Although the Hadoop system is widely used today, its architecture is complicated, it has a high maintenance complexity, version upgrades are challenging, and due to departmental reasons, data center scheduling is prolonged. We urgently need to explore agile data platform models. With the current popularization of cloud-native architecture and the integration between lake and warehous, we have decided to use Doris as an offline data warehouse and TiDB (which is already in production) as a real-time data platform. Furthermore, because Doris has ODBC capabilities on MySQL, it can integrate external database resources and uniformly output reports.
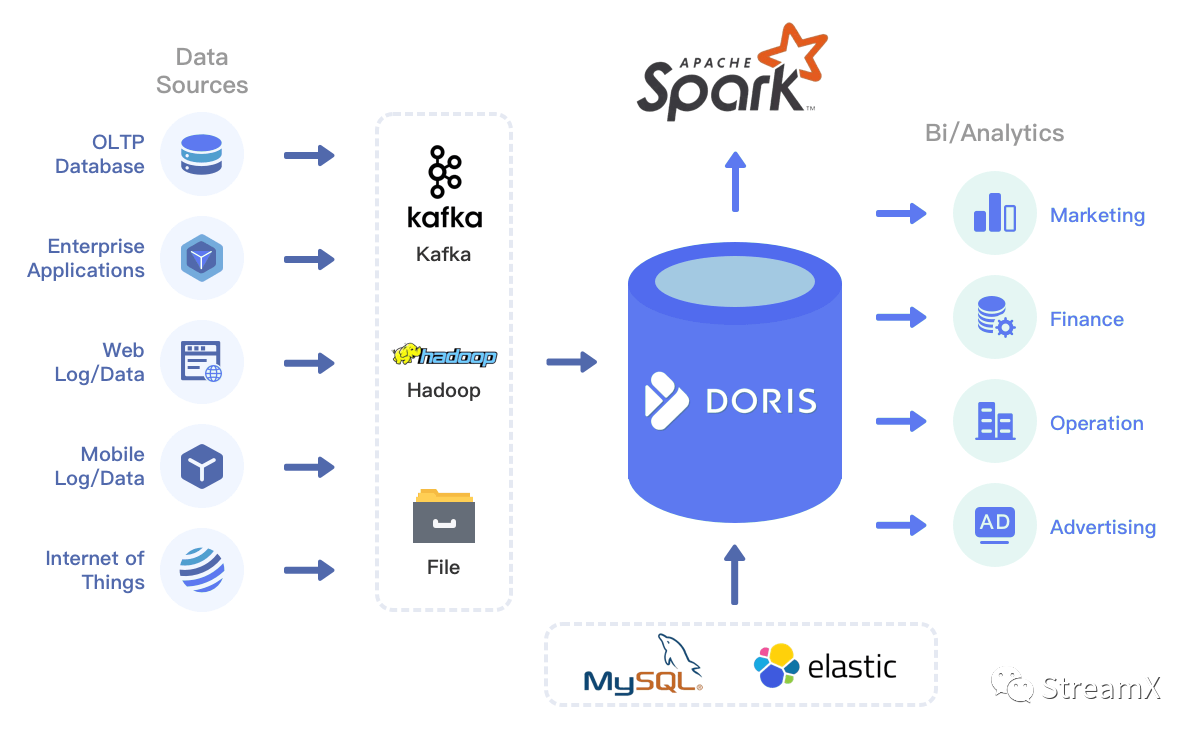
Although the Hadoop system is widely used today, its architecture is complicated, it has a high maintenance complexity, version upgrades are challenging, and due to departmental reasons, data center scheduling is prolonged. We urgently need to explore agile data platform models. With the current popularization of cloud-native architecture and the integration between lake and warehous, we have decided to use Doris as an offline data warehouse and TiDB (which is already in production) as a real-time data platform. Furthermore, because Doris has ODBC capabilities on MySQL, it can integrate external database resources and uniformly output reports.
2. Challenges Faced
For the data engine, we settled on using Spark and Flink:
- Use Spark on K8s client mode for offline data processing.
- Use Flink on K8s Native-Application/Session mode for real-time task stream management.
Here, there are some challenges we haven't fully resolved:
Those who have used the Native-Application mode know that each time a task is submitted, a new image must be packaged, pushed to a private repository, and then the Flink Run command is used to communicate with K8s to pull the image and run the Pod. After the task is submitted, you need to check the log on K8s, but:
- How is task runtime monitoring handled?
- Do you use Cluster mode or expose ports using NodePort to access Web UI?
- Can the task submission process be simplified to avoid image packaging?
- How can we reduce the pressure on developers?
3. Solving the Challenges
All of the above are challenges that need addressing. If we rely solely on the command line to submit each task, it becomes unrealistic. As the number of tasks increases, it becomes unmanageable. Addressing these challenges became inevitable.
Simplifying Image Building
Firstly, regarding the need for a secondary build of the native Flink image: we utilized MinIO as external storage and mounted it directly on each host node using s3-fuse via DaemonSet. The jar packages we need to submit can all be managed there. In this way, even if we scale the Flink nodes up or down, S3 mounts can automatically scale.
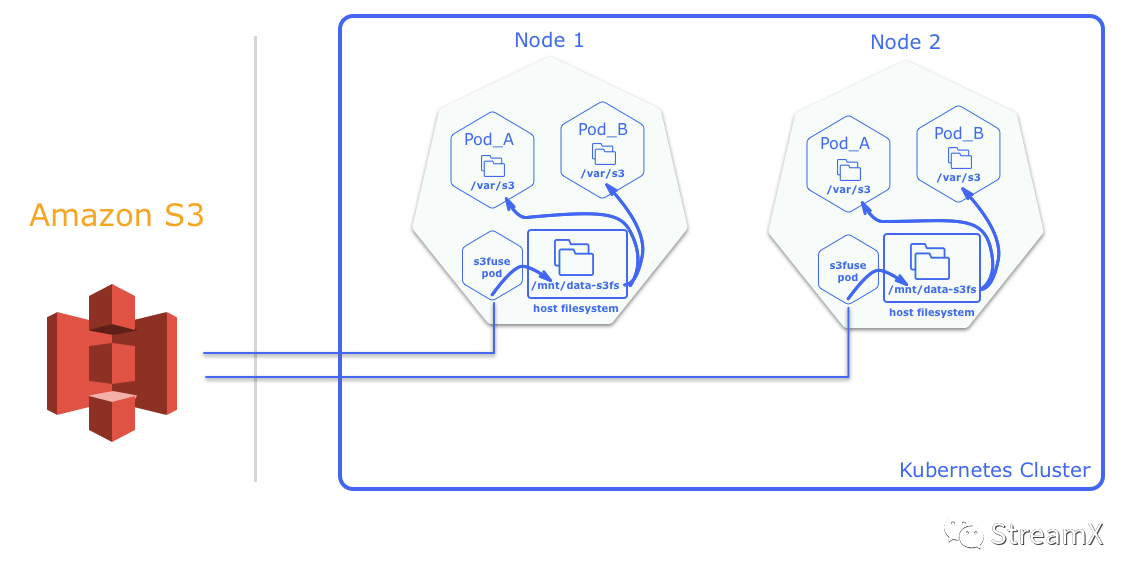
From Flink version 1.13 onwards, Pod Template support has been added. We can use volume mounts in the Pod Template to mount host directories into each pod, allowing Flink programs to run directly on K8s without packaging them into images. As shown in the diagram above, we first mount S3 using the s3-fuse Pod to the /mnt/data-s3fs directory on Node 1 and Node 2, and then mount /mnt/data-s3fs into Pod A.
However, because object storage requires the entire object to be rewritten for random writes or file appends, this method is only suitable for frequent reads. This perfectly fits our current scenario.
Introducing Apache StreamPark™
Previously, when we wrote Flink SQL, we generally used Java to wrap SQL, packed it into a jar package, and submitted it to the S3 platform through the command line. This approach has always been unfriendly; the process is cumbersome, and the costs for development and operations are too high. We hoped to further streamline the process by abstracting the Flink TableEnvironment, letting the platform handle initialization, packaging, and running Flink tasks, and automating the building, testing, and deployment of Flink applications.
This is an era of open-source uprising. Naturally, we turned our attention to the open-source realm: among numerous open-source projects, after comparing various projects, we found that both Zeppelin and StreamPark provide substantial support for Flink and both claim to support Flink on K8s. Eventually, both were shortlisted for our selection. Here's a brief comparison of their support for K8s (if there have been updates since, please kindly correct).
| Feature | Zeppelin | StreamPark |
| Task Status Monitoring | Somewhat limited, not suitable as a task status monitoring tool. | Highly capable |
| Task Resource Management | None | Exists, but the current version is not very robust. |
| Local Deployment | On the lower side. In on K8s mode, you can only deploy Zeppelin in K8s. Otherwise, you need to connect the Pod and external network, which is rarely done in production. | Can be deployed locally |
| Multi-language Support | High - Supports multiple languages such as Python/Scala/Java. | Average - Currently, K8s mode and YARN mode support FlinkSQL, and based on individual needs, you can use Java/Scala to develop DataStream. |
| Flink WebUI Proxy | Currently not very comprehensive. The main developer is considering integrating Ingress. | Good - Currently supports ClusterIp/NodePort/LoadBalance modes. |
| Learning Curve | Low cost. Needs to learn additional parameters, which differ somewhat from native FlinkSQL. | No cost. In K8s mode, FlinkSQL is supported in its native SQL format; also supports Custom-Code (user writes code for developing Datastream/FlinkSQL tasks). |
| Support for Multiple Flink Versions | Supported | Supported |
| Intrusion into Native Flink Image | Invasive. You need to pre-deploy the jar package in the Flink image, which will start in the same Pod as JobManager and communicate with the zeppelin-server. | Non-invasive, but it will generate many images that need to be cleaned up regularly. |
| Multi-version Code Management | Supported | Supported |
During our research process, we communicated with the main developers of both tools multiple times. After our repeated studies and assessments, we eventually decided to adopt StreamPark as our primary Flink development tool for now.
After extended development and testing by our team, StreamPark currently boasts:
- Comprehensive SQL validation capabilities
- It has achieved automatic build/push for images
- Using a custom class loader and through the Child-first loading method, it addresses both YARN and K8s operational modes and supports the seamless switch between multiple Flink versions
- It deeply integrates with Flink-Kubernetes, returning a WebUI after task submission, and via remote REST API + remote K8s, it can track task execution status
- It supports versions like Flink 1.12, 1.13, 1.14, and more
This effectively addresses most of the challenges we currently face in development and operations.
In its latest release, version 1.2.0, StreamPark provides robust support for both K8s-Native-Application and K8s-Session-Application modes.
K8s Native Application Mode
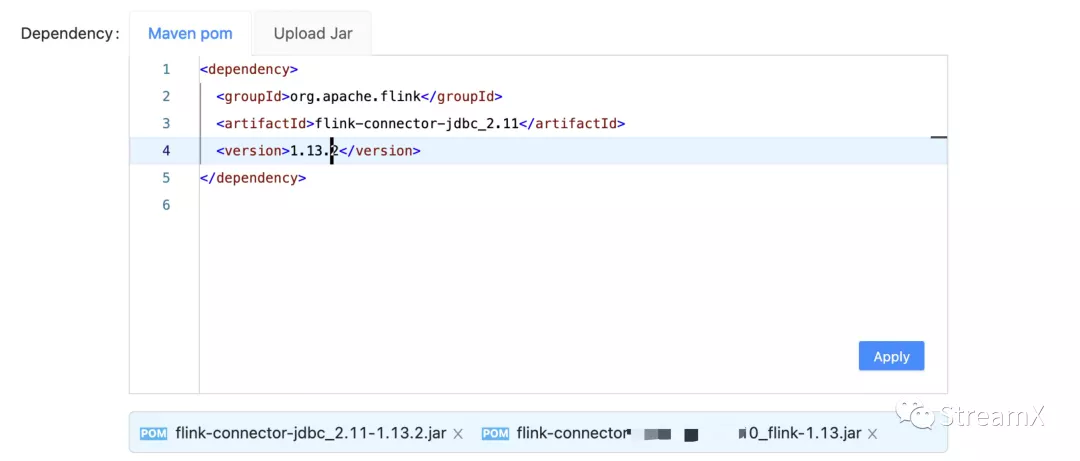
Within StreamPark, all we need to do is configure the relevant parameters, fill in the corresponding dependencies in the Maven POM, or upload the dependency jar files. Once we click on 'Apply', the specified dependencies will be generated. This implies that we can also compile all the UDFs we use into jar files, as well as various connector.jar files, and use them directly in SQL. As illustrated below:
The SQL validation capability is roughly equivalent to that of Zeppelin:
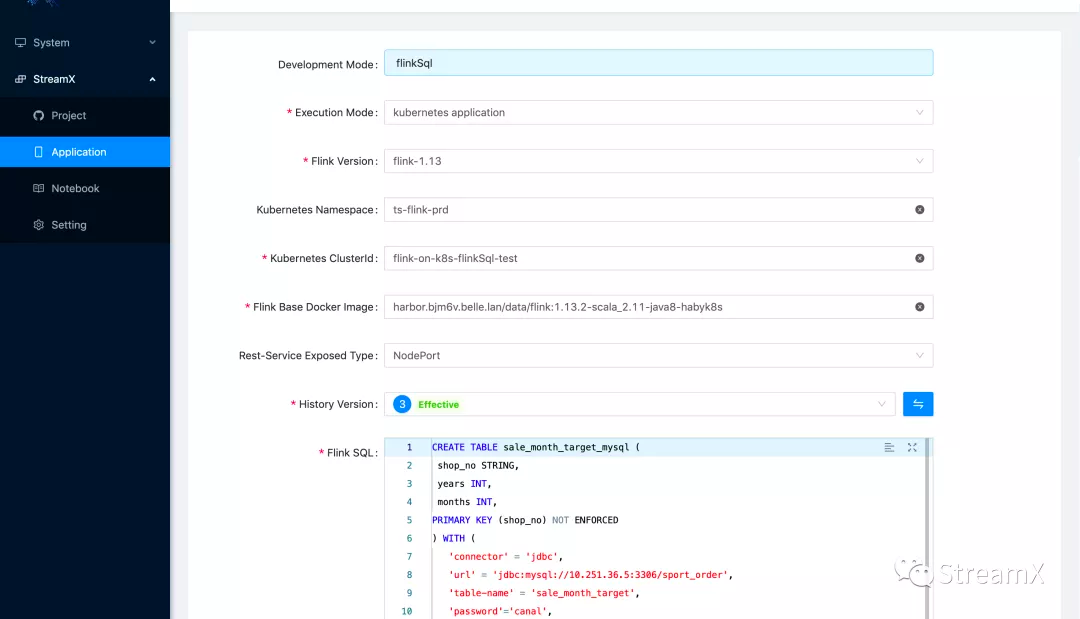
We can also specify resources, designate dynamic parameters within Flink Run as Dynamic Options, and even integrate these parameters with a Pod Template.
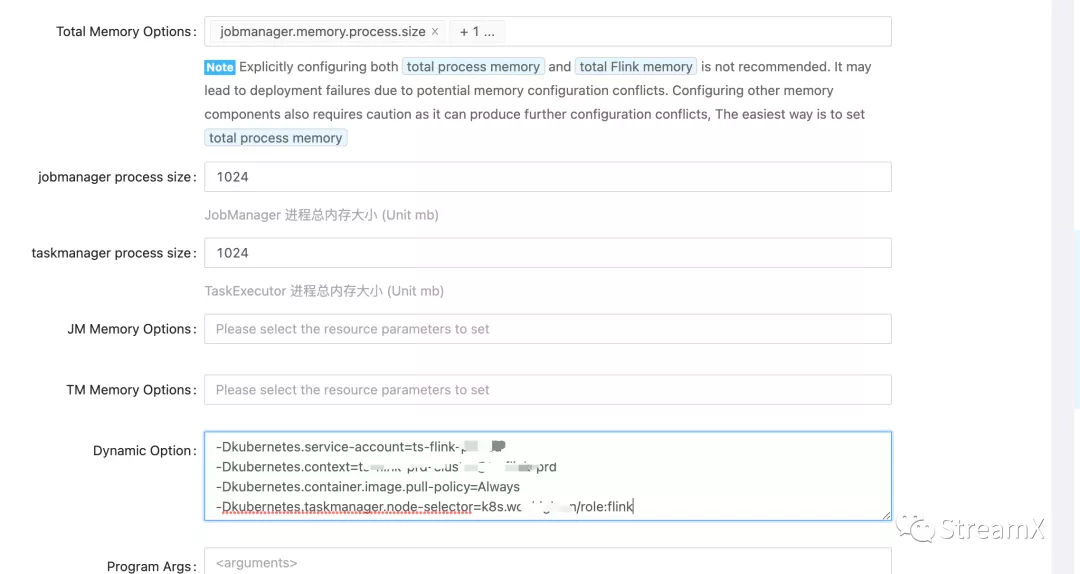
After saving the program, when clicking to run, we can also specify a savepoint. Once the task is successfully submitted, StreamPark will, based on the FlinkPod's network Exposed Type (be it loadBalancer, NodePort, or ClusterIp), return the corresponding WebURL, seamlessly enabling a WebUI redirect. However, as of now, due to security considerations within our online private K8s cluster, there hasn't been a connection established between the Pod and client node network (and there's currently no plan for this). Hence, we only employ NodePort. If the number of future tasks increases significantly, and there's a need for ClusterIP, we might consider deploying StreamPark in K8s or further integrate it with Ingress.
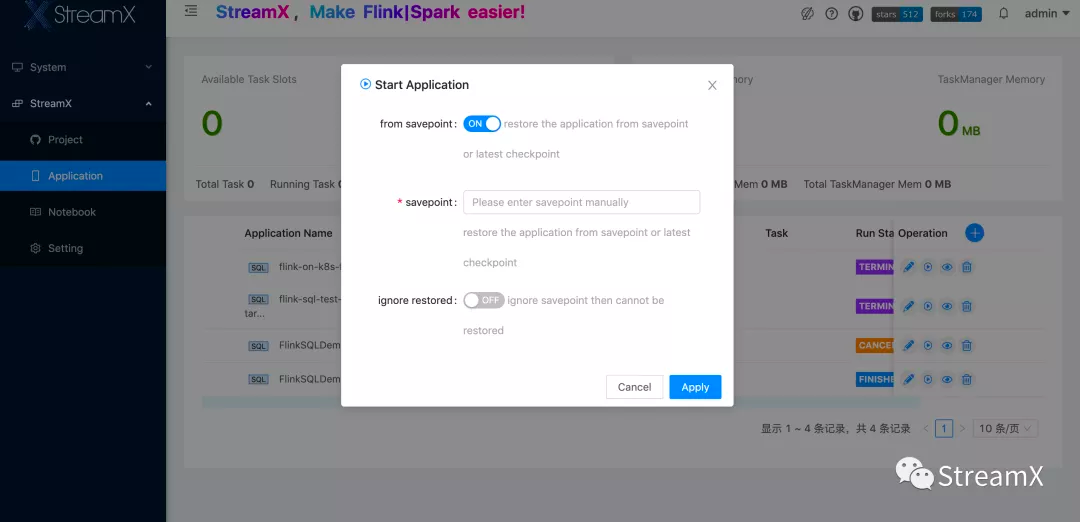
Note: If the K8s master uses a vip for load balancing, the Flink 1.13 version will return the vip's IP address. This issue has been rectified in the 1.14 version.
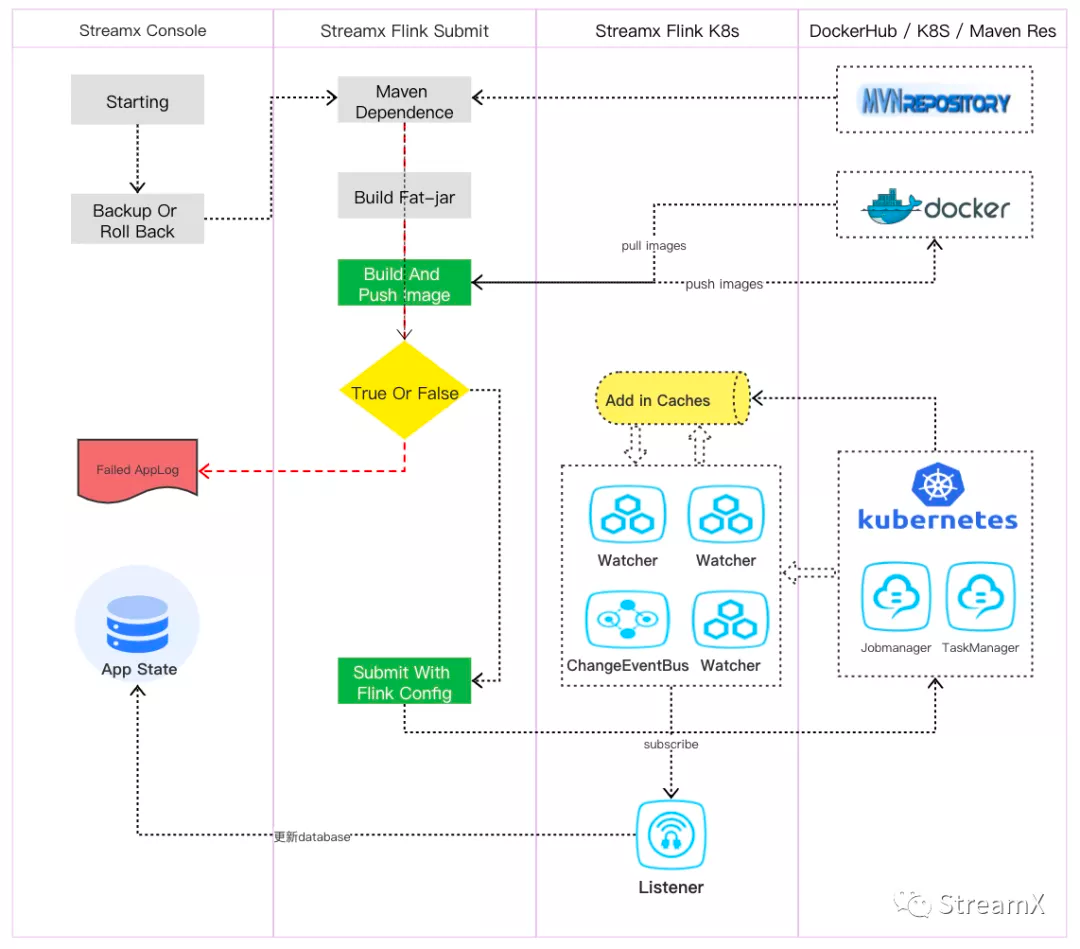
Below is the specific submission process in the K8s Application mode:
K8s Native Session Mode
StreamPark also offers robust support for the K8s Native-Session mode, which lays a solid technical foundation for our subsequent offline FlinkSQL development or for segmenting certain resources.
To use the Native-Session mode, one must first use the Flink command to create a Flink cluster that operates within K8s. For instance:
./kubernetes-session.sh \
-Dkubernetes.cluster-id=flink-on-k8s-flinkSql-test \
-Dkubernetes.context=XXX \
-Dkubernetes.namespace=XXXX \
-Dkubernetes.service-account=XXXX \
-Dkubernetes.container.image=XXXX \
-Dkubernetes.container.image.pull-policy=Always \
-Dkubernetes.taskmanager.node-selector=XXXX \
-Dkubernetes.rest-service.exposed.type=Nodeport
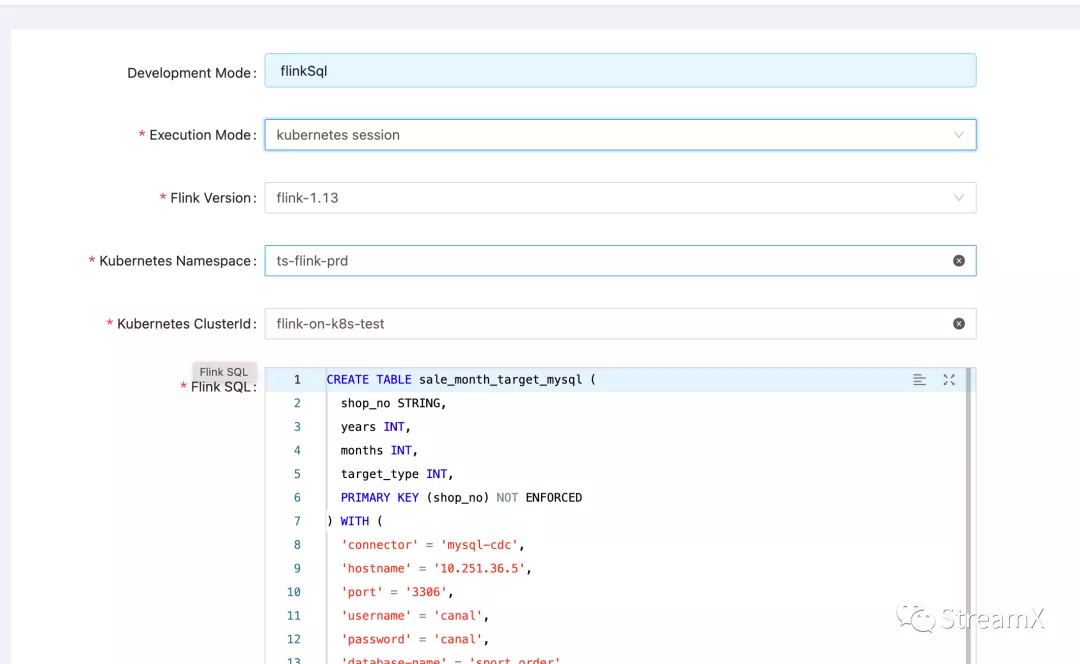
As shown in the image above, we use that ClusterId as the Kubernetes ClusterId task parameter for StreamPark. Once the task is saved and submitted, it quickly transitions to a 'Running' state:
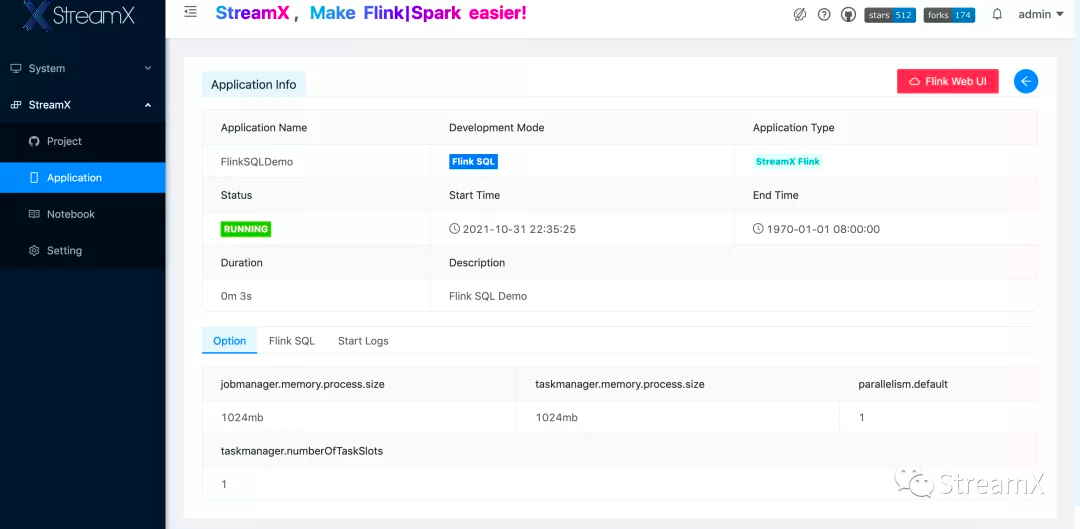
Following the application info's WebUI link:
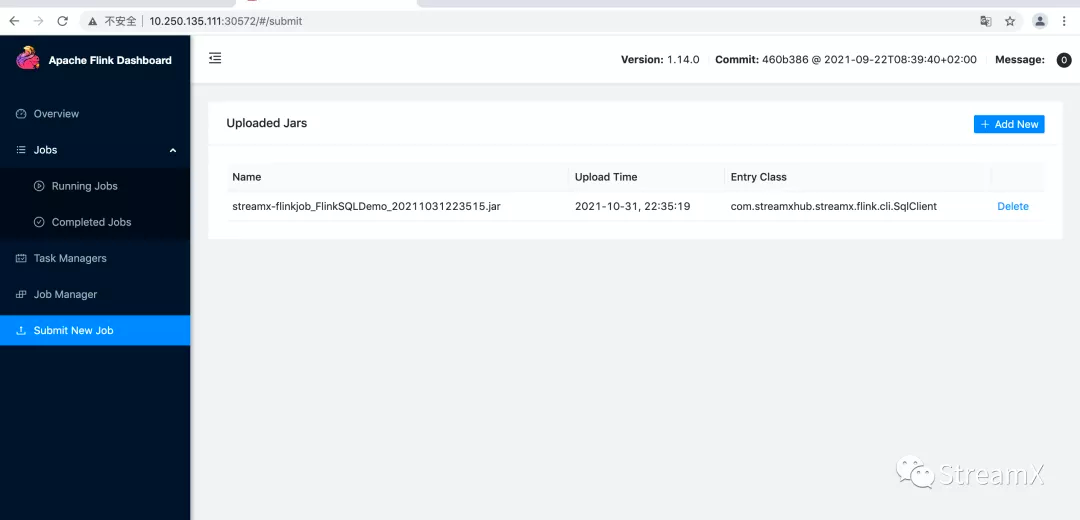
It becomes evident that StreamPark essentially uploads the jar package to the Flink cluster through REST API and then schedules the task for execution.
Custom Code Mode
To our delight, StreamPark also provides support for coding DataStream/FlinkSQL tasks. For special requirements, we can achieve our implementations in Java/Scala. You can compose tasks following the scaffold method recommended by StreamPark or write a standard Flink task. By adopting this approach, we can delegate code management to git, utilizing the platform for automated compilation, packaging, and deployment. Naturally, if functionality can be achieved via SQL, we would prefer not to customize DataStream, thereby minimizing unnecessary operational complexities.
4. Feedback and Future Directions
Suggestions for Improvement
StreamPark, similar to any other new tools, does have areas for further enhancement based on our current evaluations:
- Strengthening Resource Management: Features like multi-file system jar resources and robust task versioning are still awaiting additions.
- Enriching Frontend Features: For instance, once a task is added, functionalities like copying could be integrated.
- Visualization of Task Submission Logs: The process of task submission involves loading class files, jar packaging, building and submitting images, and more. A failure at any of these stages could halt the task. However, error logs are not always clear, or due to some anomaly, the exceptions aren't thrown as expected, leaving users puzzled about rectifications.
It's a universal truth that innovations aren't perfect from the outset. Although minor issues exist and there are areas for improvement with StreamPark, its merits outweigh its limitations. As a result, we've chosen StreamPark as our Flink DevOps platform. We're also committed to collaborating with its main developers to refine StreamPark further. We wholeheartedly invite others to use it and contribute towards its advancement.
Future Prospects
- We'll keep our focus on Doris and plan to unify business data with log data in Doris, leveraging Flink to realize lakehouse capabilities.
- Our next step is to explore integrating StreamPark with DolphinScheduler 2.x. This would enhance DolphinScheduler's offline tasks, and gradually we aim to replace Spark with Flink for a unified batch-streaming solution.
- Drawing from our own experiments with S3, after building the fat-jar, we're considering bypassing image building. Instead, we'll mount PVC directly to the Flink Pod's directory using Pod Template, refining the code submission process even further.
- We plan to persistently implement StreamPark in our production environment. Collaborating with community developers, we aim to boost StreamPark's Flink stream development, deployment, and monitoring capabilities. Our collective vision is to evolve StreamPark into a holistic stream data DevOps platform.
Resources:
StreamPark GitHub: https://github.com/apache/streampark
Doris GitHub: https://github.com/apache/doris
