摘要: 本文带来 StreamPark 在 Joyme 中的生产实践,作者是 Joyme 的大数据工程师秦基勇,主要内容为:
- 遇见StreamPark
- Flink Sql 作业开发
- Custom code 作业开发
- 监控告警
- 常见问题
- 社区印象
- 总结
1 遇见 Apache StreamPark™
遇见 StreamPark 是必然的,基于我们现有的实时作业开发模式,不得不寻找一个开源的平台来支撑我司的实时业务。我们的现状如下:
- 编写作业打包到服务器,然后执行 Flink run 命令进行提交,过程繁琐,效率低下
- Flink Sql 通过自研的老平台提交,老平台开发人员已离职,后续的代码无人维护,即便有人维护也不得不面对维护成本高的问题
- 其中一部分作者是 SparkStreaming 作业,两套流引擎,框架不统一,开发成本大
- 实时作业有 Scala 和 Java 开发,语言和技术栈不统一
基于以上种种原因,我们需要一个开源平台来管理我们的实时作业,同时我们也需要进行重构,统一开发模式,统一开发语言,将项目集中管理。
第一次遇见 StreamPark 就基本确定了,我们根据官网的文档快速进行了部署安装,搭建以后进行了一些操作,界面友好,Flink 多版本支持,权限管理,作业监控等一系列功能已能较好的满足我们的需求,进一步了解到其社区也很活跃,从 1.1.0 版本开始见证了 StreamPark 功能完善的过程,开发团队是非常有追求的,相信会不断的完善。
2 Flink SQL 作业开发
Flink Sql 开发模式带来了很大的便利,对于一些简单的指标开发,只需要简单的 Sql 就可以完成,不需要写一行代码。Flink Sql 方便了很多同学的开发工作,毕竟一些做仓库的同学在编写代码方面还是有些难度。
打开 StreamPark 的任务新增界面进行添加新任务,默认 Development Mode 就是 Flink Sql 模式。直接在 Flink Sql 部分编写Sql 逻辑。
Flink Sql 部分,按照 Flink 官网的文档逐步编写逻辑 Sql 即可,对于我司来说,一般就三部分: 接入 Source ,中间逻辑处理,最后 Sink。基本上 Source 都是消费 kafka 的数据,逻辑处理层会有关联 MySQL 去做维表查询,最后 Sink 部分大多是 Es,Redis,MySQL。
1. 编写SQL
-- 连接kafka
CREATE TABLE source_table (
`Data` ROW<uid STRING>
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = '主题',
'connector.properties.bootstrap.servers'='broker地址',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = '消费组id',
'format.derive-schema' = 'true'
);
-- 落地表sink
CREATE TABLE sink_table (
`uid` STRING
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://xxx/xxx?useSSL=false',
'connector.username' = 'username',
'connector.password' = 'password',
'connector.table' = 'tablename',
'connector.write.flush.max-rows' = '50',
'connector.write.flush.interval' = '2s',
'connector.write.max-retries' = '3'
);
-- 代码逻辑过
INSERT INTO sink_table
SELECT Data.uid FROM source_table;
2. 添加依赖
关于依赖这块是 StreamPark 里特有的,在 StreamPark 中创新型的将一个完整的 Flink Sql 任务拆分成两部分组成: Sql 和 依赖,Sql 很好理解不多啰嗦,依赖是 Sql 里需要用到的一些 Connector 的 Jar,如 Sql 里用到了 Kafka 和 MySQL 的 Connector,那就需要引入这两个 Connector 的依赖,在 StreamPark 中添加依赖两种方式,一种是基于标准的 Maven pom 坐标方式,另一种是从本地上传需要的 Jar 。这两种也可以混着用,按需添加,点击应用即可, 在提交作业的时候就会自动加载这些依赖。
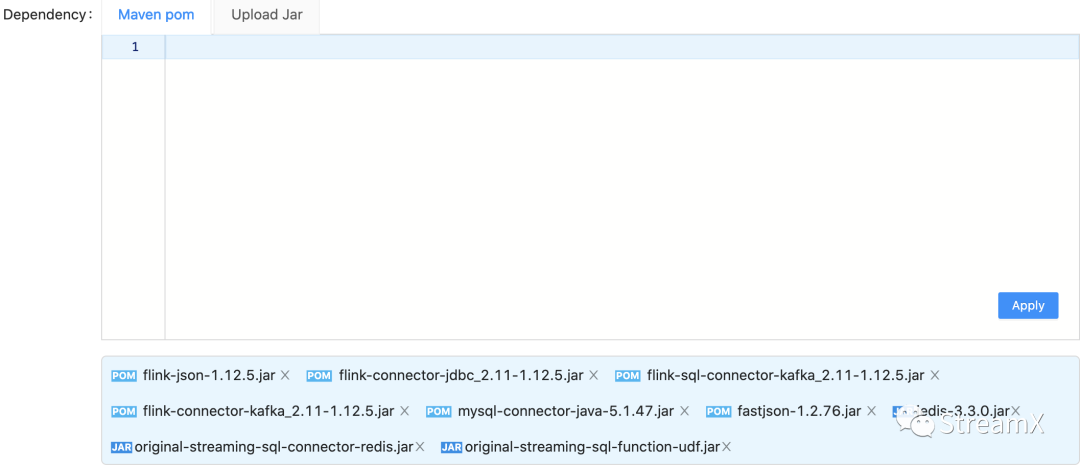
3. 参数配置
在任务的添加和修改页面中已经罗列了一些常用的参数设置,更多的参数设置则提供了一个 yaml 配置文件,我们这里只是设置了 checkpoint 和 savepoint 这两个配置。一是 checkpoint 的位置,二是 执行 checkpoint 的频率。其他的配置基本没有动,这部分用户可以根据自己的需要按需配置。
剩下的一些参数设置就要根据作业的具体情况去对症下药的配置了,处理的数据量大了,逻辑复杂了,可能就需要更多的内存,并行度给多一些。有时候需要根据作业的运行情况进行多次调整。

4. 动态参数设置
由于我们的模式部署是 on Yarn,在动态选项配置里配置了 Yarn 的队列名称。也有一些配置了开启增量的 Checkpoint 选项和状态过期时间,基本的这些参数都可以从 Flink 的�官网去查询到。之前有一些作业确实经常出现内存溢出的问题,加上增量参数和过期参数以后,作业的运行情况好多了。还有就是 Flink Sql 作业设计到状态这种比较大和逻辑复杂的情况下,我个人感觉还是用 Streaming 代码来实现比较好控制一些。
- -Dyarn.application.queue= yarn队列名称
- -Dstate.backend.incremental=true
- -Dtable.exec.state.ttl=过期时间
完成配置以后提交,然后在 application 界面进行部署。
3 Custom Code 作业开发
Streaming 作业我们是使用 Flink java 进行开发,将之前 Spark scala,Flink scala,Flink java 的作业进行了重构,然后工程整合到了一起,目的就是为了维护起来方便。Custom code 作业需要提交代码到 Git,然后配置项目:
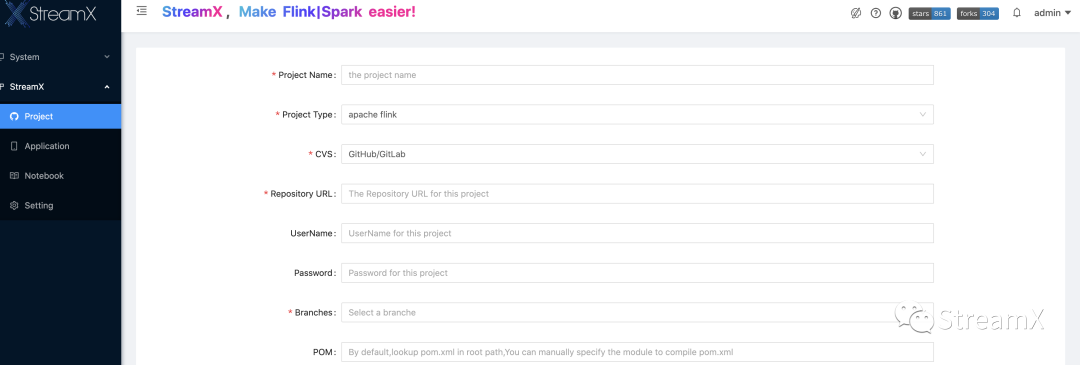
配置完成以后,根据对应的项目进行编译,也就完成项目的打包环节。这样后面的 Constom code 作业也可以引用。每次需要上线都需要进行编译才可以,否则只能是上次编译的代码。这里有个问题,为了安全,我司的 gitlab 账号密码都是定期更新的。这样就会导致,StreamPark 已经配置好的项目还是之前的密码,结果导致编译时从 git 里拉取项目失败,导致整个编译环节失败,针对这个问题,我们联系到社区,了解到这部分已经在后续的 1.2.1 版本中支持了项目的修改操作。

新建任务,选择 Custom code ,选择 Flink 版本,选择项目以及模块 Jar 包,选择开发的应用模式为 Apache Flink® (标准的 Flink 程序),程序主函数入口类,任务的名称。
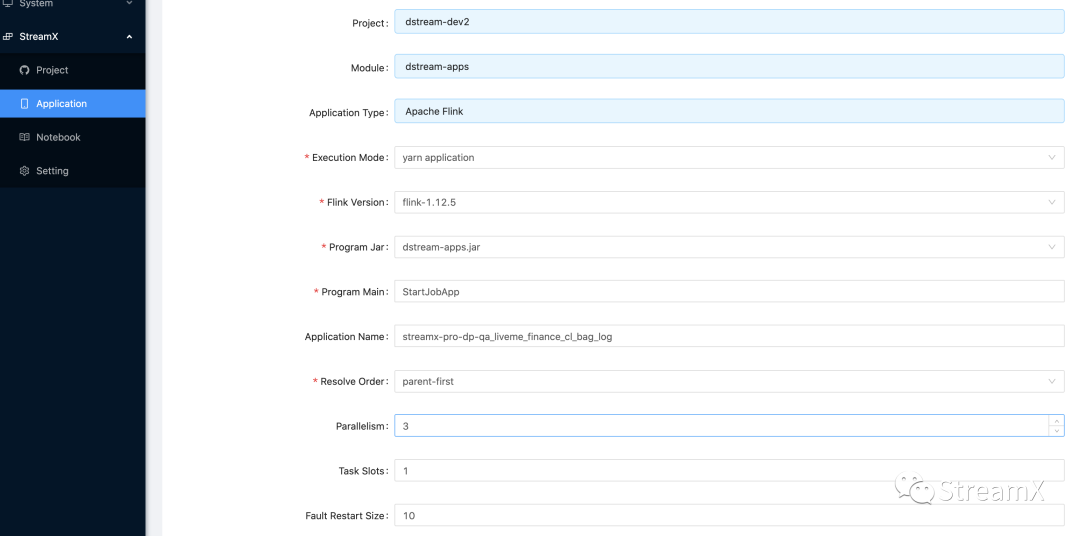
以及任务的并行度,监控的方式等,内存大小根据任务需要进行配置。Program Args 程序的参数则根据程序需要自行定义入口参数,比如:我们统一启动类是 StartJobApp,那么启动作业就需要传入作业的 Full name 告诉启动类要去找哪个类来启动此次任务,也就是一个反射机制,作业配置完成以后同样也是 Submit 提交,然后在 application 界面部署任务。
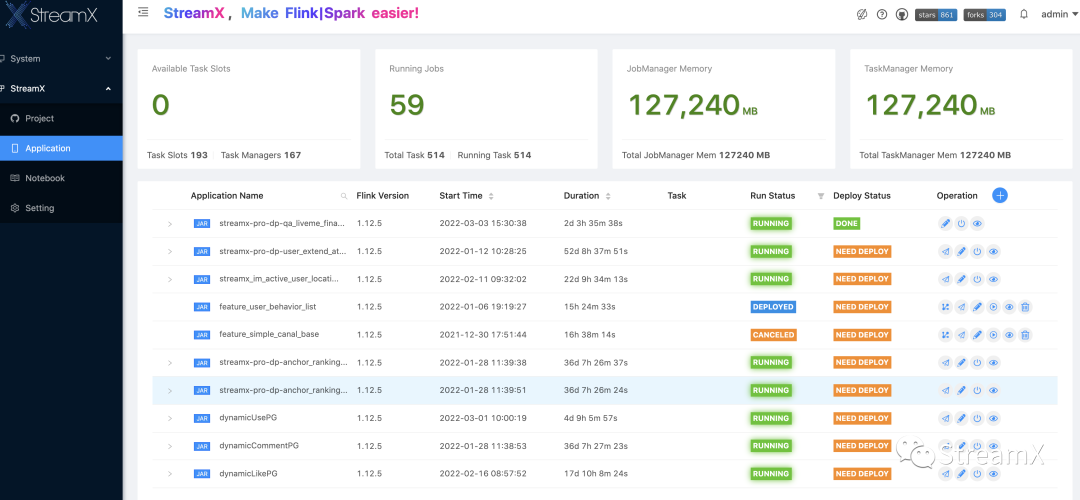
4 监控告警
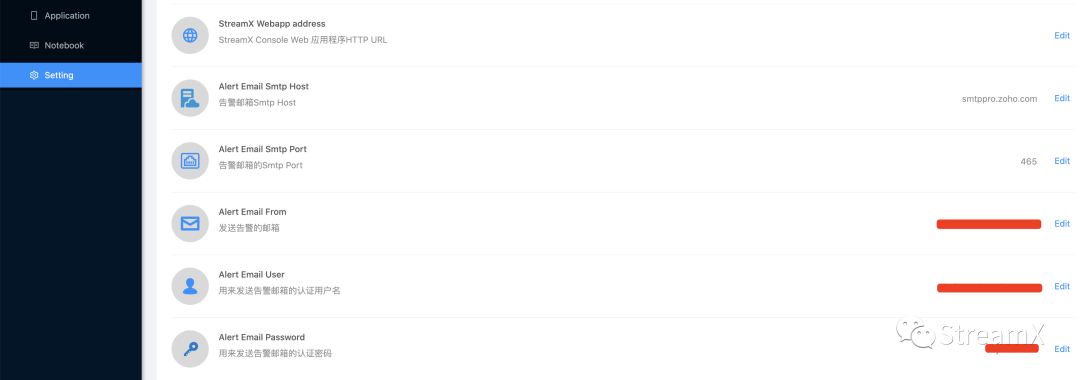
StreamPark 的监控需要在 setting 模块去配置发送邮件的基本信息。
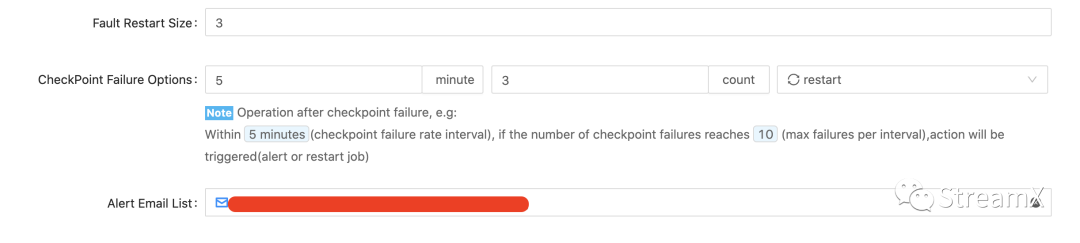
然后在任务里配置重启策略:监控在多久内几次异常,然后是报警还是重启的策略,同时发送报警要发到哪个邮箱。目前我司使用版本是 1.2.1 只支持邮件发送。
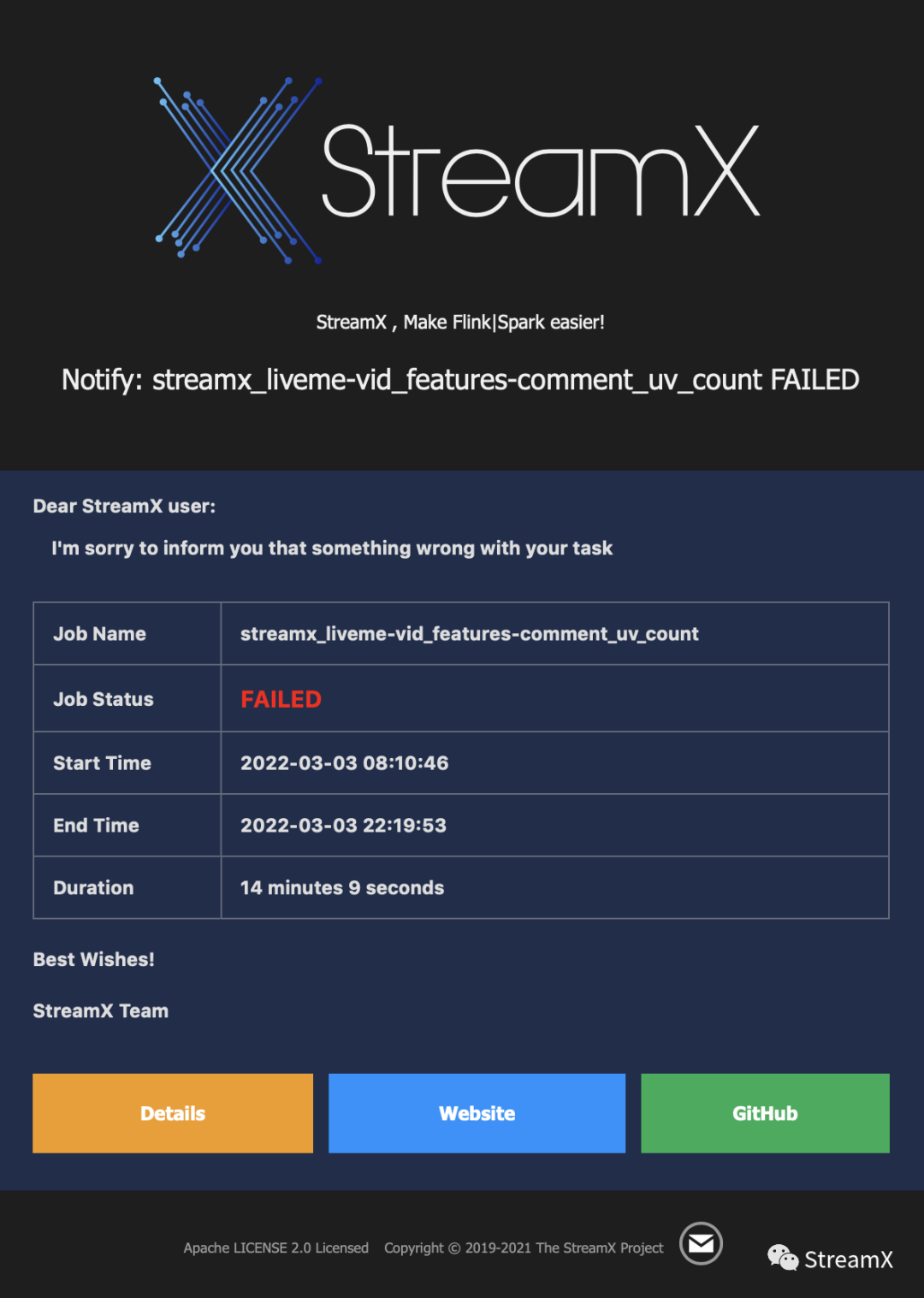
当我们的作业出现失败的情况下,就可以接收到报警邮箱。这报警还是很好看的有木有,可以清楚看到我们的哪个作业,什么状态。也可以点击下面的具体地址进行查看。
关于报警这一块目前我们基于 StreamPark 的 t_flink_app 表进行了一个定时任务的开发。为什么要这么做?因为发送邮件这种通知,大部分人可能不会去及时去看。所以我们选择监控每个任务的状态去把对应的监控信息发送我们的飞书报警群,这样可以及时发现问题去解决任务。一个简单的 python 脚本,然后配置了 crontab 去定时执行。
5 常见问题
关于作业的异常问题,我们归纳分析了基本分为这么几种情况:
1. 作业启动失败
作业启动失败的问题,就是点击启动运行部署。发现起不来,这时候需要看界面的详情信息的日志。在我们的任务列表中有一个眼睛的按钮,点进去。在start logs 中会找到提交的作业日志信息,点进去查看,如果有明显的提示信息,直接解决就可以了。如果没有,就需要去查看后台部署任务的目录 logs/下面的 streamx.out,打开以后会找到启动失败的日志信息。

2. 作业运行失败
如果是任务已经起来了,但是在运行阶段失败了。这种情况表面看上去和上面的情况一样,实则完全不同,这种情况是已经将任务提交给集群了,但是任务运行不起来,那就是我们的任务自身有问题了。同样可以用上面第一种情况的排查方式打开作业的具体日志,找到任务在 yarn 上运行的信息,根据日志里记录的 yarn 的 tackurl 去 yarn 的日志里查看具体的原因,是 Sql 的 Connector 不存在,还是代码的哪行代码空指针了,都可以看到具体的堆栈信息。有了具体信息,就可以对症下药了。

6 社区印象
很多时候我们在 StreamPark 用户群里讨论问题,都会得到社区小伙伴的即时响应。提交的一些 issue 在当下不能解决的,基本也会在下一个版本或者最新的代码分支中进行修复。在群里,我们也看到很多不是社区的小伙伴,也在积极互相帮助去解决问题。群里也有很多其他社区的大佬,很多小伙伴也积极加入了社区的开发工作。整个社区给我的感觉还�是很活跃!
7 总结
目前我司线上运行 60 个实时作业,Flink sql 与 Custom-code 差不多各一半。后续也会有更多的实时任务进行上线。很多同学都会担心 StreamPark 稳不稳定的问题,就我司根据几个月的生产实践而言,StreamPark 只是一个帮助你开发作业,部署,监控和管理的一个平台。到底稳不稳,还是要看自家的 Hadoop yarn 集群稳不稳定(我们用的onyan模式),其实已经跟 StreamPark关系不大了。还有就是你写的 Flink Sql 或者是代码健不健壮。更多的是这两方面应该是大家要考虑的,这两方面没问题再充分利用 StreamPark 的灵活性才能让作业更好的运行,单从一方面说 StreamPark 稳不稳定,实属偏激。
以上就是 StreamPark 在乐我无限的全部分享内容,感谢大家看到这里。非常感谢 StreamPark 提供给我们这么优秀的产品,这就是做的利他人之事。从1.0 到 1.2.1 平时遇到那些bug都会被即时的修复,每一个issue都被认真对待。目前我们还是 onyarn的部署模式,重启yarn还是会导致作业的lost状态,重启yarn也不是天天都干的事,关于这个社区也会尽早的会去修复这个问题。相信 StreamPark 会越来越好,未来可期。