Wuxin Technology was founded in January 2018. The current main business includes the research and development, design, manufacturing and sales of RELX brand products. With core technologies and capabilities covering the entire industry chain, RELX is committed to providing users with products that are both high quality and safe.
Why Choose Native Kubernetes
Native Kubernetes offers the following advantages:
-
Shorter Failover time
-
Resource hosting can be implemented without the need to manually create TaskManager Pods, which can be automatically destroyed
-
With more convenient HA, in Native Kubernetes mode after Flink version 1.12, you can rely on the Leader election mechanism of native Kubernetes to complete JobManager's HA
The main difference between Native Kubernetes and Standalone Kubernetes lies in the way Flink interacts with Kubernetes and the resulting series of advantages. Standalone Kubernetes requires users to customize the Kubernetes resource description files of JobManager and TaskManager. When submitting a job, you need to use kubectl combined with the resource description file to start the Flink cluster. The Native Kubernetes mode Flink Client integrates a Kubernetes Client, which can directly communicate with the Kubernetes API Server to complete the creation of JobManager Deployment and ConfigMap. After JobManager Development is created, the Resource Manager module in it can directly communicate with the Kubernetes API Server to complete the creation and destruction of TaskManager pods and the elastic scaling of Taskmanager. Therefore, it is recommended to use Flink on Native Kubernetes mode to deploy Flink tasks in production environments.
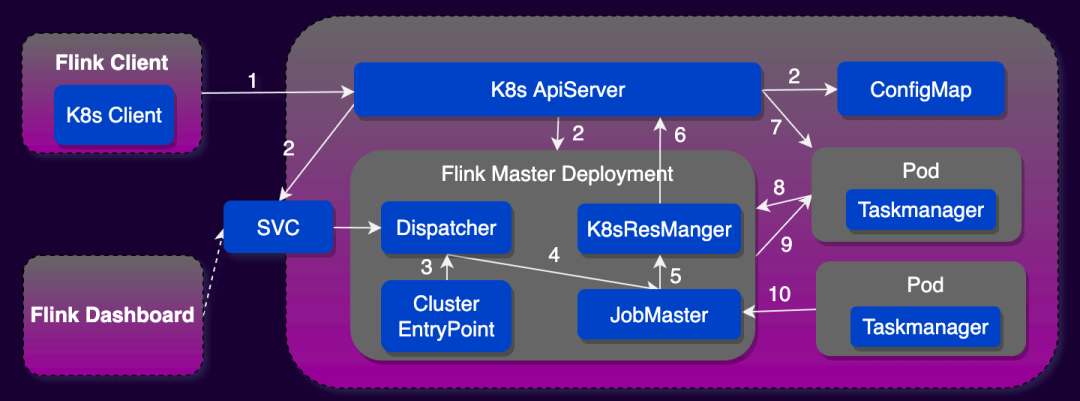
When Flink On Kubernetes meets StreamPark
Flink on Native Kubernetes currently supports Application mode and Session mode. Compared with the two, Application mode deployment avoids the resource isolation problem and client resource consumption problem of Session mode. Therefore, it is recommended to use Application Mode to deploy Flink tasks in ** production environments. **Let’s take a look at the method of using the original script and the process of using StreamPark to develop and deploy a Flink on Native Kubernetes job. Deploy Kubernetes using scripts
In the absence of a platform that supports Flink on Kubernetes task development and deployment, you need to use scripts to submit and stop tasks. This is also the default method provided by Flink. The specific steps are as follows:
- Prepare the kubectl and Docker command running environment on the Flink client node, create the Kubernetes Namespace and Service Account used to deploy the Flink job, and perform RBAC
- Write a Dockerfile file to package the Flink base image and the user’s job Jar together
FROM flink:1.13.6-scala_2.11
RUN mkdir -p $FLINK_HOME/usrlib
COPY my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
- Use Flink client script to start Flink tasks
./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.namespace=flink-cluster \
-Dkubernetes.jobmanager.service-account=default \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=relx_docker_url/streamx/relx_flink_1.13.6-scala_2.11:latest \
-Dkubernetes.rest-service.exposed.type=NodePort \
local:///opt/flink/usrlib/my-flink-job.jar
- Use the Kubectl command to obtain the WebUI access address and JobId of the Flink job.
kubectl -n flink-cluster get svc
- Stop the job using Flink command
./bin/flink cancel
--target kubernetes-application
-Dkubernetes.cluster-id=my-first-application-cluster
-Dkubernetes.namespace=flink-cluster <jobId>
The above is the process of deploying a Flink task to Kubernetes using the most original script method provided by Flink. Only the most basic task submission is achieved. If it is to reach the production use level, there are still a series of problems that need to be solved, such as: the method is too Originally, it was unable to adapt to large batches of tasks, unable to record task checkpoints and real-time status tracking, difficult to operate and monitor tasks, had no alarm mechanism, and could not be managed in a centralized manner, etc.
Deploy Flink on Kubernetes using Apache StreamPark™
There will be higher requirements for using Flink on Kubernetes in enterprise-level production environments. Generally, you will choose to build your own platform or purchase related commercial products. No matter which solution meets the product capabilities: large-scale task development and deployment, status tracking, operation and maintenance monitoring , failure alarms, unified task management, high availability, etc. are common demands.
In response to the above issues, we investigated open source projects in the open source field that support the development and deployment of Flink on Kubernetes tasks. During the investigation, we also encountered other excellent open source projects. After comprehensively comparing multiple open source projects, we came to the conclusion: **StreamPark has great performance in either completness, user experience, or stability, so we finally chose StreamPark as our one-stop real-time computing platform. **
Let’s take a look at how StreamPark supports Flink on Kubernetes:
Basic environment configuration
Basic environment configuration includes Kubernetes and Docker repository information as well as Flink client information configuration. The simplest way for the Kubernetes basic environment is to directly copy the .kube/config of the Kubernetes node to the StreamPark node user directory, and then use the kubectl command to create a Flink-specific Kubernetes Namespace and perform RBAC configuration.
# Create k8s namespace used by Flink jobs
kubectl create ns flink-cluster
# Bind RBAC resources to the default user
kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=flink-cluster:default
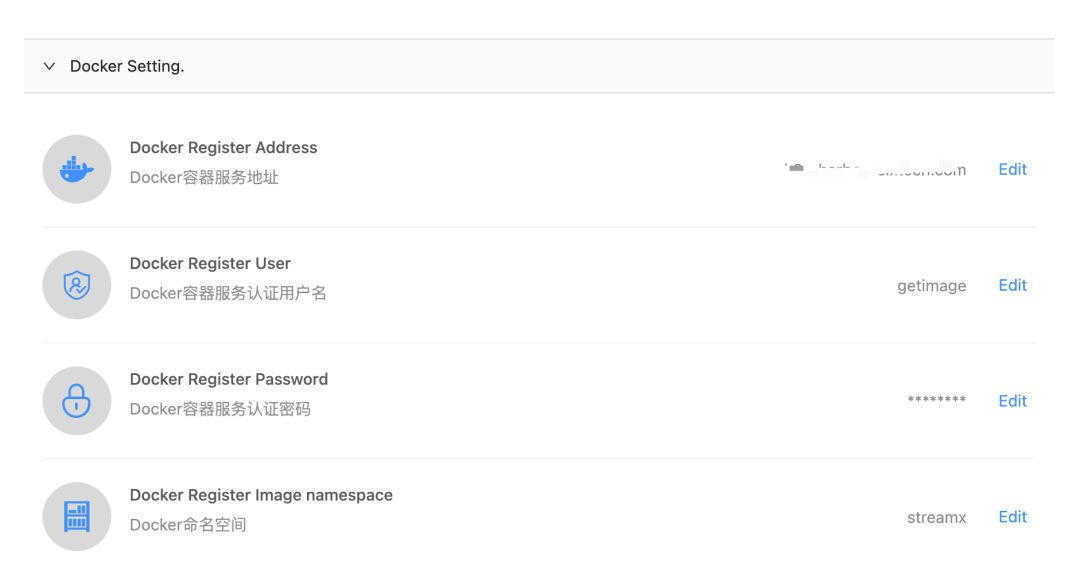
Docker account information can be configured directly in the Docker Setting interface:
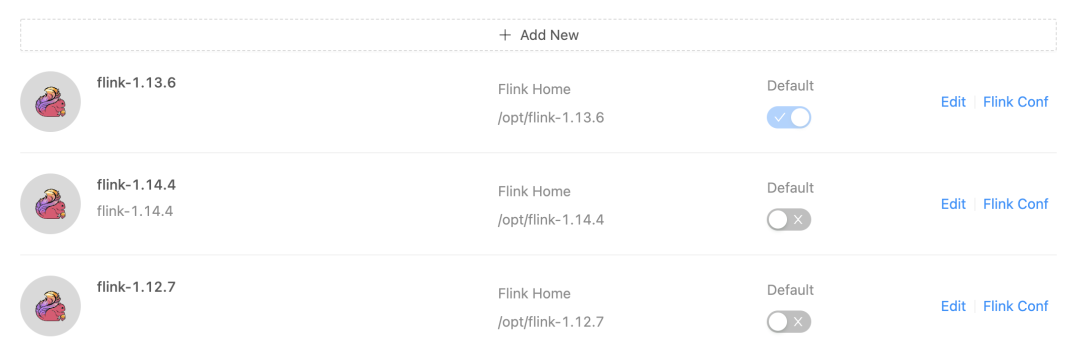
StreamPark can adapt to multi-version Flink job development. The Flink client can be configured directly on the StreamPark Setting interface:
Job development
After StreamPark has configured the basic environment, it only takes three steps to develop and deploy a Flink job:
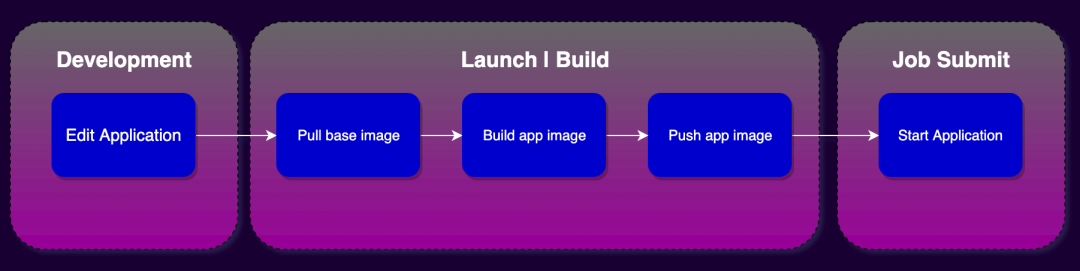
StreamPark supports both Upload Jar and direct writing of Flink SQL jobs. Flink SQL jobs only need to enter SQL and dependencies. This method greatly improves the development experience and avoids problems such as dependency conflicts. This article does not focus on this part。
Here you need to select the deployment mode as kubernetes application, and configure the following parameters on the job development page: The parameters in the red box are the basic parameters of Flink on Kubernetes.
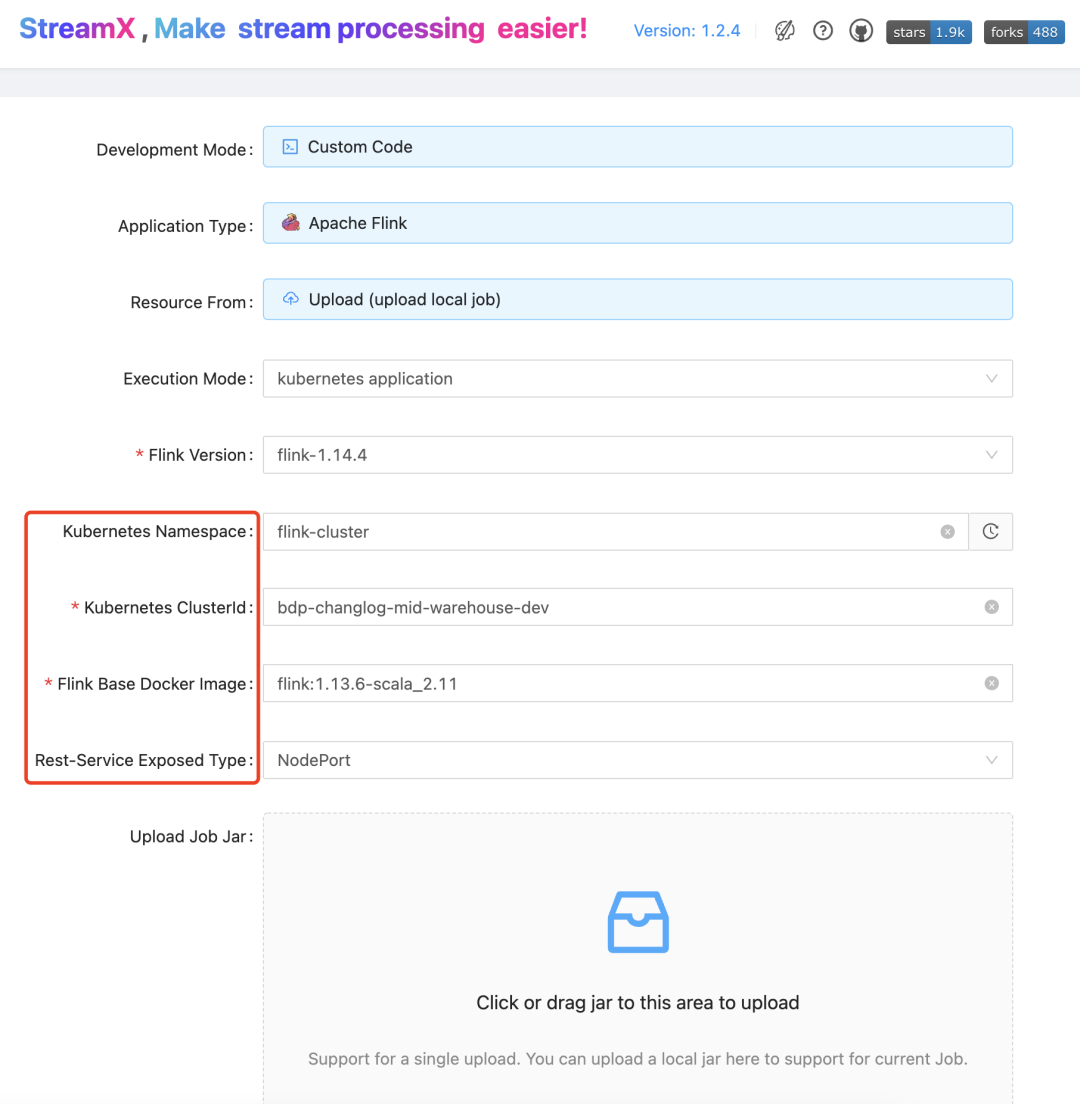
The following parameters are parameters related to Flink jobs and resources. The choice of Resolve Order is related to the code loading mode. For jobs uploaded by the Upload Jar developed by the DataStream API, choose to use Child-first, and for Flink SQL jobs, choose to use Parent-first loading.
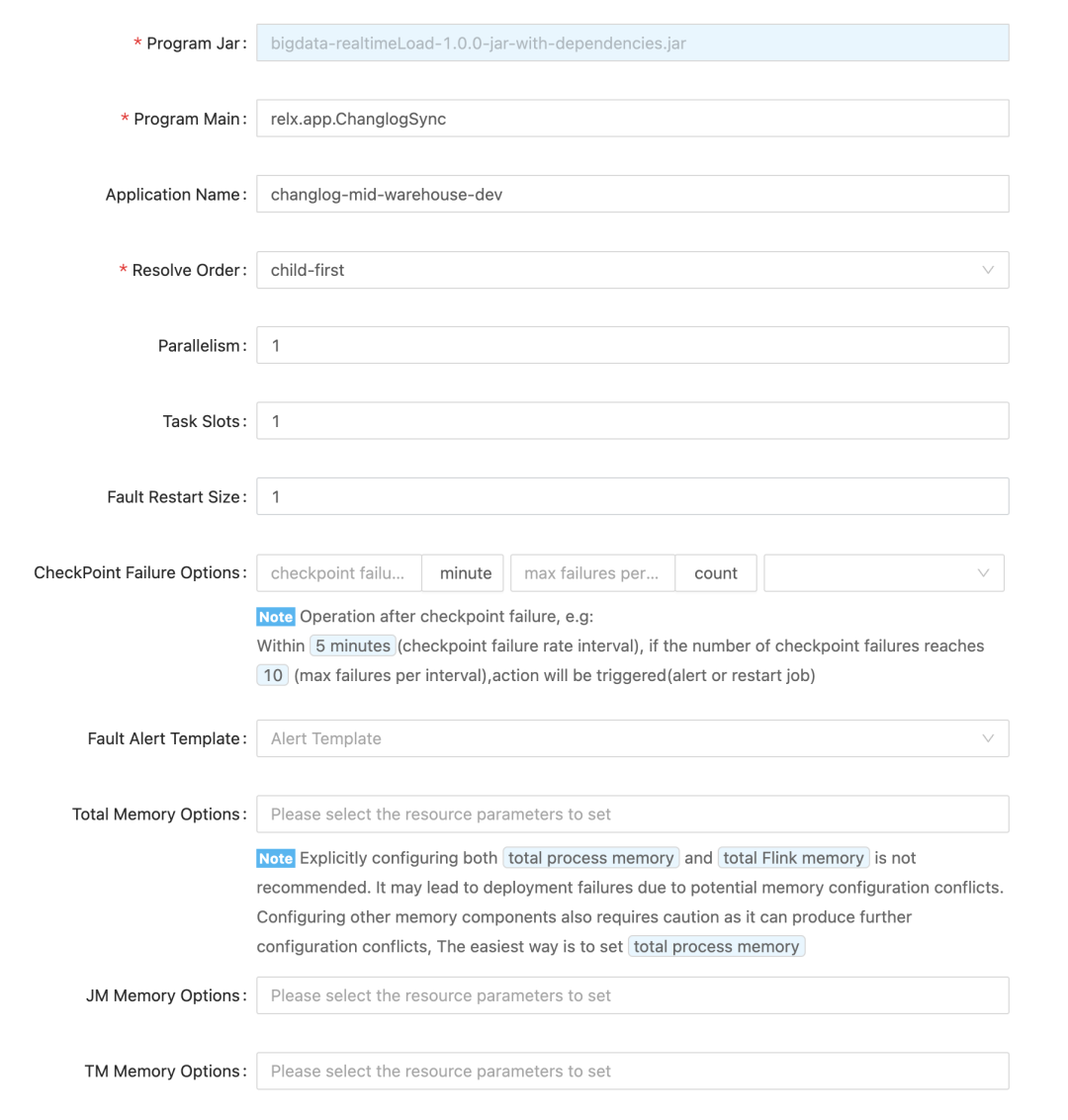
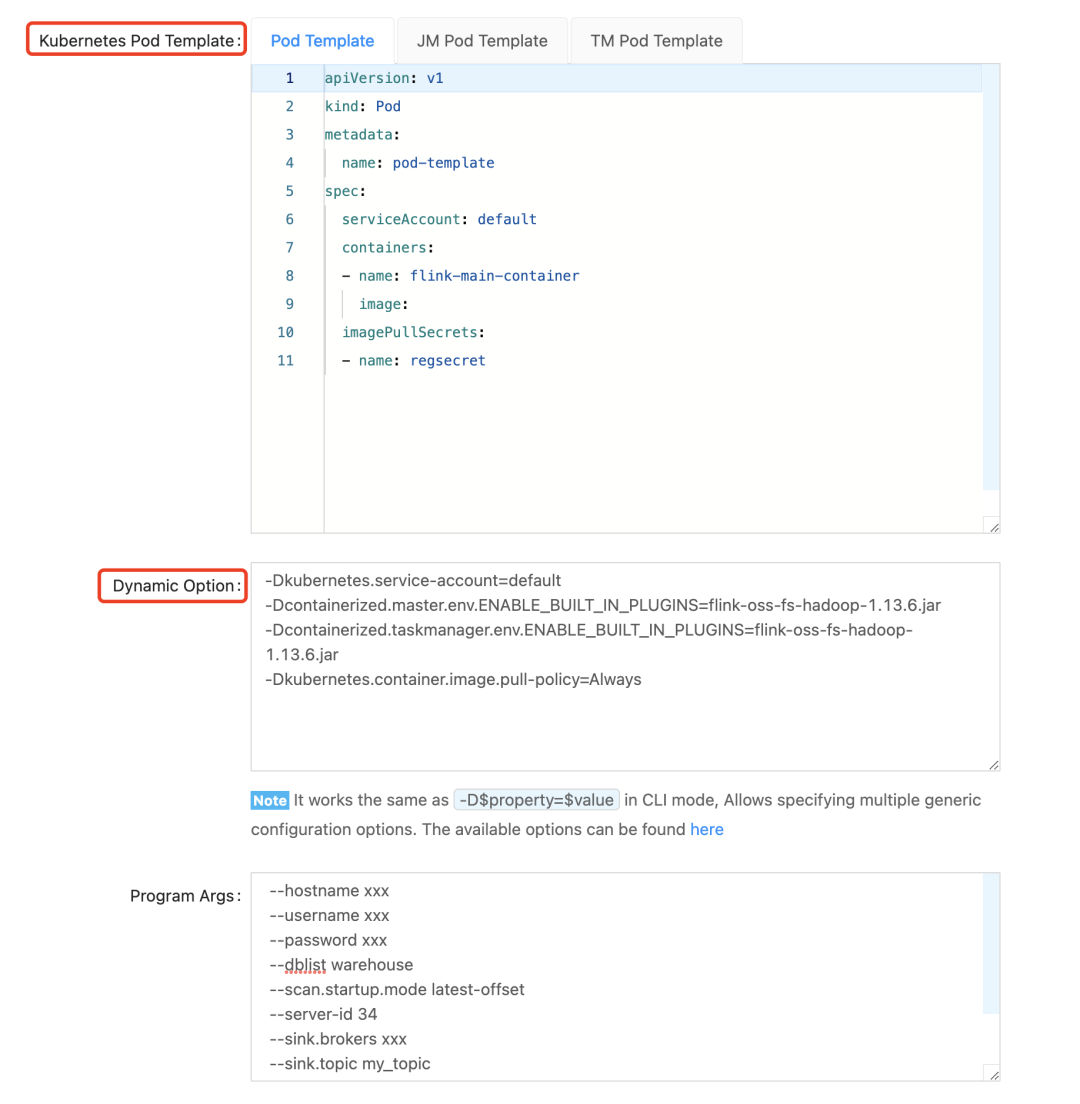
Finally, there are the following two heavyweight parameters. For Native Kubernetes, k8s-pod-template generally only requires pod-template configuration. Dynamic Option is a supplement to the pod-template parameters. For some personalized configurations, you can Configured in Dynamic Option. For more Dynamic Option, please directly refer to the Flink official website.
Job online
After the job development is completed, the job comes online. In this step, StreamPark has done a lot of work, as follows:
- Prepare environment
- Dependency download in job
- Build job (JAR package)
- Build image
- Push the image to the remote repository
For users: Just click the cloud-shaped online button in the task list
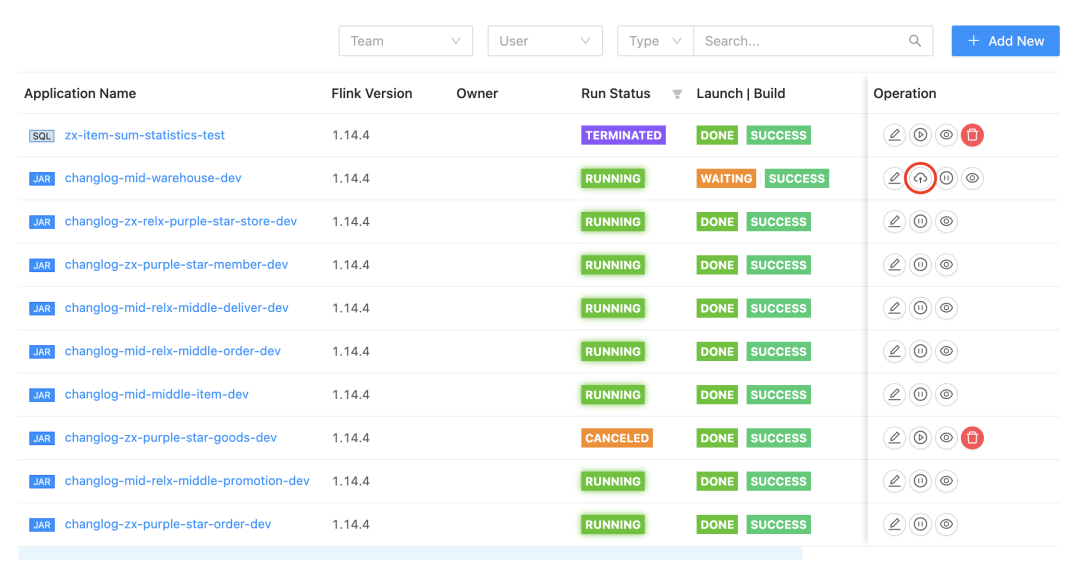
We can see a series of work done by StreamPark when building and pushing the image: Read the configuration, build the image, and push the image to the remote repository... I want to give StreamPark a big thumbs up!
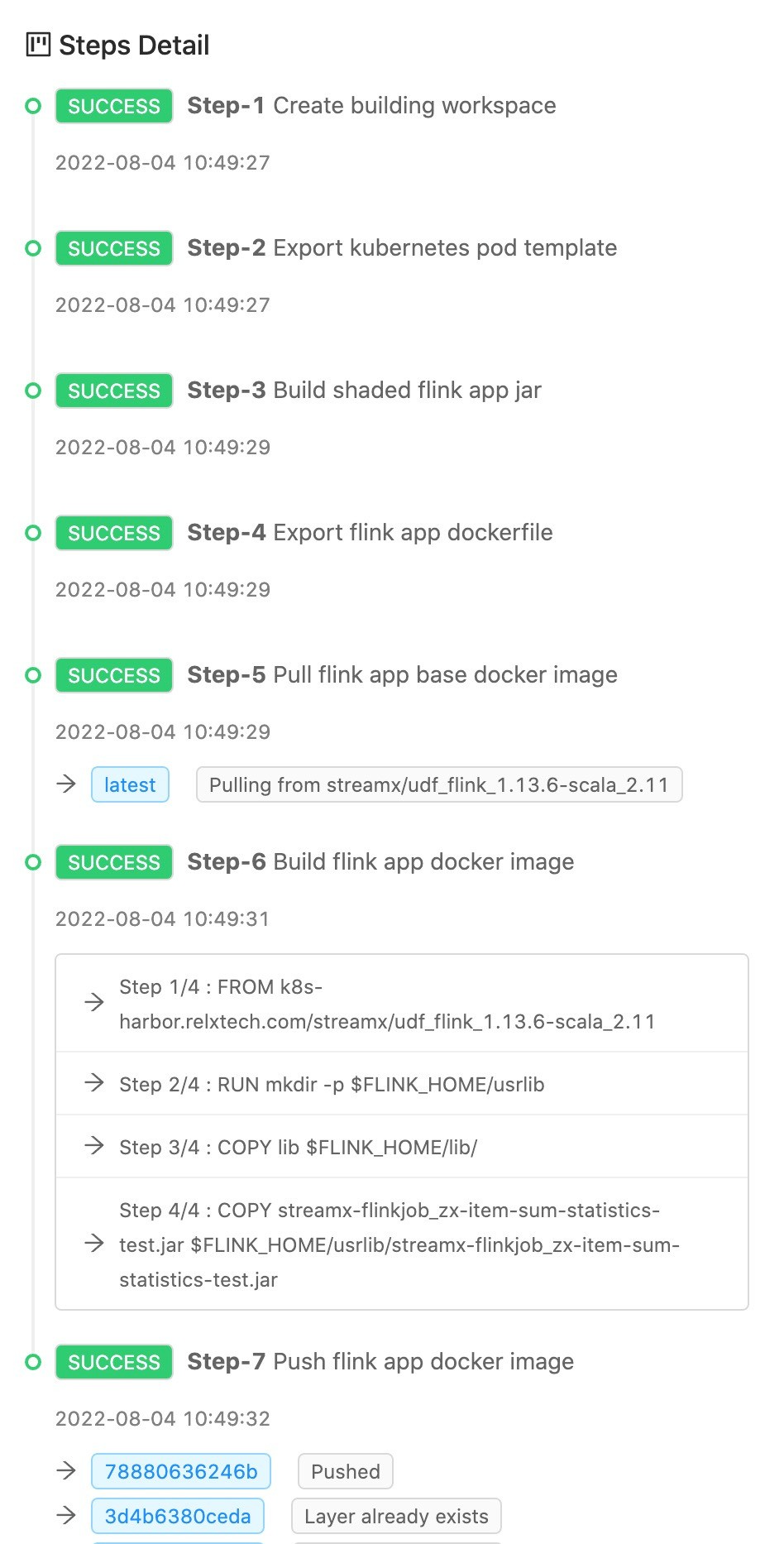
Assignment submission
Finally, you only need to click the start Application button in Operation to start a Flink on Kubernetes job. After the job is successfully started, click on the job name to jump to the Jobmanager WebUI page. The whole process is very simple and smooth.
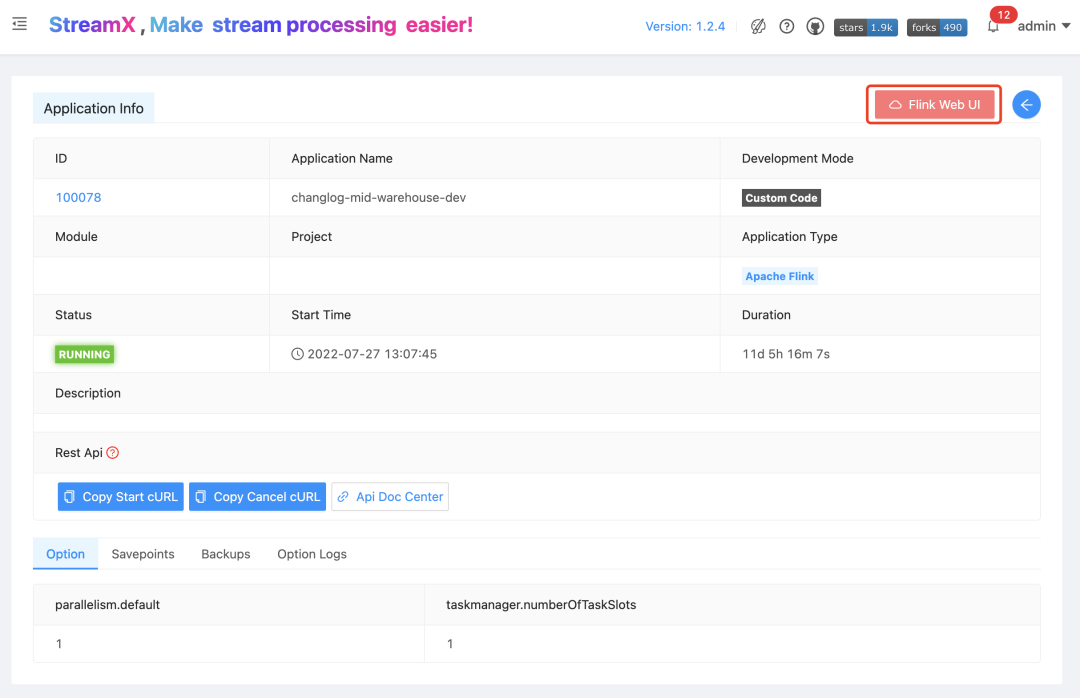
The entire process only requires the above three steps to complete the development and deployment of a Flink on Kubernetes job on StreamPark. StreamPark's support for Flink on Kubernetes goes far beyond simply submitting a task.
Job management
After the job is submitted, StreamPark can obtain the latest checkpoint address of the task, the running status of the task, and the real-time resource consumption information of the cluster in real time. It can very conveniently start and stop the running task with one click, and supports recording the savepoint location when stopping the job. , as well as functions such as restoring the state from savepoint when restarting, thus ensuring the data consistency of the production environment and truly possessing the one-stop development, deployment, operation and maintenance monitoring capabilities of Flink on Kubernetes.
Next, let’s take a look at how StreamPark supports this capability:
-
Record checkpoint in real time
After the job is submitted, sometimes it is necessary to change the job logic but to ensure data consistency, then the platform needs to have the ability to record the location of each checkpoint in real time, as well as the ability to record the last savepoint location when stopped. StreamPark is on Flink on Kubernetes This function is implemented very well. By default, checkpoint information will be obtained and recorded in the corresponding table every 5 seconds, and according to the policy of retaining the number of checkpoints in Flink, only state.checkpoints.num-retained will be retained, and the excess will be deleted. There is an option to check the savepoint when the task is stopped. If the savepoint option is checked, the savepoint operation will be performed when the task is stopped, and the specific location of the savepoint will also be recorded in the table.
The root path of the default savepoint only needs to be configured in the Flink Home flink-conf.yaml file to automatically identify it. In addition to the default address, the root path of the savepoint can also be customized and specified when stopping.
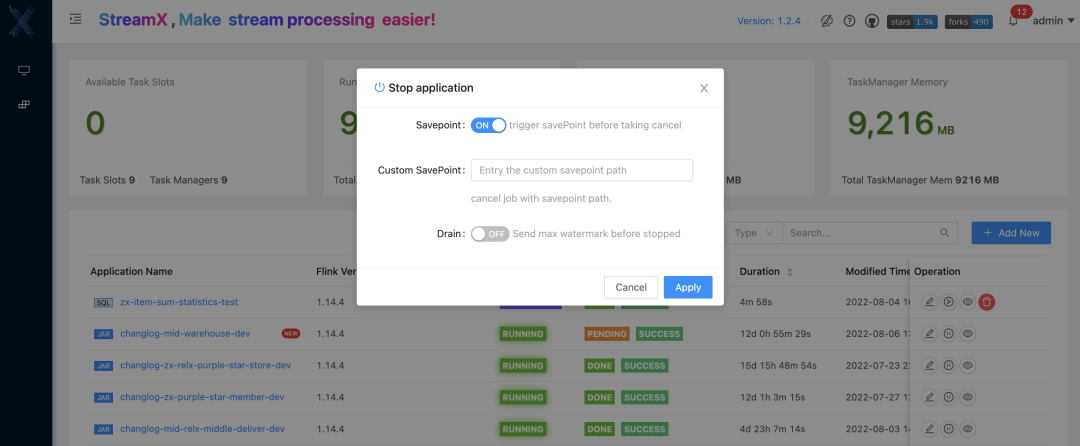
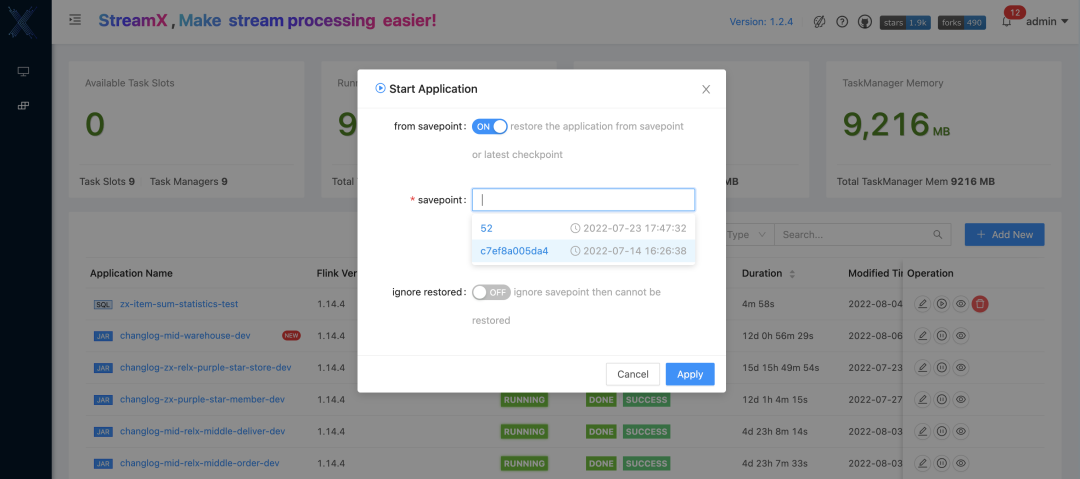
-
Track running status in real time
For challenges in the production environment, a very important point is whether monitoring is in place, especially for Flink on Kubernetes. This is very important and is the most basic capability. StreamPark can monitor the running status of Flink on Kubernetes jobs in real time and display it to users on the platform. Tasks can be easily retrieved based on various running statuses on the page.
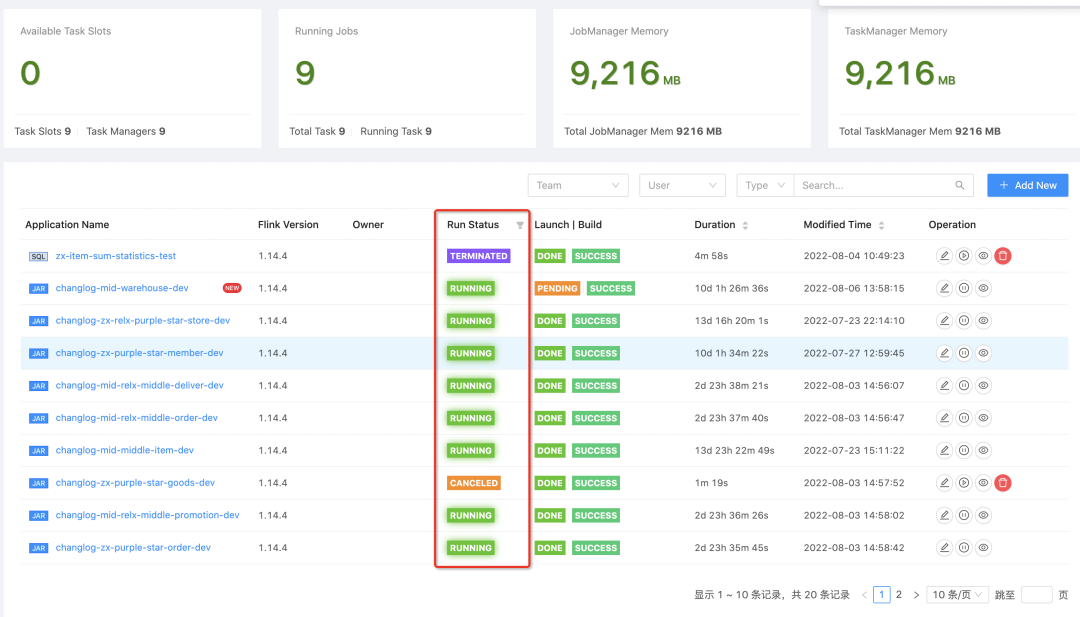
-
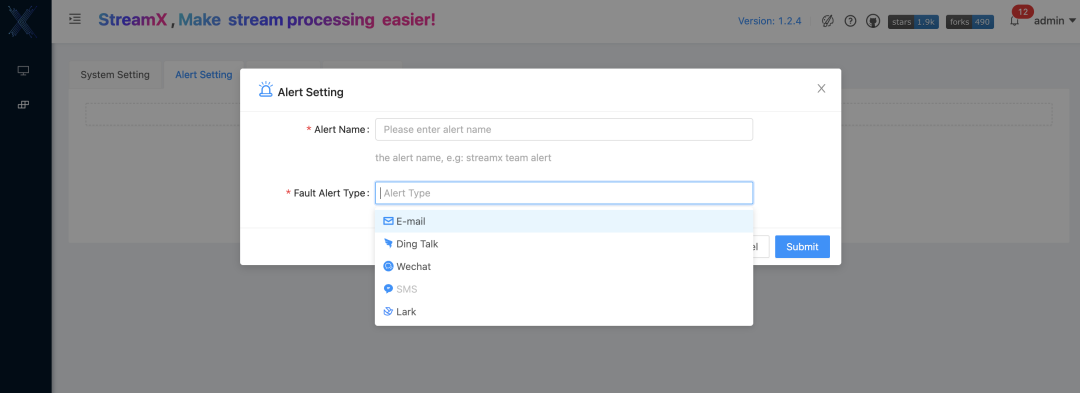
Complete alarm mechanism
In addition, StreamPark also has complete alarm functions: supporting email, DingTalk, WeChat and SMS, etc. This is also an important reason why the company chose StreamPark as the one-stop platform for Flink on Kubernetes after initial research.
From the above, we can see that StreamPark has the capabilities to support the development and deployment process of Flink on Kubernetes, including: ** job development capabilities, deployment capabilities, monitoring capabilities, operation and maintenance capabilities, exception handling capabilities, etc. StreamPark provides a relatively complete set of s solution. And it already has some CICD/DevOps capabilities, and the overall completion level continues to improve. It is a product that supports the full link of Flink on Kubernetes one-stop development, deployment, operation and maintenance work in the entire open source field. StreamPark is worthy of praise. **
Apache StreamPark™’s implementation in Wuxin Technology
StreamPark was launched late in Wuxin Technology. It is currently mainly used for the development and deployment of real-time data integration jobs and real-time indicator calculation jobs. There are Jar tasks and Flink SQL tasks, all deployed using Native Kubernetes; data sources include CDC, Kafka, etc., and Sink end There are Maxcompute, kafka, Hive, etc. The following is a screenshot of the company's development environment StreamPark platform:
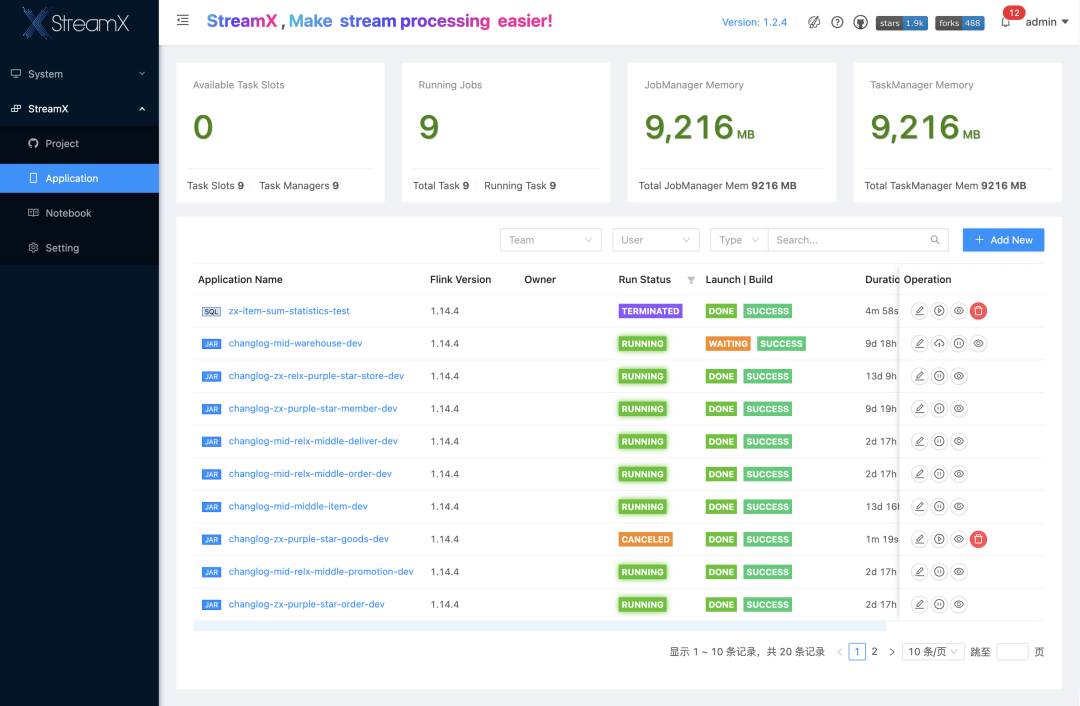
Problems encountered
Any new technology has a process of exploration and fall into pitfalls. The experience of failure is precious. Here are some pitfalls and experiences that StreamPark has stepped into during the implementation of fog core technology. The content of this section is not only about StreamPark. I believe it will bring some reference to all friends who use Flink on Kubernetes.
FAQs are summarized below
-
Kubernetes pod failed to pull the image
The main problem is that Kubernetes pod-template lacks docker’s imagePullSecrets
-
Scala version inconsistent
Since StreamPark deployment requires a Scala environment, and Flink SQL operation requires the Flink SQL Client provided by StreamPark, it is necessary to ensure that the Scala version of the Flink job is consistent with the Scala version of StreamPark.
-
Be aware of class conflicts
When developing Flink SQL jobs, you need to pay attention to whether there are any class conflicts between the Flink image and the Flink connector and UDF. The best way to avoid class conflicts is to make the Flink image and the commonly used Flink connector and user UDF into a usable basic image. After that, other Flink SQL jobs can be reused directly.
-
How to store checkpoint without Hadoop environment?
HDFS, Alibaba Cloud OSS/AWS S3 can both perform checkpoint and savepoint storage. The Flink basic image already has support for OSS and S3. If you do not have HDFS, you can use Alibaba Cloud OSS or S3 to store status and checkpoint and savepoint data. You only need to use Flink Simply configure it in the dynamic parameters.
-Dstate.backend=rocksdb
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-oss-fs-hadoop-1.13.6.jar
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-oss-fs-hadoop-1.13.6.jar
-Dfs.oss.endpoint=xxyy.aliyuncs.com
-Dfs.oss.accessKeyId=xxxxxxxxxx
-Dfs.oss.accessKeySecret=xxxxxxxxxx
-Dstate.checkpoints.dir=oss://realtime-xxx/streamx/dev/checkpoints/
-Dstate.savepoints.dir=oss://realtime-xxx/streamx/dev/savepoints/
-
The changed code did not take effect after it was republished
This issue is related to the Kubernetes pod image pull policy. It is recommended to set the Pod image pull policy to Always:
-Dkubernetes.container.image.pull-policy=Always
-
Each restart of the task will result in one more Job instance
Under the premise that kubernetes-based HA is configured, when you need to stop the Flink task, you need to use cancel of StreamPark. Do not delete the Deployment of the Flink task directly through the kubernetes cluster. Because Flink's shutdown has its own shutdown process, when deleting a pod, the corresponding configuration files in the Configmap will also be deleted. Direct deletion of the pod will result in the remnants of the Configmap. When a task with the same name is restarted, two identical jobs will appear because at startup, the task will load the remaining configuration files and try to restore the closed task.
-
How to implement kubernetes pod domain name access
Domain name configuration only needs to be configured in pod-template according to Kubernetes resources. I can share with you a pod-template.yaml template that I summarized based on the above issues:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
serviceAccount: default
containers:
- name: flink-main-container
image:
imagePullSecrets:
- name: regsecret
hostAliases:
- ip: "192.168.0.1"
hostnames:
- "node1"
- ip: "192.168.0.2"
hostnames:
- "node2"
- ip: "192.168.0.3"
hostnames:
- "node3"
Best Practices
Many of RELX's big data components are based on Alibaba Cloud, such as Maxcompute and Alibaba Cloud Redis. At the same time, our Flink SQL jobs need to use some UDFs. At first, we adopted the method of using Flink Base image + maven dependency + upload udf jar, but in practice we encountered some problems such as version conflicts and class conflicts. At the same time, if it is a large-volume job, the development efficiency of this method is relatively low. Finally, we packaged the commonly used Flink connectors, udf and Flink base image at the company level into a company-level base image. New Flink SQL jobs can directly write Flink SQL after using this base image, which greatly improves development efficiency.
Let’s share a simple step to create a basic image:
1. Prepare the required JAR
Place the commonly used Flink Connector Jar and the user Udf Jar in the same folder lib. The following are some commonly used connector packages in Flink 1.13.6
bigdata-udxf-1.0.0-shaded.jar
flink-connector-jdbc_2.11-1.13.6.jar
flink-sql-connector-kafka_2.11-1.13.6.jar
flink-sql-connector-mysql-cdc-2.0.2.jar
hudi-flink-bundle_2.11-0.10.0.jar
ververica-connector-odps-1.13-vvr-4.0.7.jar
ververica-connector-redis-1.13-vvr-4.0.7.jar
2. Prepare Dockerfile
Create a Dockerfile file and place the Dockerfile file in the same folder as the above folder
FROM flink:1.13.6-scala_2.11COPY lib $FLINK_HOME/lib/
3. Create a basic image and push it to a private repository
docker login --username=xxxdocker \
build -t udf_flink_1.13.6-scala_2.11:latest \
.docker tag udf_flink_1.13.6-scala_2.11:latest \
k8s-harbor.xxx.com/streamx/udf_flink_1.13.6-scala_2.11:latestdocker \
push k8s-harbor.xxx.com/streamx/udf_flink_1.13.6-scala_2.11:latest
Future Expectations
-
StreamPark supports Flink job metric monitoring
It would be great if StreamPark could connect to Flink Metric data and display Flink’s real-time consumption data at every moment on the StreamPark platform.
-
StreamPark supports Flink job log persistence
For Flink deployed to YARN, if the Flink program hangs, we can go to YARN to view the historical logs. However, for Kubernetes, if the program hangs, the Kubernetes pod will disappear and there will be no way to check the logs. Therefore, users need to use tools on Kubernetes for log persistence. It would be better if StreamPark supports the Kubernetes log persistence interface.
-
Improvement of the problem of too large image
StreamPark's current image support for Flink on Kubernetes jobs is to combine the basic image and user code into a Fat image and push it to the Docker repository. The problem with this method is that it takes a long time when the image is too large. It is hoped that the basic image can be restored in the future. There is no need to hit the business code together every time, which can greatly improve development efficiency and save costs.