation. Within StreamPark’s job operation and maintenance management, there are three main modules: basic job management functions, Jar job management, and FlinkSQL job management as shown below:
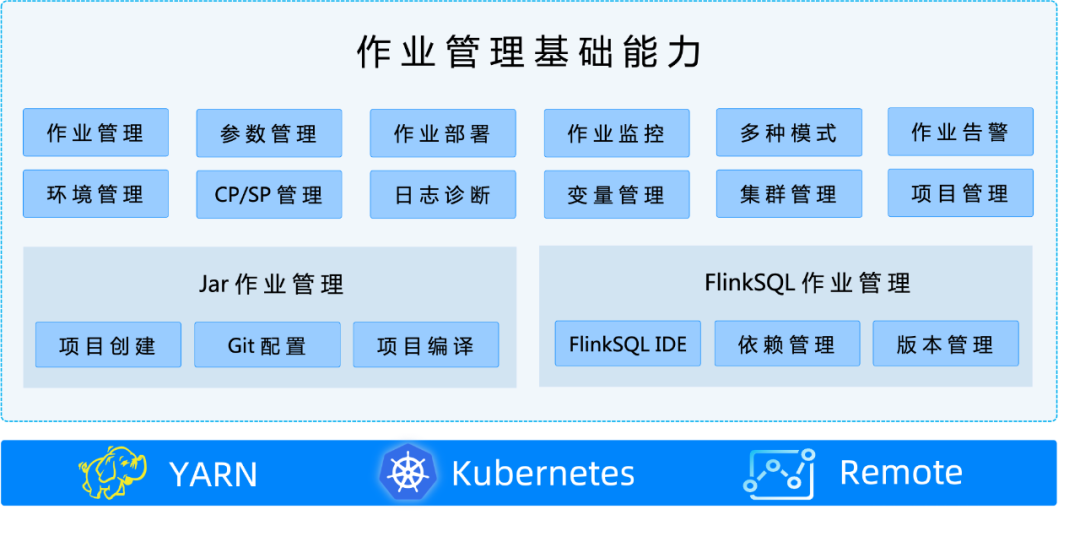
Development Scaffolding
Further research revealed that StreamPark is not just a platform but also includes a development scaffold for Flink jobs. It offers a better solution for code-written Flink jobs, standardizing program configuration, providing a simplified programming model, and a suite of Connectors that lower the barrier to entry for DataStream development.
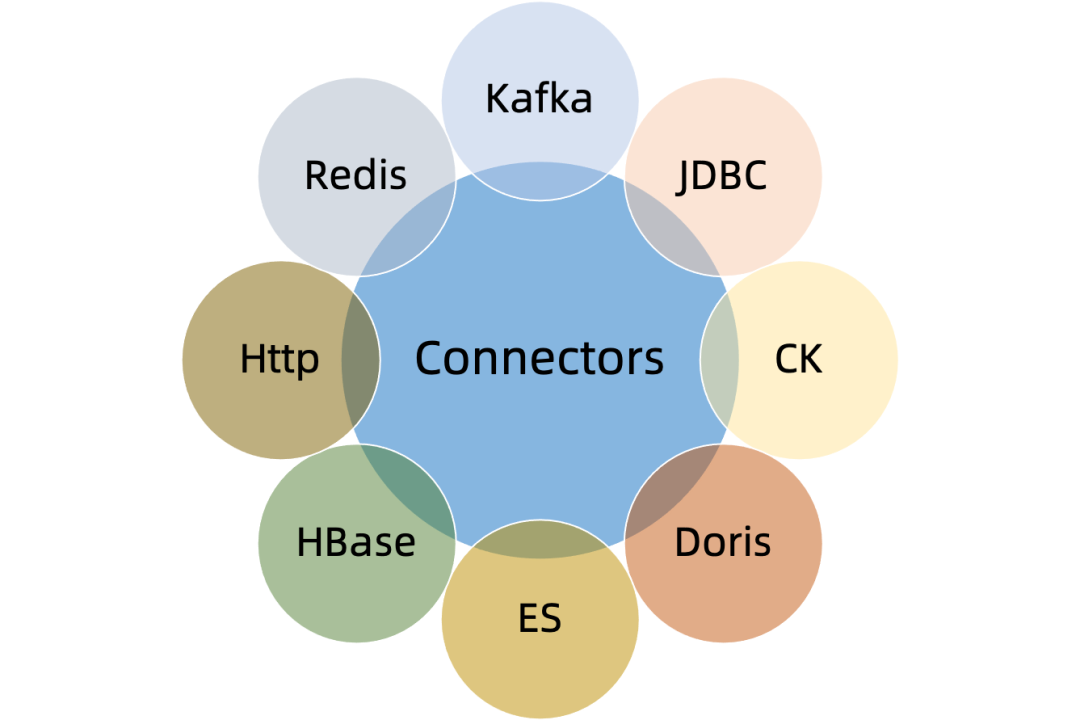
02 How Apache StreamPark™ Addresses Issues of the Self-Developed Platform
We briefly introduced the core capabilities of StreamPark above. During the technology selection process at Shunwang Technology, we found that StreamPark not only includes the basic functions of our existing Streaming-Launcher but also offers a more complete set of solutions to address its many shortcomings. Here, we focus on the solutions provided by StreamPark for the deficiencies of our self-developed platform, Streaming-Launcher.
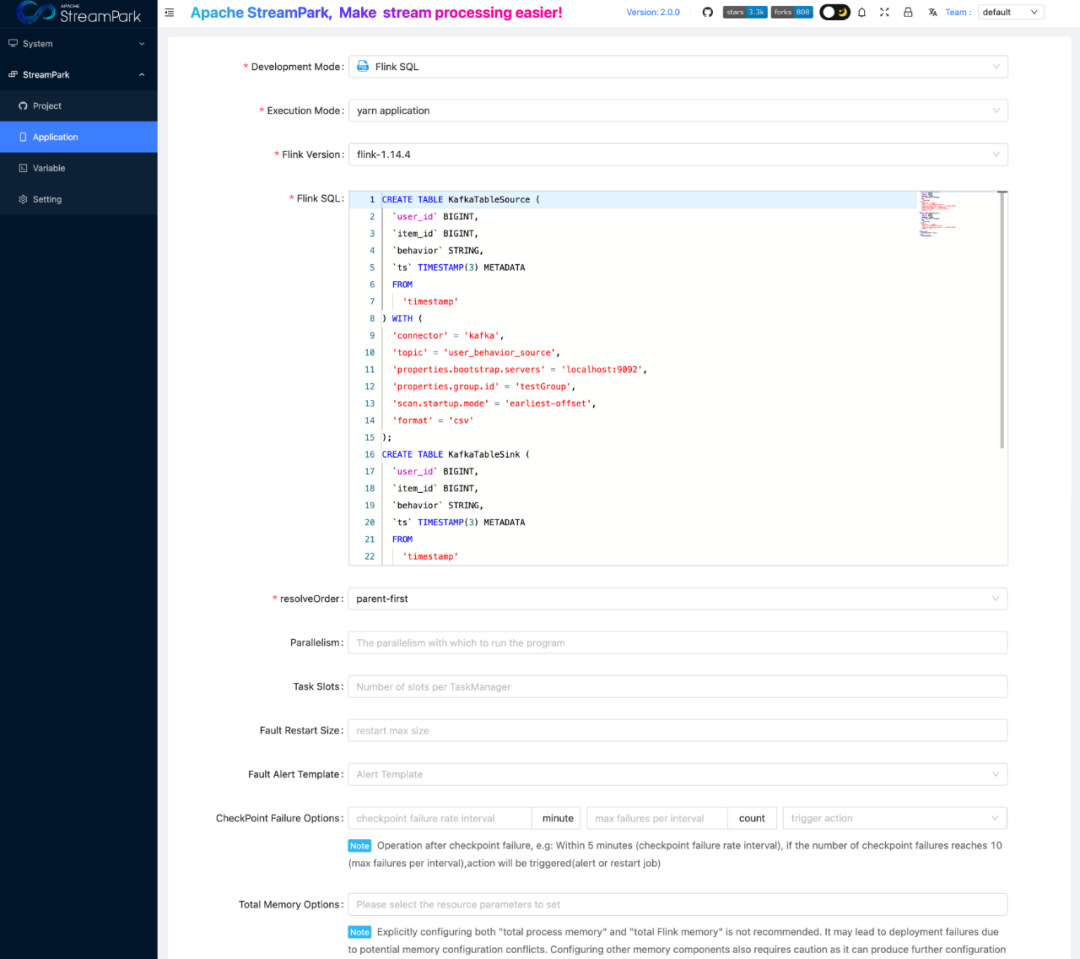
One-Stop Flink Job Development Capability
To lower the barriers to Flink job development and improve developers' work efficiency, StreamPark provides features like FlinkSQL IDE, parameter management, task management, code management, one-click compilation, and one-click job deployment and undeployment. Our research found that these integrated features of StreamPark could further enhance developers’ work efficiency. To some extent, developers no longer need to concern themselves with the difficulties of Flink job management and operation and can focus on developing the business logic. These features also solve the pain point of cumbersome SQL development processes in Streaming-Launcher.
Support for Multiple Deployment Modes
The Streaming-Launcher was not flexible for developers since it only supported the Yarn Session mode. StreamPark provides a comprehensive solution for this aspect. StreamPark fully supports all of Flink's deployment modes: Remote, Yarn Per-Job, Yarn Application, Yarn Session, K8s Session, and K8s Application, allowing developers to freely choose the appropriate running mode for different business scenarios.
Unified Job Management Center
For developers, job running status is one of their primary concerns. In Streaming-Launcher, due to the lack of a unified job management interface, developers had to rely on alarm information and Yarn application status to judge the state of tasks, which was very unfriendly. StreamPark addresses this issue by providing a unified job management interface, allowing for a clear view of the running status of each task.
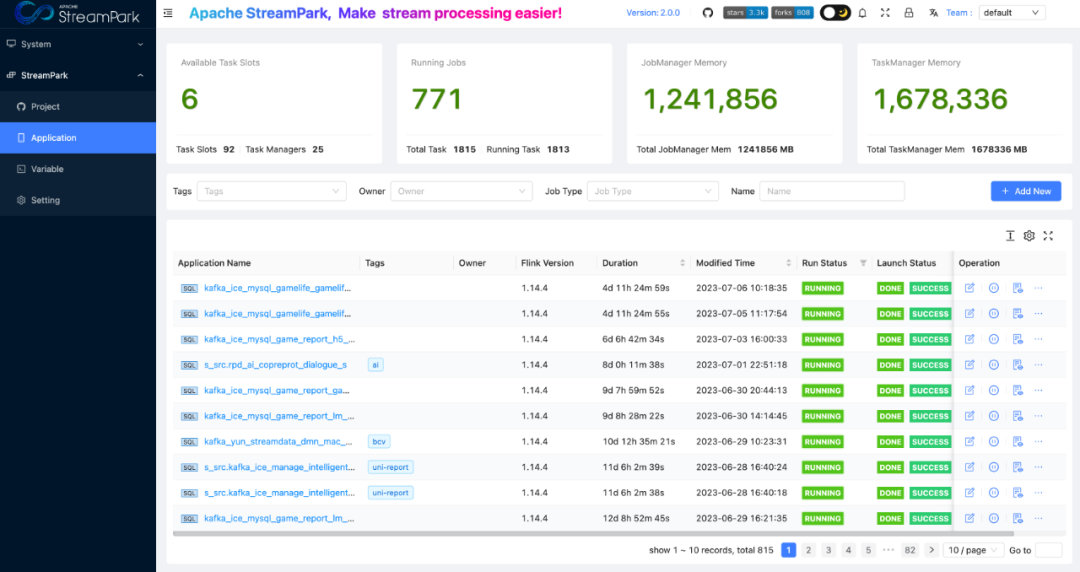
In the Streaming-Launcher, developers had to go through multiple steps to diagnose job issues and locate job runtime logs. StreamPark offers a one-click jump feature that allows quick access to job runtime logs.
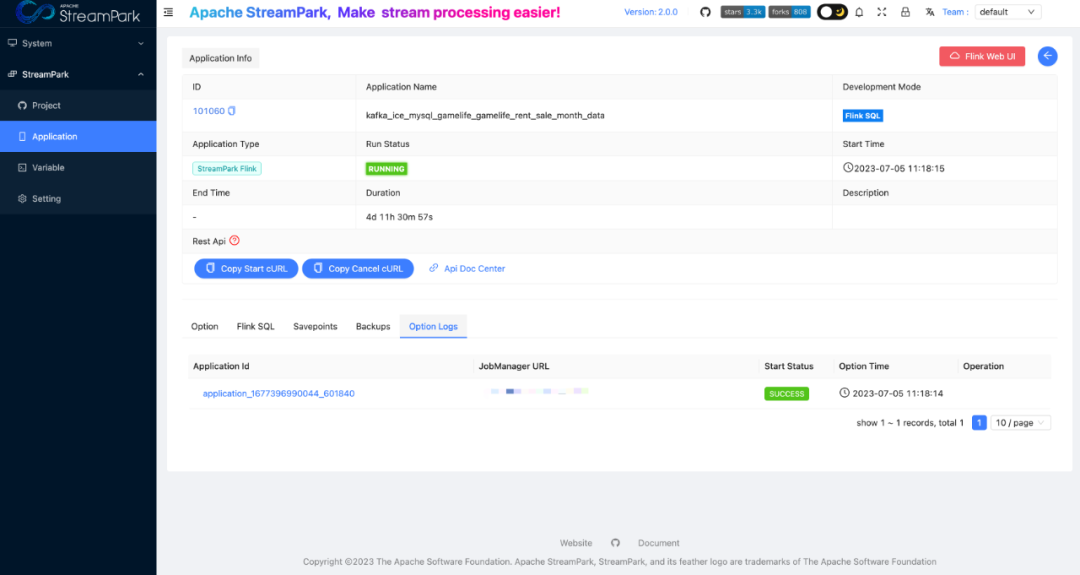
Practical Implementation
When introducing StreamPark to Shunwang Technology, due to the company's business characteristics and some customized requirements from the developers, we made some additions and optimizations to the functionalities of StreamPark. We have also summarized some problems encountered during the use and corresponding solutions.
01 Leveraging the Capabilities of Flink-SQL-Gateway
At Shunwang Technology, we have developed the ODPS platform based on the Flink-SQL-Gateway to facilitate business developers in managing the metadata of Flink tables. Business developers perform DDL operations on Flink tables in ODPS, and then carry out analysis and query operations on the created Flink tables in StreamPark. Throughout the entire business development process, we have decoupled the creation and analysis of Flink tables, making the development process appear more straightforward.
If developers wish to query real-time data in ODPS, we need to provide a Flink SQL runtime environment. We have used StreamPark to run a Yarn Session Flink environment to support ODPS in conducting real-time queries.
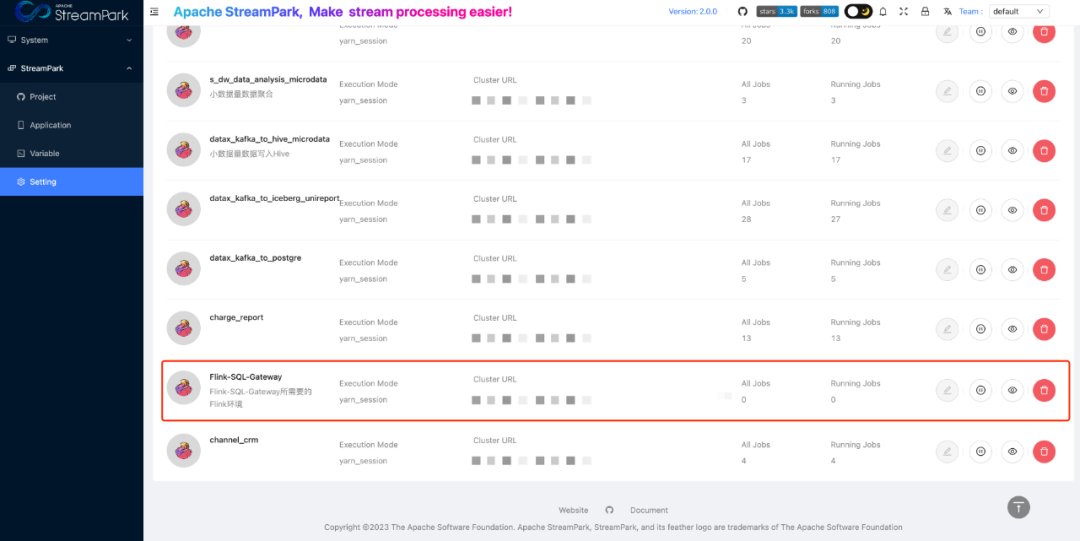
Currently, the StreamPark community is intergrating with Flink-SQL-Gateway to further lower the barriers to developing real-time jobs.
https://github.com/apache/streampark/issues/2274
02 Enhancing Flink Cluster Management Capabilities
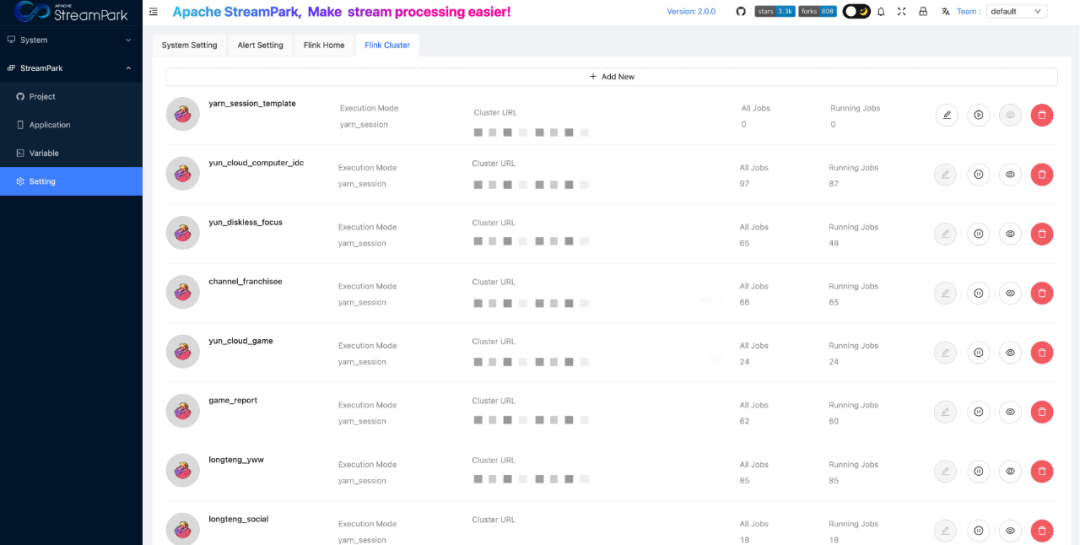
At Shunwang Technology, there are numerous jobs synchronizing data from Kafka to Iceberg / PG / Clickhouse / Hive. These jobs do not have high resource requirements and timeliness demands on Yarn. However, if Yarn Application and per-job modes are used for all tasks, where each task starts a JobManager, this would result in a waste of Yarn resources. For this reason, we decided to run these numerous data synchronization jobs in Yarn Session mode.
In practice, we found it difficult for business developers to intuitively know how many jobs are running in each Yarn Session, including the total number of jobs and the number of jobs that are running. Based on this, to facilitate developers to intuitively observe the number of jobs in a Yarn Session, we added All Jobs and Running Jobs in the Flink Cluster interface to indicate the total number of jobs and the number of running jobs in a Yarn Session.
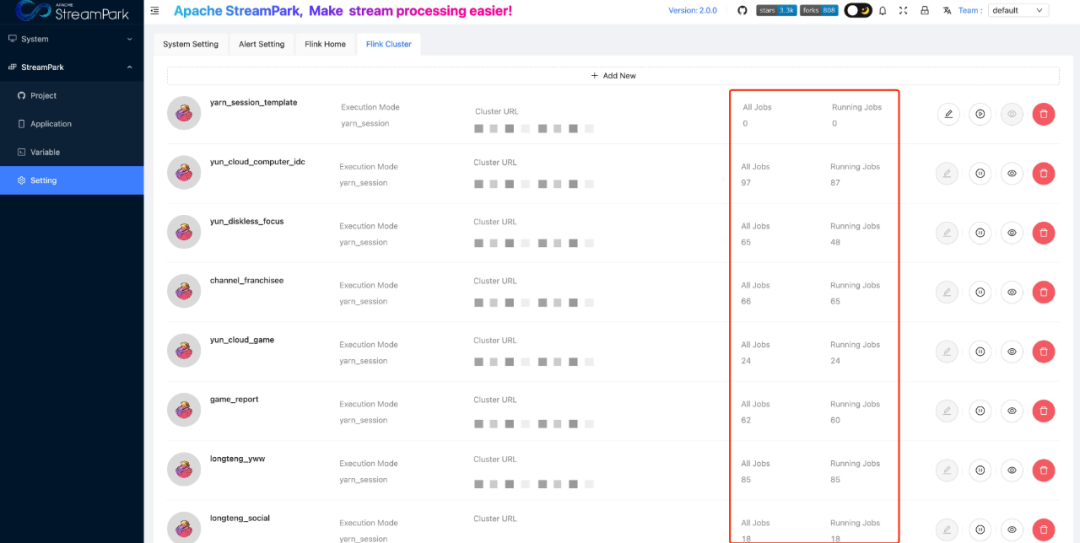
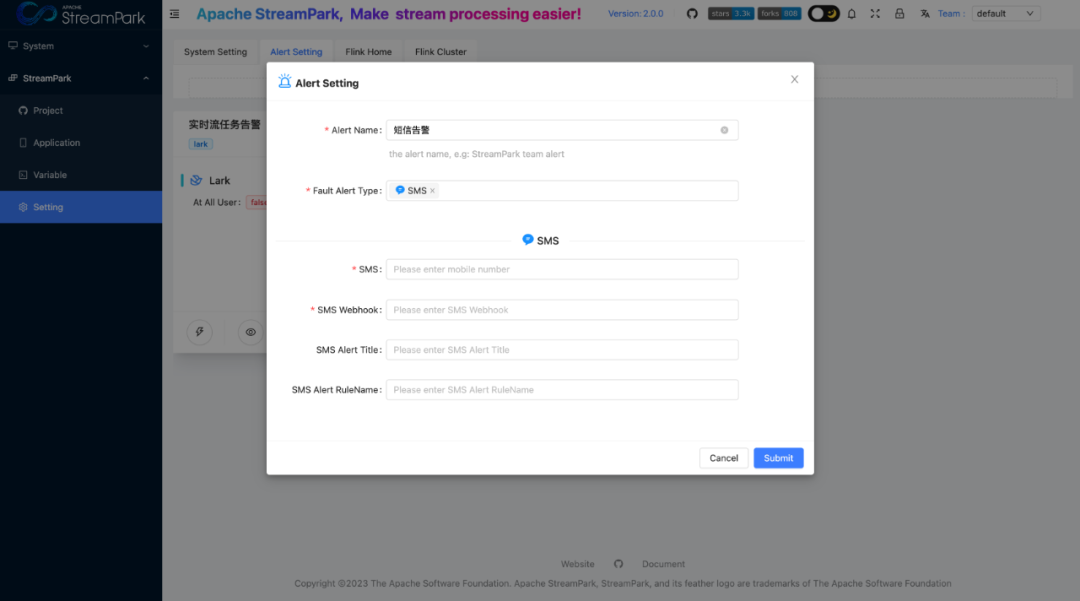
03 Enhancing Alert Capabilities
Since each company's SMS alert platform is implemented differently, the StreamPark community has not abstracted a unified SMS alert function. Here, we have implemented the SMS alert function through the Webhook method.
04 Adding a Blocking Queue to Solve Throttling Issues
In production practice, we found that when a large number of tasks fail at the same time, such as when a Yarn Session cluster goes down, platforms like Feishu/Lark and WeChat have throttling issues when multiple threads call the alert interface simultaneously. Consequently, only a portion of the alert messages will be sent by StreamPark due to the throttling issues of platforms like Feishu/Lark and WeChat, which can easily mislead developers in troubleshooting. At Shunwang Technology, we added a blocking queue and an alert thread to solve the throttling issue.
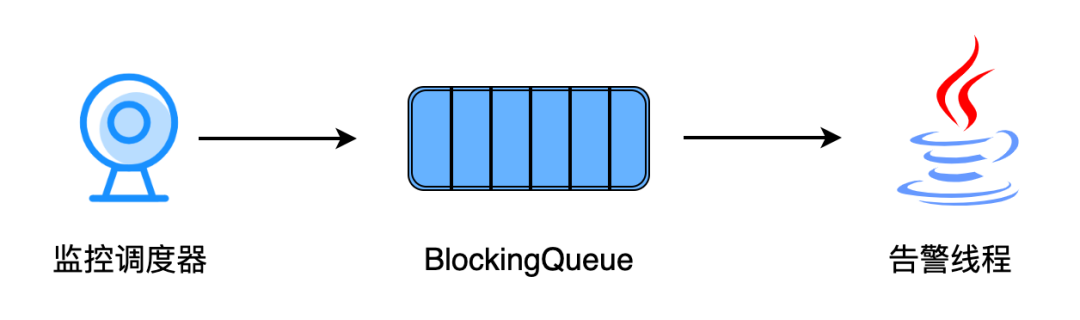
When the job monitoring scheduler detects an abnormality in a job, it generates a job exception message and sends it to the blocking queue. The alert thread will continuously consume messages from the blocking queue. Upon receiving a job exception message, it will send the alert to different platforms sequentially according to the user-configured alert information. Although this method might delay the alert delivery to users, in practice, we found that even with 100+ Flink jobs failing simultaneously, the delay in receiving alerts is less than 3 seconds. Such a delay is completely acceptable to our business development colleagues. This improvement has been recorded as an ISSUE and is currently under consideration for contribution to the community.
https://github.com/apache/streampark/issues/2142
Benefits Brought
We started exploring and using StreamX 1.2.3 (the predecessor of StreamPark) and after more than a year of running in, we found that StreamPark truly resolves many pain points in the development management and operation and maintenance of Flink jobs.
The greatest benefit that StreamPark has brought to Shunwang Technology is the lowered threshold for using Flink and improved development efficiency. Previously, our business development colleagues had to use multiple tools such as vscode, GitLab, and a scheduling platform in the original Streaming-Launcher to complete a FlinkSQL job development. The process was tedious, going through multiple tools from development to compilation to release. StreamPark provides one-stop service, allowing job development, compilation, and release to be completed on StreamPark, simplifying the entire development process.
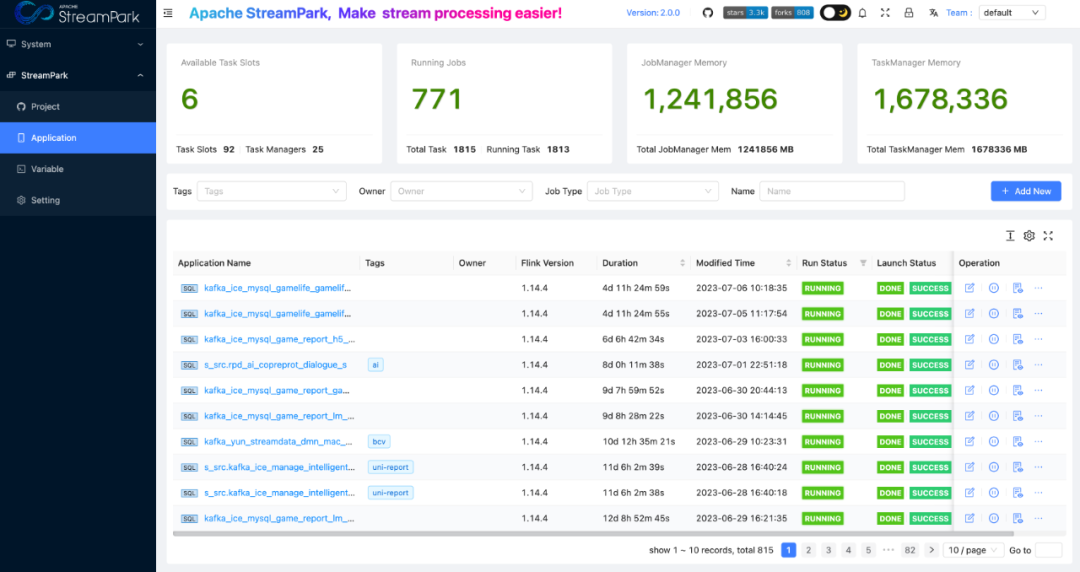
At present, StreamPark has been massively deployed in the production environment at Shunwang Technology, with the number of FlinkSQL jobs managed by StreamPark increasing from the initial 500+ to nearly 700, while also managing more than 10 Yarn Session Clusters.
Future Plans
As one of the early users of StreamPark, Shunwang Technology has been communicating with the community for a year and participating in the polishing of StreamPark's stability. We have submitted the Bugs encountered in production operations and new Features to the community. In the future, we hope to manage the metadata information of Flink tables on StreamPark, and implement cross-data-source query analysis functions based on the Flink engine through multiple Catalogs. Currently, StreamPark is integrating with Flink-SQL-Gateway capabilities, which will greatly help in the management of table metadata and cross-data-source query functions in the future.
Since Shunwang Technology primarily runs jobs in Yarn Session mode, we hope that StreamPark can provide more support for Remote clusters, Yarn Session clusters, and K8s Session clusters, such as monitoring and alerts, and optimizing operational processes.
Considering the future, as the business develops, we may use StreamPark to manage more Flink real-time jobs, and StreamPark in single-node mode may not be safe. Therefore, we are also looking forward to the High Availability (HA) of StreamPark.
We will also participate in the construction of the capabilities of StreamPark is integrating with Flink-SQL-Gateway, enriching Flink Cluster functionality, and StreamPark HA.