**摘要:**本文源自 StreamPark 在尘锋信息的生产实践,作者是资深数据开发工程师Gump。主要内容为:
- 技术选型
- 落地实践
- 业务支撑 & 能力开放
- 未来规划
- 结束语
尘锋信息是基于企业微信生态的一站式私域运营管理解决方案供应商,致力于成为全行业首席私域运营与管理专家,帮助企业构建数字时代私域运营管理新模式,助力企业实现高质量发展。
目前,尘锋已在全国拥有13个城市中心,覆盖华北、华中、华东、华南、西南五大区域,为超30个行业的10,000+家企业提供数字营销服务。
01 技术选型
尘锋信息在2021年进入了快速发展时期,随着服务行业和企业客户的增加,实时需求越来越多,落地实时计算平台迫在眉睫。
由于公司处于高速发展期,需求紧迫且变化快,所以团队的技术选型遵循以下原则:
- 快:由于业务紧迫,我们需要快速落地规划的技术选型并运用生产
- 稳:满足快的基础上,所选择技术一定要稳定服务业务
- 新:在以上基础,所选择的技术也尽量的新
- 全:所选择技术能够满足公司快速发展和变化的业务,能够符合团队长期发展目标,能够支持且快速支持二次开发
首先在计算引擎方面:我们选择 Flink,原因如下:
- 团队成员对 Flink 有深入了解,熟读源码
- Flink 支持批流一体,虽然目前公司的批处理架构还是基于 Hive、Spark 等。使用 Flink 进行流计算,便于后期建设批流一体和湖仓一体
- 目前国内 Flink 生态已经越来越成熟,Flink 也开始着手踏破边界向流式数仓发展
在平台层面,我们综合对比了 StreamPark 、 Apache Zeppelin 和 flink-streaming-platform-web,也深入阅读了源码和并做了优缺点分析,关于后两个项目本文就不展开赘述,感兴趣的朋友可以去 GitHub 搜索,我们最终选择 StreamPark,理由如下:
完成度高
1. 支持Flink 多版本
//视频链接( Flink 多版本支持 Demo )
新建任务时可以自由选择Flink版本,Flink 二进制版本包会自动上传至 HDFS(如果使用 Yarn 提交),且一个版本的二进制包只会在 HDFS 保存一份。任务启动时会自动根据上下文加载 HDFS 中的 Flink 二进制包,非常优雅。能够满足多版本共存,及升级Flink 新版本试用测试的场景。
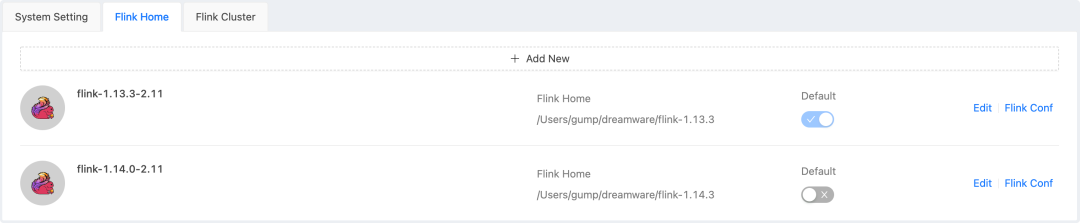
2. 支持多种部署模式
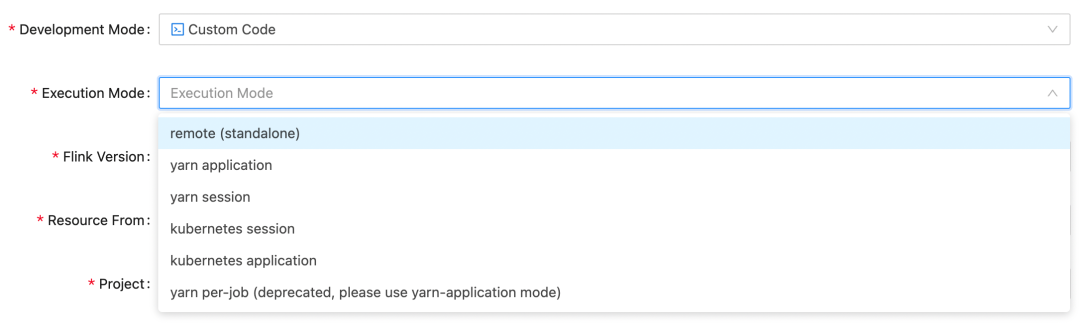
StreamPark 支持 Flink 所有主流的提交模式,如 standalone、yarn-session 、yarn application、yarn-perjob、kubernetes-session、kubernetes-application 而且StreamPark 不是简单的拼接 Flink run 命令来进行的任务提交,而是引入了 Flink Client 源码包,直接调用 Flink Client API 来进行的任务提交。这样的好处是代码模块化、易读、便于扩展,稳定,且能在后期根据 Flink 版本升级进行很快的适配。
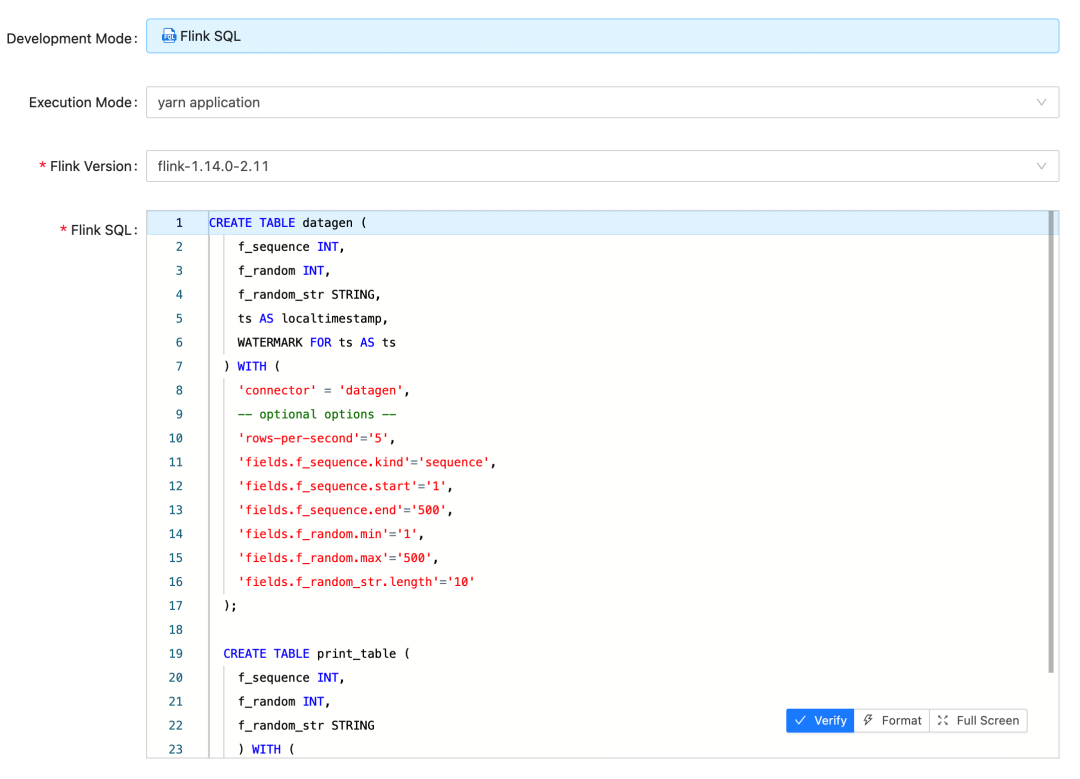
Flink SQL 可以极大提升开发效率和提高 Flink 的普及。StreamPark 对于 Flink SQL 的支持非常到位,优秀的 SQL 编辑器,依赖管理,任务多版本管理等等。StreamPark 官网介绍后期会加入 Flink SQL 的元数据管理整合,大家拭目以待。
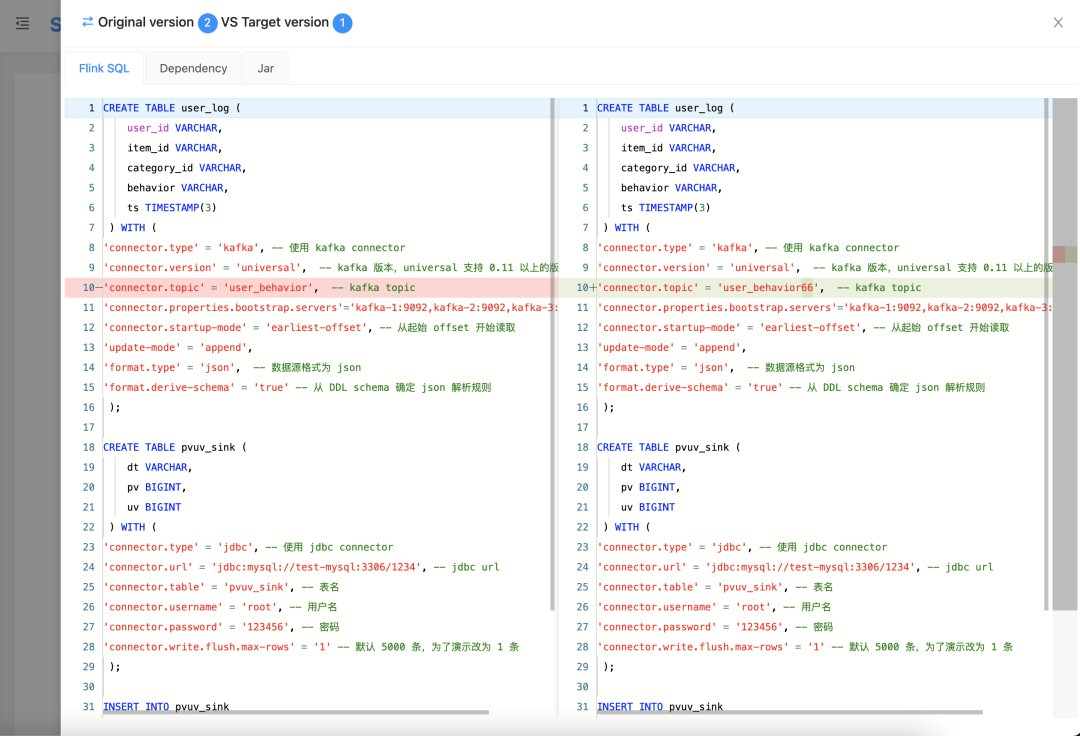
4. JAVA任务在线构建
//视频链接( JAVA 任务构建 Demo)
Flink SQL 现在虽然足够强大,但使用 Java 和 Scala 等 JVM 语言开发 Flink 任务会更加灵活、定制化更强、便于调优和提升资源利用率。与 SQL 相比 Jar 包提交任务最大的问题是Jar包的上传管理等,没有优秀的工具产品会严重降低开发效率和加大维护成本。
StreamPark 除了支持 Jar 上传,更提供了在线更新构建的功能,优雅解决了以上问题:
1、新建 Project :填写 GitHub/Gitlab(支持企业私服)地址及用户名密码,StreamPark 就能 Pull 和 Build 项目。
2、创建 StreamPark Custom-Code 任务时引用 Project,指定主类,启动任务时可选自动 Pull、Build 和绑定生成的 Jar,非常优雅!
同时 StreamPark 社区最近也在完善整个任务编译、上线的流程,以后的 StreamPark 会在此基础上更加完善和专业。
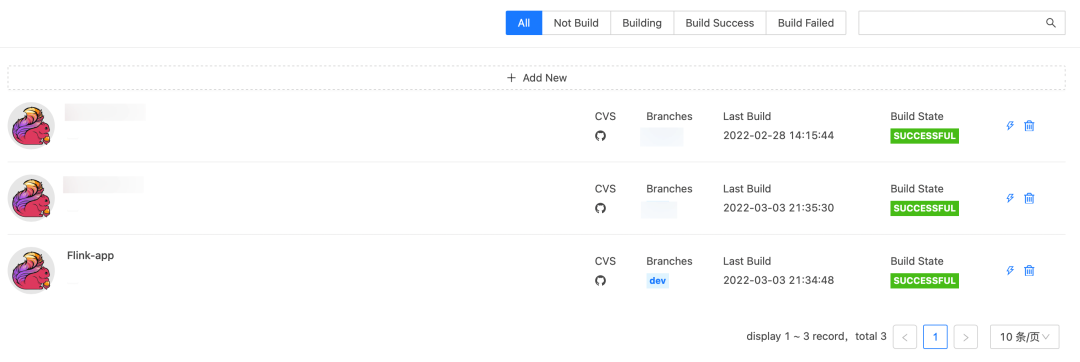
5. 完善的任务参数配置
对于使用 Flink 做数据开发而言,Flink run 提交的参数几乎是难以维护的。StreamPark 也非常优雅的解决了此类问题,原因是上面提到的 StreamPark 直接调用 Flink Client API,并且从 StreamPark 产品前端打通了整个流程。
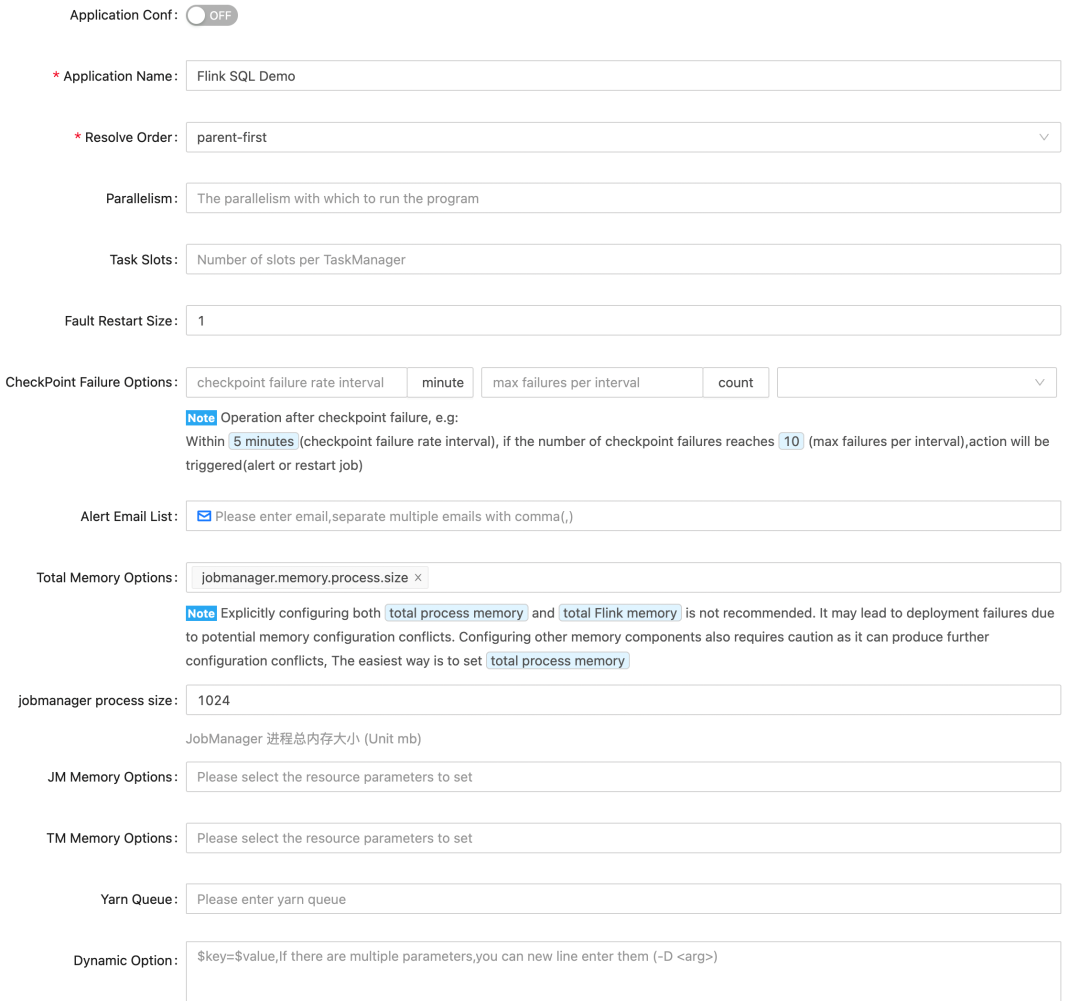
大家可以看到,StreamPark 的任务参数设置涵盖了主流的所有参数,并且非常细心的对每个参数都做了介绍和最佳实践的最优推荐。这对于刚使用 Flink 的同学来说也是非常好的事情,避免踩坑!
6. 优秀的配置文件设计
对于 Flink 任务的原生参数,上面的任务参数已经涵盖了很大一部分。StreamPark 还提供了强大的Yaml 配置文件 模式和 编程模型。
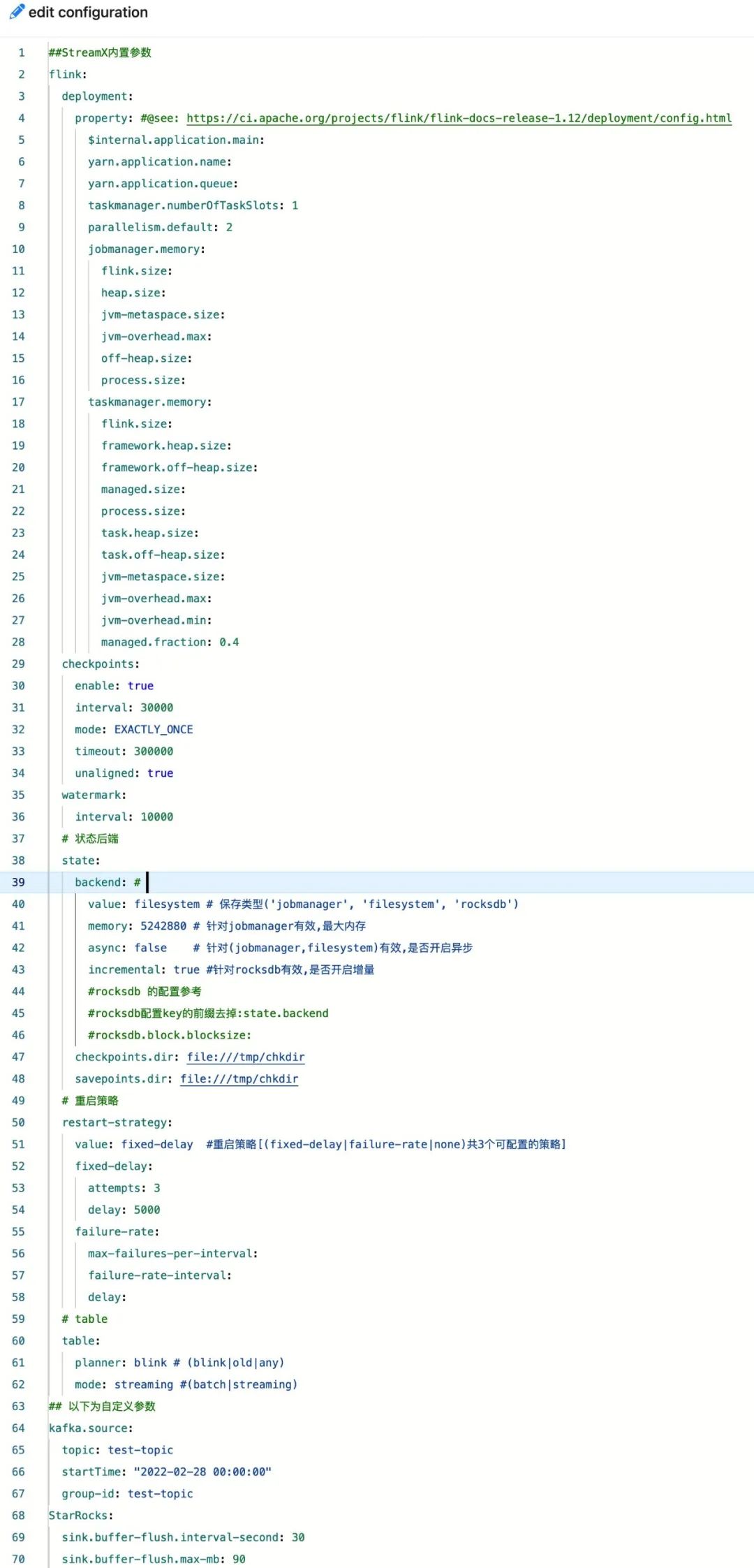
1、对于 Flink SQL 任务,直接使用任务的 Yaml 配置文件可以配置 StreamPark 已经内置的参数,如常见的 CheckPoint、重试机制、State Backend、table planer 、mode 等等。
2、对于 Jar 任务,StreamPark 提供了通用的编程模型,该模型封装了 Flink 原生 API ,结合 StreamPark 提供的封装包可以非常优雅的获取配置文件中的自定义参数,这块文档详见:
编程模型:
https://streampark.apache.org/docs/development/Programming-paradigm
内置配置文件参数:
https://streampark.apache.org/docs/development/config
除此之外:
StreamPark 也支持Apache Flink® 原生任务,参数配置可以由 Java 任务内部代码静态维护,可以覆盖非常多的场景,比如存量 Flink 任务无缝迁移等等
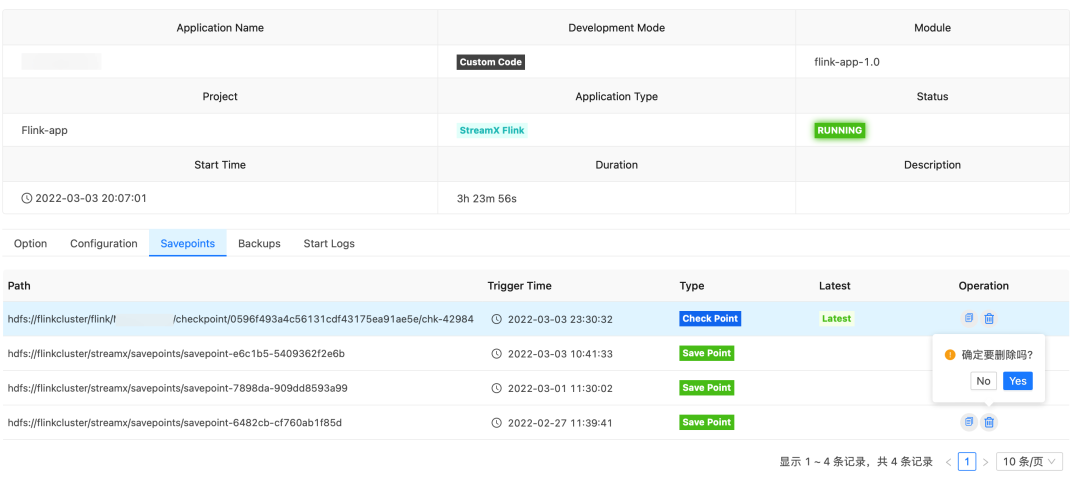
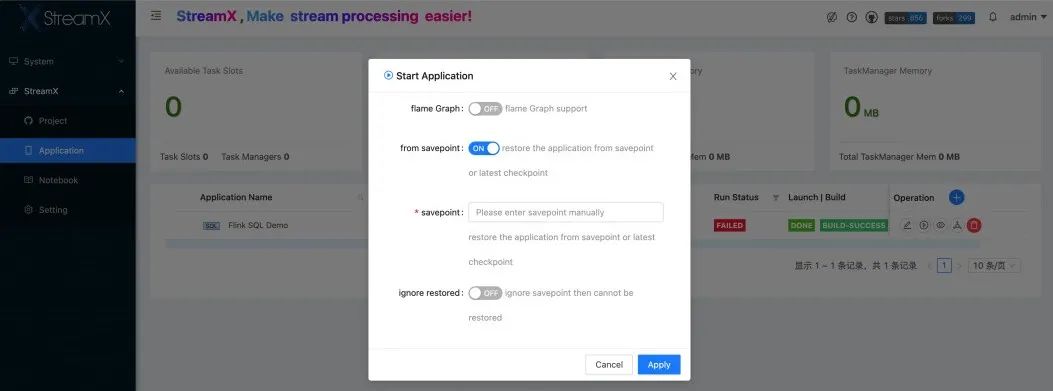
7. Checkpoint 管理
关于 Flink 的 Checkpoint(Savepoint)机制,最大的困难是维护 ,StreamPark 也非常优雅的解决此问题:
- StreamPark 会自动维护任务 Checkpoint 的目录及版本至系统中方便检索
- 当用户需要更新重启应用时,可以选择是否保存 Savepoint
- 重新启动任务时可选择 Checkpoint/Savepoint 从指定版本的恢复
如下,开发同学能够非常直观方便的升级或处理异常任务,非常强大
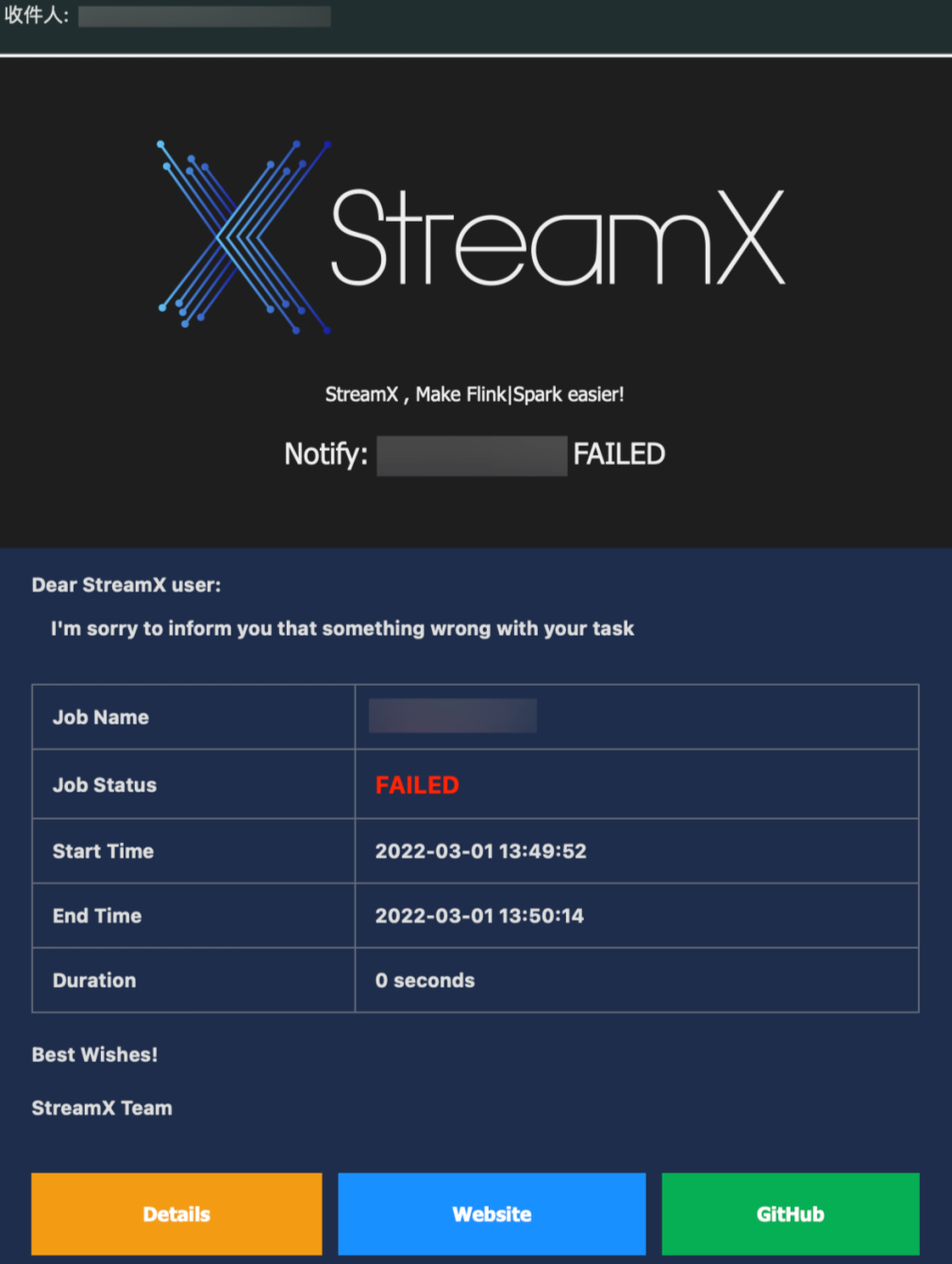
8. 完善的报警功能
对于流式计算此类7*24H常驻任务来说,监控报警是非常重要的 ,StreamPark 对于此类问题也有完善的解决方案:
- 自带基于邮件的报警方式,0开发成本,配置即可使用
- 得益于 StreamPark 源码优秀的模块化,可以在 Task Track 处进行代码增强,引入公司内部的 SDK 进行电话、群组等报警方式,开发成本也非常低
源码优秀
遵循技术选型原则,一个新的技术必须足够了解底层原理和架构思想后,才会考虑应用生产。在选择 StreamPark 之前,对其架构和源码进入过深入研究和阅读。发现 StreamPark 所选用的底层技术是国人非常熟悉的:MySQL、Spring Boot、Mybatis Plus、Vue 等,代码风格统一,实现优雅,注释完善,各模块独立抽象合理,使用了较多的设计模式,且代码质量很高,非常适合后期的排错及二次开发。
StreamPark 于 2021年11月成功被开源中国评选为GVP - Gitee「最有价值开源项目」,足以见得其质量和潜力。

03 社区活跃
目前社区非常活跃,从2021年11月底落地 StreamPark (基于1.2.0-release),当时StreamPark 刚刚才被大家认识,还有一些体验上的小 Bug(不影响核心功能)。当时为了快速上线,屏蔽掉了一些功能和修复了一些小 Bug,正当准备贡献给社区时发现早已修复,这也可以看出目前社区的迭代周期非常快。以后我们公司团队也会努力和社区保持一致,将新特性快速落地,提升数据开发效率和降低维护成本。
02 落地实践
StreamPark 的环境搭建非常简单,跟随官网的搭建教程可以在小时内完成搭建。目前已经支持了前后端分离打包部署的模式,可以满足更多公司的需求,而且已经有 Docker Build 相关的 PR,相信以后 StreamPark 的编译部署会更加方便快捷。相关文档如下:
https://streampark.apache.org/docs/user-guide/deployment
为了快速落地和生产使用,我们选择了稳妥的 On Yarn 资源管理模式(虽然 StreamPark 已经很完善的支持 K8S),且已经有较多公司通过 StreamPark 落地了 K8S 部署方式,大家可以参考:
https://streampark.apache.org/blog/flink-development-framework-streampark
StreamPark 整合 Hadoop 生态可以说是0成本的(前提是按照 Flink 官网将 Flink 与 Hadoop 生态整合,能够通过 Flink 脚本启动任务即可)
目前我们也正在进行 K8S 的测试及方案设计,在未来一段时间会整体迁移至 K8S
01 落地 FlinkSQL 任务
目前我们公司基于 Flink SQL 的任务主要为业务比较简单的实时 ETL 和计算场景,数量在10个左右,上线至今都十分稳定。

StreamPark 非常贴心的准备了 Demo SQL 任务,可以直接在刚搭建的平台上运行,从这些细节可以看出社区对用户体验非常重视。前期我们的简单任务都是通过 Flink SQL 来编写及运行,StreamPark 对于 Flink SQL 的支持得非常好,优秀的 SQL 编辑器,创新型的 POM 及 Jar 包依赖管理,可以满足非常多的 SQL 场景下的问题。
目前我们正在进行元数据层面、权限、UDF等相关的方案调研、设计等
02 落地 Jar 任务
由于目前团队的数据开发同学大多有 Java 和 Scala 语言基础,为了更加灵活的开发、更加透明的调优 Flink 任务及覆盖更多场景,我们也快速的落地了基于 Jar 包的构建方式。我们落地分为了两个阶段
第一阶段:StreamPark 提供了原生 Apache Flink® 项目的支持,我们将存量的任务Git地址配置至 StreamPark,底层使用 Maven 打包为 Jar 包,创建 StreamPark 的 Apache Flink任务,无缝的进行了迁移。在这个过程中,StreamPark 只是作为了任务提交和状态维护的一个平台工具,远远没有使用到上面提到的其他功能。
第二阶段:第一阶段将任务都迁移至 StreamPark 上之后,任务已经在平台上运行,但是任务的配置,如 checkpoint,容错以及 Flink 任务内部的业务参数的调整都需要修改源码 push 及 build,效率十分低下且不透明。
于是,根据 StreamPark 的 QuickStart 我们快速整合了StreamPark 的编程模型,也就是StreamPark Flink 任务(对于 Apache Flink)的封装。
如:
StreamingContext = ParameterTool + StreamExecutionEnvironment
- StreamingContext 为 StreamPark 的封装对象
- ParameterTool 为解析配置文件后的参数对象
String value = ParameterTool.get("${user.custom.key}")
- StreamExecutionEnvironment 为 Apache Flink® 原生任务上下文
03 业务支撑 & 能力开放
目前尘锋基于 StreamPark 的实时计算平台从去年11月底上线至今,已经上线 50+ Flink 任务,其中 10+为 Flink SQL 任务,40+ 为 Jar 任务。目前主要还是数据团队内部使用,近期会将实时计算平台开放全公司业务团队使用,任务量会大量增加。
01 实时数仓
时数仓主要是用 Jar 任务,因为模式比较通用,使用 Jar 任务可以通用化的处理大量的数据表同步和计算,甚至做到配置化同步等,我们的实时数仓主要基 Apache Doris 来存储,使用 Flink 来进行清洗计算(目标是存算分离)
使用 StreamPark 整合其他组件也是非常简单,同时我们也将 Apache Doris 和 Kafka 相关的配置也抽象到了配置文件中,大大提升了我们的开发效率和灵活度。
02 能力开放
数据团队外的其他业务团队也有很多的流处理场景,于是我们将基于 StreamPark 的实时计算平台二次开发后,将以下能力开放全公司业务团队
- 业务能力开放:实时数仓上游将所有业务表通过日志采集写入 Kafka,业务团队可基于 Kafka 进行业务相关开发,也可通过实时数仓(Apache Doris)进行 OLAP分析
- 计算能力开放:将大数据平台的服务器资源开放业务团队使用
- 解决方案开放:Flink 生态的成熟 Connector、Exactly Once 语义支持,可减少业务团队流处理相关的开发成本及维护成本
目前 StreamPark 还不支持多业务组功能,多业务组功能会抽象后贡献社区。
04 未来规划
01 Flink on K8S
目前我司 Flink 任务都运行在 Yarn 上,满足当下需求,但 Flink on kubernetes 有以下优点:
- 统一运维。公司统一化运维,有专门的部门运维 K8S
- CPU 隔离。K8S Pod 之间 CPU 隔离,实时任务不相互影响,更加稳定
- 存储计算分离。Flink 计算资源和状态存储分离,计算资源能够和其他组件资源进行混部,提升机器使用率
- 弹性扩缩容。能够弹性扩缩容,更好的节省人力和物力成本
目前本人也在整理和落地相关的技术架构及方案,并已在实验环境使用 StreamPark 完成了 Flink on kubernetes 的技术验证,生产落地这一目标由于有 StreamPark 的平台支持,以及社区同学的热心帮心,相信在未来不久就能达成。
02 流批一体建设
个人认为批/流最大的区别在于算子 Task 的调度策略 和 数据在算子间的流转策略:
- 批处理上下游算子 Task 存在先后调度(上游Task结束释放资源),数据存在 Shuffle 策略(落地磁盘),缺点是时效性较低且计��算无中间状态,但优点是吞吐量大,适合离线超大数据量计算。
- 流处理上下游算子 Task 同时拉起(同时占用资源),数据通过网络在节点间流式计算,缺点是吞吐量不足,优点是时效性高及计算有中间状态,适合实时及增量计算场景。
如上,个人认为选择批处理还是流处理,是数据开发针对不同数据量和不同业务场景的一种调优方式。但目前由于计算引擎和计算平台会将离线、实时区分,会造成开发及维护的撕裂,成本巨高不下。如果要实现批流一体,要实现以下几个方面:
- 存储的统一(元数据的统一):支持批及流的写入/读取
- 计算引擎的统一 :能够使用一套 API 或 SQL 开发离线和实时任务
- 数据平台的统一 :能够支持实时任务常驻,也能支持离线调度策略
关于批流统一这一块,目前也正在调研、整理、感兴趣的小伙伴欢迎一块探讨项目学习。
05 结束语
以上就是 StreamPark 在尘锋信息生产实践的全部分享内容,感谢大家看到这里。写这篇文章的初心是为大家带来一点 StreamPark 的生产实践的经验和参考,并且和 StreamPark 社区的小伙伴们一道,共同建设 StreamPark ,未来也准备会有更多的参与和建设。非常感谢 StreamPark 的开发者们,能够提供这样优秀的产品,足够多的细节都感受到了大家的用心。虽然目前公司生产使用的(1.2.0-release)版本,在任务分组检索,编辑返回跳页等交互体验上还有些许不足,但瑕不掩瑜,相信 StreamPark 会越��来越好,也相信 StreamPark 会推动 Apache Flink® 的普及。最后用 Apache Flink® 社区的一句话来作为结束吧:实时即未来!
