
Introduction:This article mainly introduces the architecture upgrade and evolution of the self-migrating MySQL data to Hive, the original architecture involves many components, complex links, and encounters many challenges, and effectively solves the dilemmas and challenges encountered in data integration after using the combination of StreamPark + Paimon, and shares the specific practical solutions of StreamPark + Paimon in practical applications, as well as the advantages and benefits brought by this rookie combination solution.
StreamPark: https://github.com/apache/streampark
Paimon: https://github.com/apache/paimon
Welcome to follow, star, fork, and participate in contributions
Contributor|Beijing Ziru Information Technology Co., Ltd.
Authors of the article|Liu Tao, Liang Yansheng, Wei Linzi
Article compilation|Yang Linwei
Content proofreading|Pan Yuepeng
1.Data integration business background
The data integration scenario of Ziroom's rental business mainly comes from the need to synchronize MySQL tables of each business line to Hive tables. This requirement includes more than 4,400 MySQL business tables synchronized every day and more than 8,000 Hive ETL processing tasks. The amount of new data generated every day is 50T, and these numbers are still growing. According to the freshness requirements of the data, it is divided into two types: low freshness (T+1 day) and high freshness (T+10 minutes). More than 4,000 low freshness data tables are synchronously scheduled every day, and more than 400 high freshness data tables are synchronously scheduled every day. Freshness data table to ensure the timeliness and accuracy of data.
Ziroom's data integration solutions can be mainly divided into two types according to business usage scenarios:
-
Low freshness: The timeliness requirement of low freshness for data is T+1day, and the Hive jdbc handler is used to pull the full amount of MySQL data to Hive at 00:00 every day. The basic The process is shown in the figure below:

-
High freshness: In this scenario, the required data effectiveness is T+10minutes. We reused the snapshot pull method of the low freshness scenario to obtain the full amount of data and initialized it to MySQL. Synchronously use Canal to parse the logs and collect them into Kafka, then use Flink to read the data in kafka and write it to HDFS, and finally use Airflow for scheduling to merge the incremental data into Hive. The basic logic is as follows:

However, there are many challenges and pressures in the current architecture. Firstly, the operation and maintenance costs are high, and secondly, the computing pressure, storage pressure and network pressure are all very high. In addition, although the resources are underutilized during the system running time from 0:00 to 1:00, other time periods face resource shortages. In this regard, Ziroom decided to update the data integration architecture to improve the efficiency and stability of the system.
2.Challenges encountered
In the above two scenarios, we encountered the following challenges during the data integration process:
-
Network bandwidth overload problem: Since the pull task reached 4000+, too many mirror full data pulls put great pressure on the database network bandwidth.
-
Inefficient resource utilization: After the upstream data is synchronized from MySQL to the ODS layer table, the downstream processing table can be started. As a result, the CPU and memory resources of the Hadoop cluster are not available between 0:00 and 1:00. be fully utilized.
-
High maintenance costs: When the database table structure changes, the Airflow script needs to be modified simultaneously. Otherwise, incomplete fields will appear, causing online data anomalies.
-
Difficulty in troubleshooting: The data link is long. When data anomalies occur, troubleshooting costs are high. The problem may occur in any link in Canal, Kafka, Flink, and Airflow scheduling, resulting in a long recovery time. .
-
Flink jobs are difficult to manage in a unified manner: Flink itself does not provide good deployment and development capabilities. As the number of Flink tasks increases, the time cost of management and maintenance also increases.
In order to solve the above problems, after a series of investigations, we decided to adopt the "StreamPark+Paimon" strategy. So what are the reasons for choosing them? We can first look at their characteristics.
Paimon’s core features
After research and comprehensive evaluation of several data lake frameworks such as Apache Hudi/Iceberg/Paimon, we decided to use Apache Paimon. Apache Paimon is a streaming data lake storage technology that can provide users with high throughput and low cost. Delayed data ingestion, streaming subscription and real-time query capabilities support the use of Flink and Spark to build a real-time Lakehouse architecture, support batch/stream data processing operations, innovatively combine the Lake format with the LSM structure, and provide real-time streaming updates. Introducing into the Lake architecture has the following advantages:
-
Unified batch and stream processing: Paimon supports batch writing, batch reading and streaming operations, providing flexible data processing methods.
-
Data Lake Features: As a data lake storage system, Paimon has the characteristics of low cost, high reliability and scalable metadata.
-
Rich merging engines: Paimon provides a variety of merging engines, and you can choose to retain the latest data, perform partial updates, or perform aggregation operations according to your needs.
-
Automatically generate change logs: Paimon supports a variety of Changelog producers and can automatically generate correct and complete change logs to simplify streaming task analysis.
-
Rich table types: Paimon supports primary key tables and append-only tables, as well as multiple table types such as internal tables, external tables, partitioned tables, and temporary tables.
-
Support table structure change synchronization: When the data source table structure changes, Paimon can automatically identify and synchronize these changes.
Paimon can be used in conjunction with Apache Spark. Our scenario is Paimon combined with Flink. In this way, "How to manage 4000+ Flink data synchronization jobs" will be a new problem we face. After a comprehensive investigation of related projects and a comprehensive evaluation of various dimensions, we decided to use StreamPark. So why did we choose StremaPark?
StreamPark’s core features
Apache StreamPark is a stream processing development and management framework that provides a set of fast APIs for developing Flink/Spark jobs. In addition, it also provides a one-stop stream processing job development and management platform, covering the entire life cycle from stream processing job development to launch. Cycles are supported. StreamPark mainly includes the following core features:
-
Stream processing application development framework: Based on StreamPark, developers can easily build and manage stream processing applications, and better utilize Apache Flink® to write stream processing applications.
-
Perfect management capabilities: StreamPark provides a one-stop streaming task development and management platform that supports the full life cycle of Flink/Spark from application development to debugging, deployment, operation and maintenance, allowing Flink/Spark jobs to Make it simple.
-
High degree of completion: StreamPark supports multiple versions of Flink, allowing flexible switching of one platform. It also supports Flink’s deployment mode, effectively solving the problem of too cumbersome Flink on YARN/K8s deployment. Through automated processes, It simplifies the process of building, testing and deploying tasks and improves development efficiency.
-
Rich management API: StreamPark provides APIs for job operations, including job creation, copy, build, deployment, stop and start based on checkpoint/savepoint, etc., making it easy to implement external system calls to Apache Flink® tasks. .
3. StreamPark + Paimon Practice
Next, we will continue to share how Ziroom optimized the architecture based on StreamPark + Paimon. Let’s first look at the comparison before and after the architecture upgrade.
3.1 Before architecture upgrade
The system interaction process of the data integration module before the transformation is as follows:
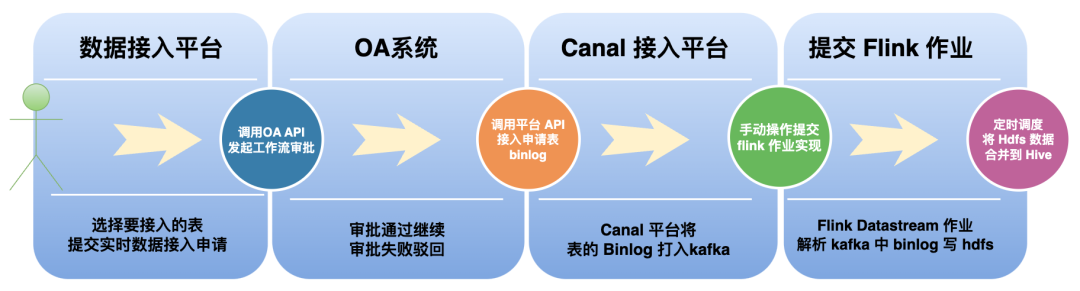
Step1 (User initiates access application): First, the user selects a table on the data access platform, and then clicks the Apply for Access button:
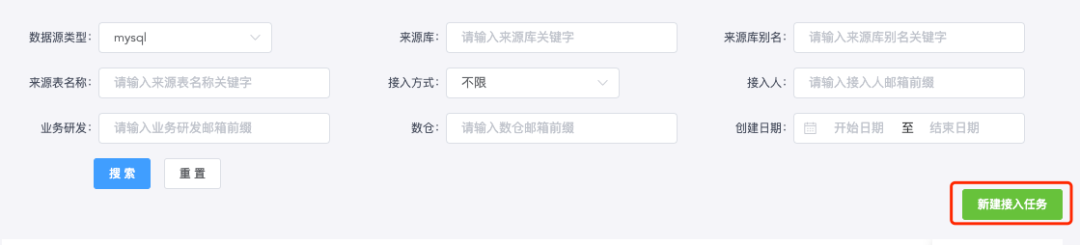
Step2 (Initiate OA system approval process): When the OA system receives the access application, it will initiate workflow approval. If the approval fails, the application will be rejected. Only if the approval is passed will the next step be continued.
Step3 (The data access platform processes the approval event): The data access platform calls the Canal interface to deploy the Canal task and transfer the Binlog data in the table to Kafka:
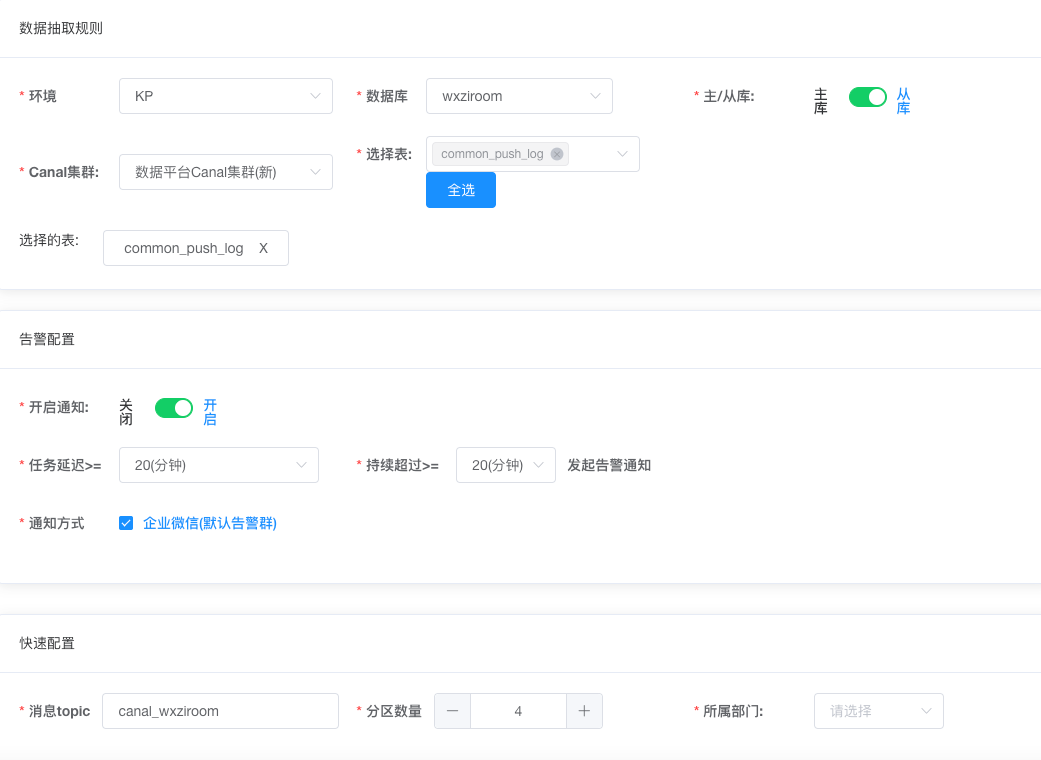
Step4 (Flink task deployment): Manually use the Flink Session Submit UI to deploy the Flink template job, which is responsible for parsing the Binlog change data in Kafka, writing the data to HDFS, and mapping it into a Hive external incremental table:
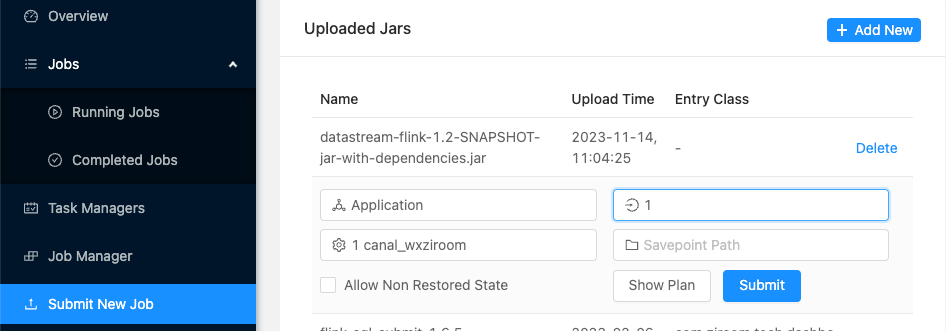
Step5 (Airflow scheduling initialization table): Create Hive mapping incremental table and full table and use Airflow scheduling to complete the first initialization:
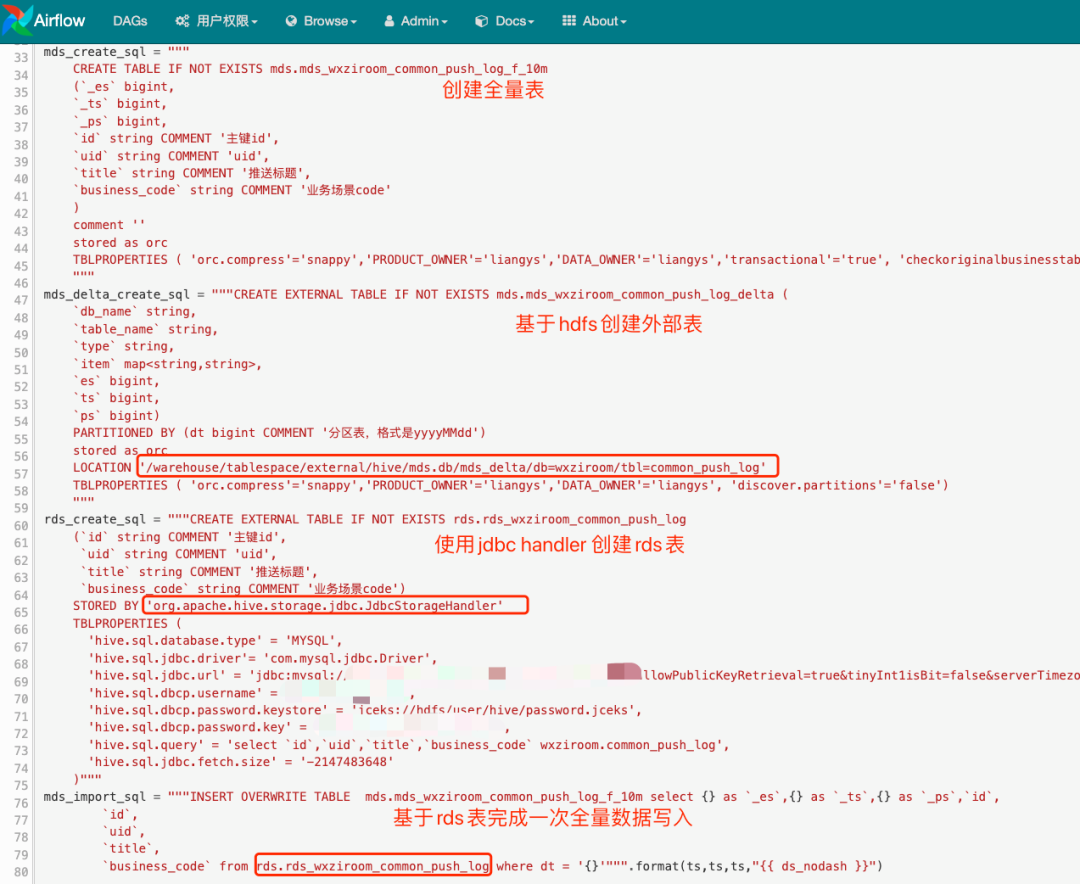
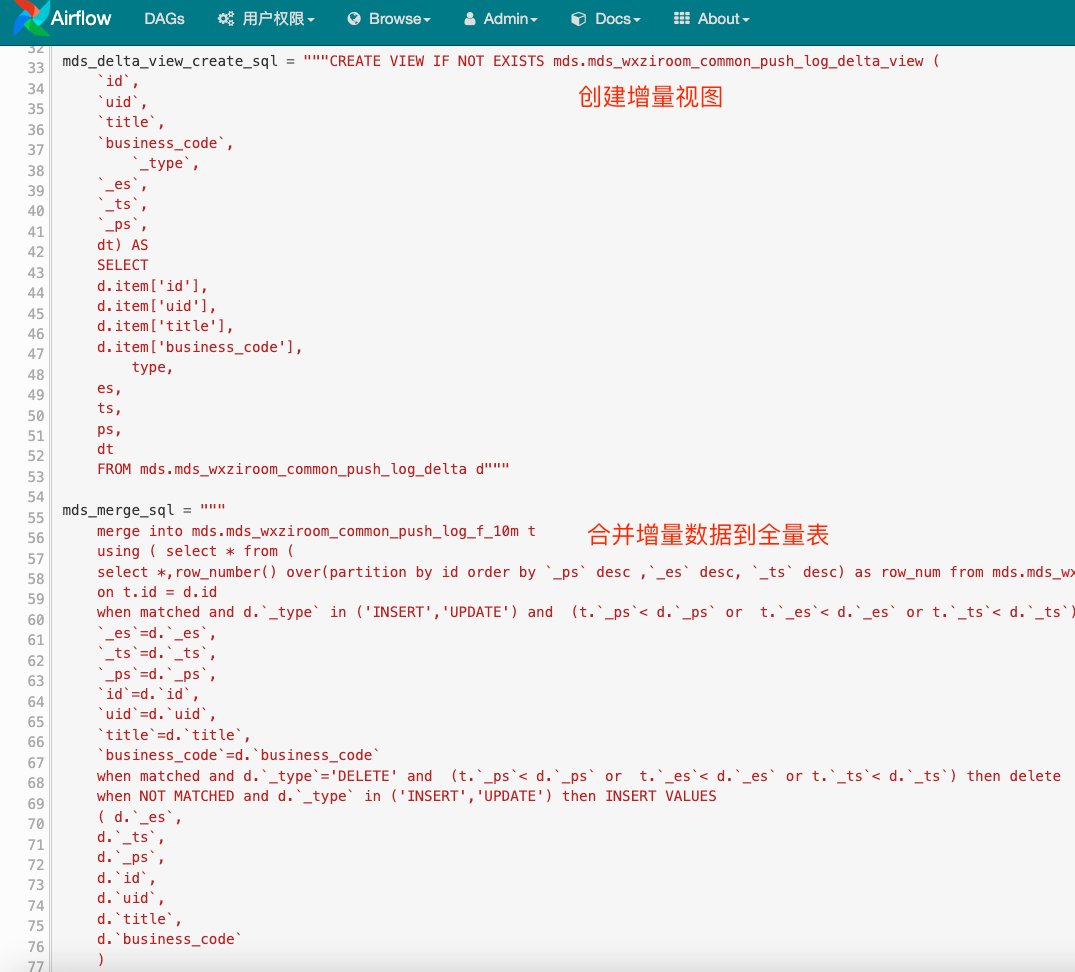
Step6 (Merge data into Hive full table): Configure scheduling to merge data from Hive external incremental tables into Hive full table through Hive Merge method
3.2 After the architecture upgrade
The modified system interaction flow chart is as follows:
![]()
Comparing the interaction flow charts before and after the transformation, it can be seen that the process of the first two steps (table access application and approval) is the same, but the only difference is the event monitoring and processing method after the approval is passed.
-
Before transformation: Call the Canal interface to deploy Canal tasks (old logic);
-
After transformation: Call StreamPark’s API interface to complete Flink Paimon’s task deployment.
Next, let’s look at using Paimon to complete data integration.
3.3 Paimon implements one-key Hive input
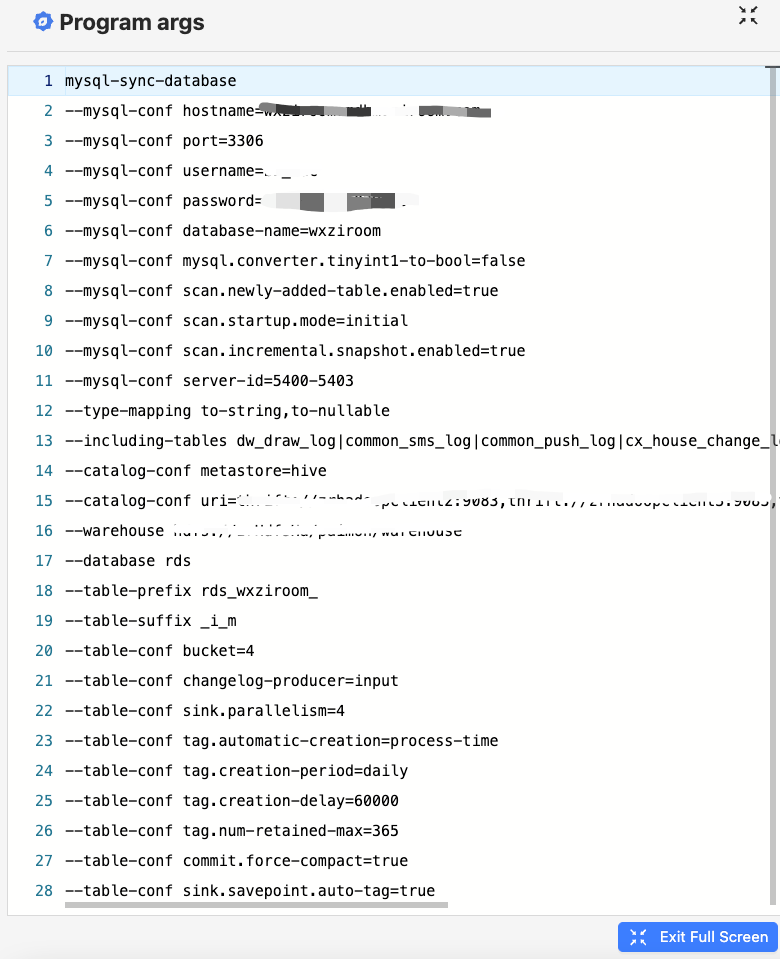
After Apache Paimon version 0.5, CDC data integration capabilities are provided. Data from MySQL, Kafka, Mongo, etc. can be easily ingested into Paimon in real time through the officially provided paimon-action jar. We are using paimon- flink-action uses mysql-sync-database (whole database synchronization) and selects the tables to be synchronized through the "—including_tables" parameter. This synchronization mode effectively saves a lot of resource overhead. Compared with starting a Flink task for each table, it avoids a lot of waste of resources.
paimon-flink-action provides the function of automatically creating Paimon tables and supports Schema Evolution (for example, when the MySQL table fields change, the Paimon table will change accordingly without additional operations). The entire operation process is efficient and smooth, which solves the unnecessary operation and maintenance costs caused by adding fields to the original architecture. The specific use of paimon-action is as follows. For more information, please refer to the Paimon official website documentation.
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8-SNAPSHOT.jar \
mysql_sync_table
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition_keys <partition_keys>] \
[--primary_keys <primary-keys>] \
[--type_mapping <option1,option2...>] \
[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \
[--metadata_column <metadata-column>] \
[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]
The introduction of Paimon shortens the entire data access link, eliminates dependence on Canal, Kafka, and Airflow, allowing MySQL to directly connect to Hive at minute speeds, and the overall environment is clean and efficient. In addition, Paimon is fully compatible with Hive-side data reading, with extremely low conversion costs and good compatibility with the use of original architecture scripts. Paimon also supports the Tag function, which can be regarded as a lightweight snapshot, significantly reducing storage costs.
3.4 StreamPark + Paimon implementation practice
StreamPark has better support for JAR type jobs in version 2.1.2, making Paimon type data integration jobs simpler. The following example demonstrates how to use StreamPark to quickly develop Paimon data migration type jobs:
//Video link (StreamPark deployment Paimon data integration job example)
It is true that StreamPark has specifically supported Paimon data integration jobs after version 2.1.2, but this method of manually creating jobs and entering job parameters still does not meet our actual needs. We need more flexible job creation, which can be done through Quickly complete job creation and startup by calling API... After our research, we found that StreamPark has completely opened various operation APIs for jobs, such as job copy, creation, deployment, start, stop, etc. In this way, we Through scheduled scheduling, it can be easily combined with StreamPark to quickly complete the development and operation of jobs. The specific methods are as follows:
Step1:First, the api copy template interface will be called and parameters will be passed in. The relevant screenshots are as follows:
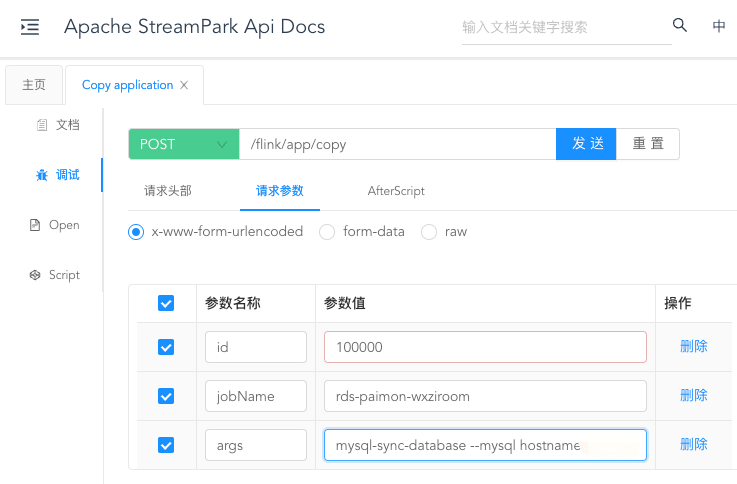
In this way, the job will be created quickly, and the parameters will be passed in through the copy interface. The specific parameters are as follows:
Step2:Next, call the API to build the job image:
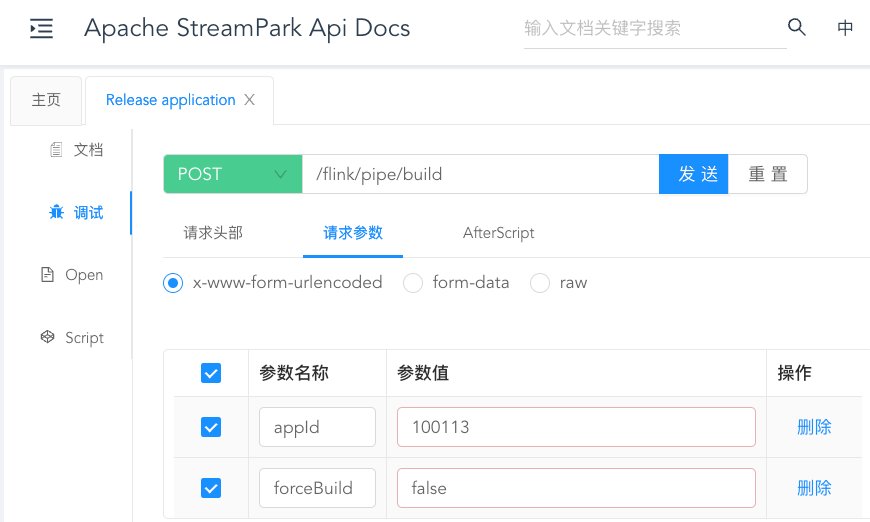
Step3:Continue to call the API to start the job:
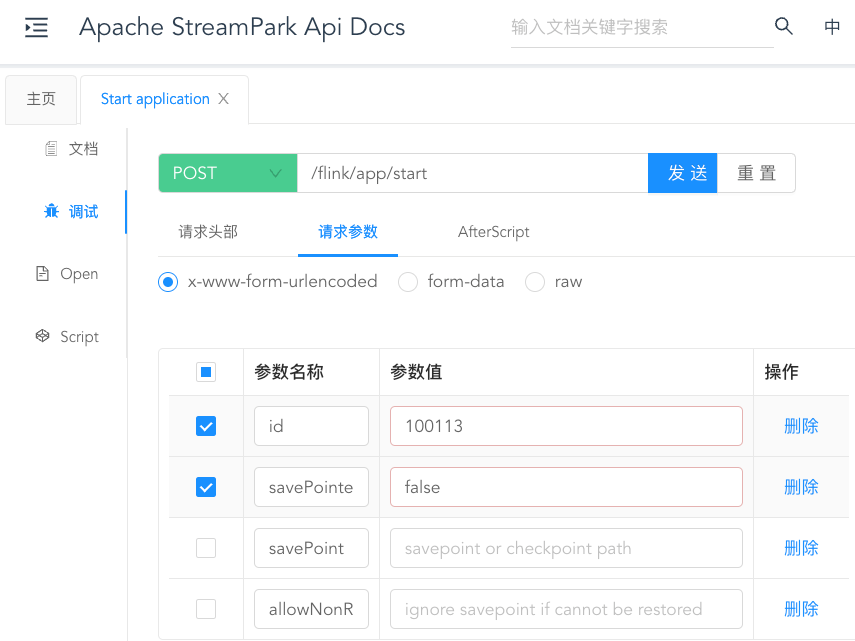
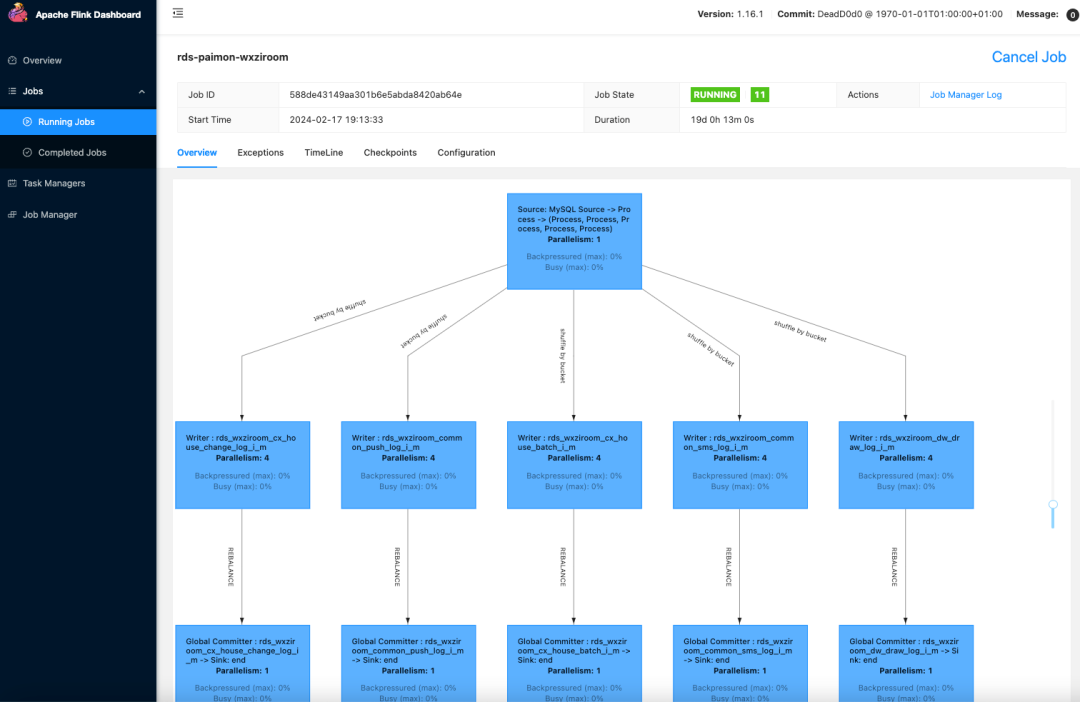
Finally, after the task is successfully started, you can see the relevant status information of the task and the resource overview of the overall task on the StreamPark platform:

You can also click Application Name to schedule the Flink web UI:
Finally, you can directly query the Paimon table on the Hive side to obtain the required data. The Paimon table is a data synchronization target table with low latency processed by Flink. The screenshot of Hive query Paimon table in Hue is as follows
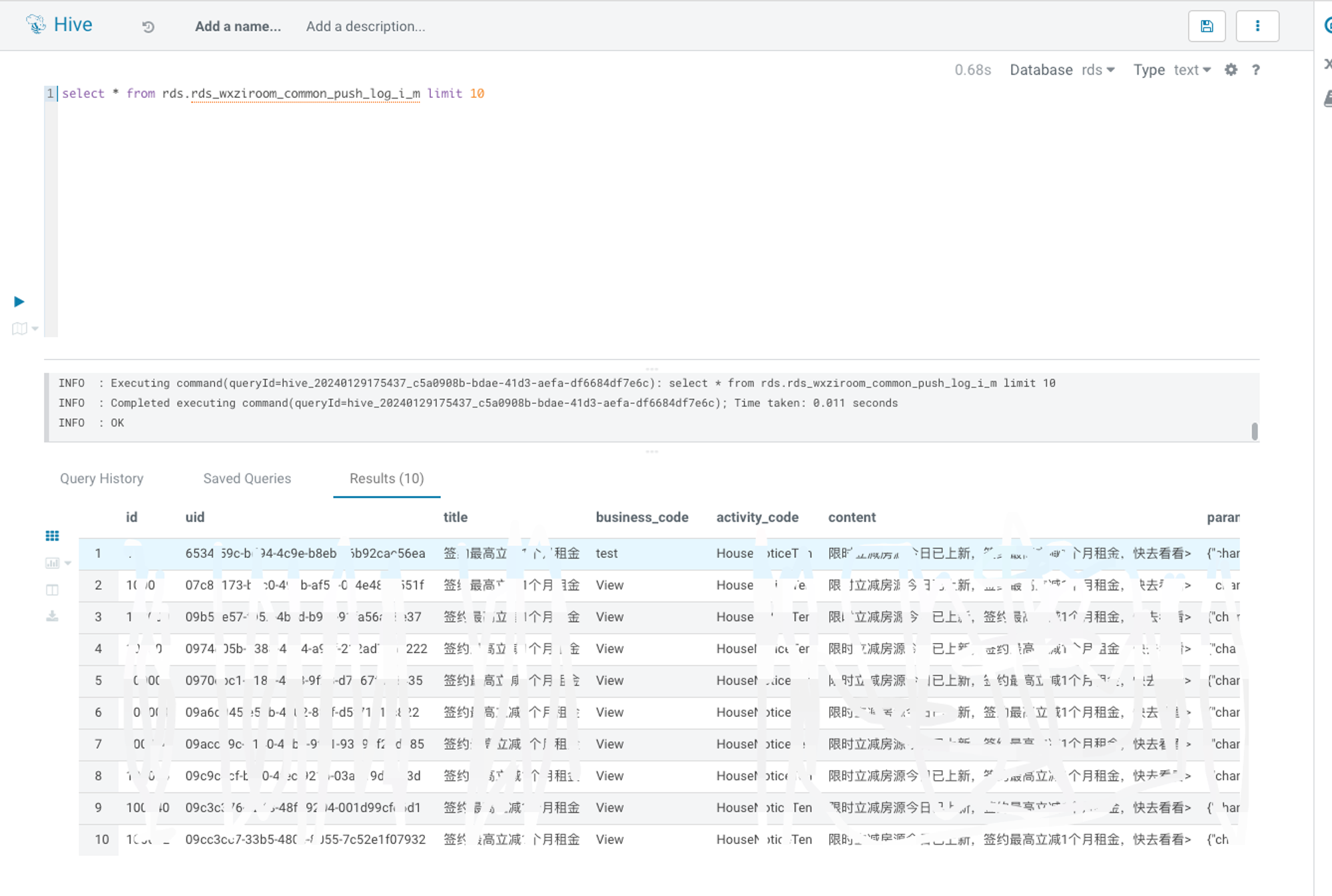
Through the above steps, the business party can easily initiate an access application. After the approval process, a Flink job is created and deployed through StreamPark. The data is entered into the Paimon table through the Flink job, allowing users to easily perform query operations on the Hive side. The entire process is simplified. User operation improves the efficiency and maintainability of data access.
4. Benefits
By using Paimon and StreamPark, Ziroom has brought the following advantages and benefits:
-
Network resources and database pressure optimization: By obtaining data snapshots directly from the Paimon table, the problem of network resource constraints and excessive database pressure caused by pulling data from the business database in the early morning is solved, while data storage costs are reduced.
-
Job management interface improves efficiency: Using StreamPark's job management interface easily solves the problem of manual deployment of Flink tasks, eliminates the situation where tasks are not deployed in time due to personnel dependence on time, improves efficiency, and reduces communication costs. Improved the management efficiency of Flink jobs.
-
Reduce development and maintenance costs: It solves the problems of high maintenance costs and slow problem location caused by long links in the previous solution. It also solves the problem of field inconsistency caused by field changes and realizes the unified flow and batch of data access. , reducing development and maintenance costs.
-
Reduced usage costs of data integration scheduling resources and computing resources: No longer relies on external scheduling systems for incremental data merging, reducing the use of scheduling resources. It no longer relies on Hive resources for merge operations, reducing the cost of merging incremental data on Hive computing resources.
5. Conclusion & Expectations
We would like to sincerely thank the Apache StreamPark community for their generous help as we use the StreamPark API. Their professional service spirit and user-oriented attitude allow us to use this powerful framework more efficiently and smoothly. As an excellent framework, StreamPark not only has excellent functions, but also supports a series of operations such as task copying, creation, deployment, start, stop and status monitoring, and has significantly played a significant role in simplifying the management and maintenance of Flink tasks. its value.
At the same time, we would like to express our gratitude to the Apache Paimon community for their patience and professional guidance during the testing phase of Ziroom MySQL into Paimon. This is an important support for us to successfully complete the test. As a project with great potential, Paimon has demonstrated extraordinary qualities both in terms of feature implementation and team collaboration.
Finally, we are full of expectations and confidence in the future of Apache StreamPark and Apache Paimon, and firmly believe that they will become excellent projects for Apache in the future. Their excellent functions and harmonious community cooperation model have laid a solid foundation for their maturity in the open source community. We expect that the StreamPark and Paimon communities will continue to maintain a professional attitude and good teamwork spirit, continue to advance the development of the project, and become a model for new Apache projects in recent years, so as to have a greater impact on the broader developer community.