雾芯科技创立于2018年1月。目前主营业务包括 RELX 悦刻品牌产品的研发、设计、制造及销售。凭借覆盖全产业链的核心技术与能力,RELX 悦刻致力于为用户提供兼具高品质和安全性的产品。
最新博客
9
2026年2月
9
2026年2月
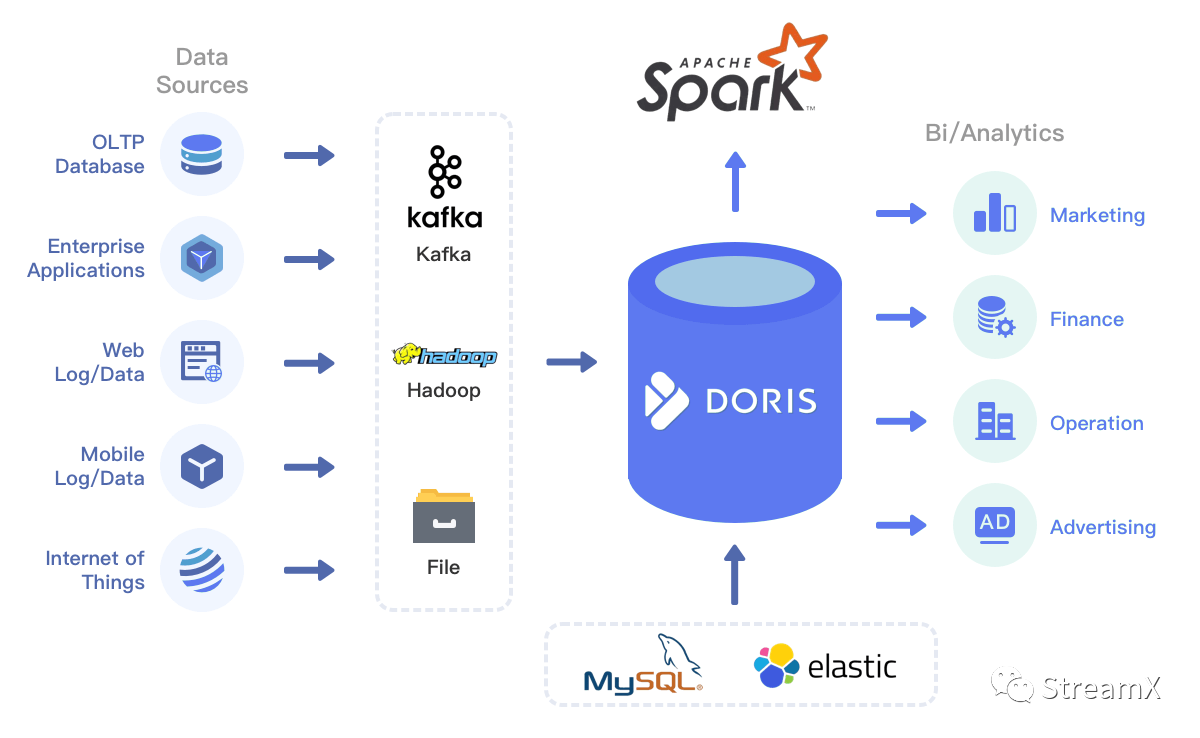
Hadoop 体系虽然在目前应用非常广泛,但架构繁琐、运维复杂度过高、版本升级困难,且由于部门原因,数据中台需求排期较长,我们急需探索敏捷性开发的数据平台模式。在目前云原生架构的普及和湖仓一体化的大背景下,我们已经确定了将 Doris 作为离线数据仓库,将 TiDB(目前已经应用于生产)作为实时数据平台,同时因为 Doris 具有 on MySQL 的 ODBC 能力,所以又可以对外部数据库资源进行整合,统一对外输出报表
9
2026年2月

导读:本文主要介绍了自如 MySQL 数据迁移至 Hive 的架构升级演进,原有架构涉及到的组件众多,链路复杂,遇到很多挑战,在使用 StreamPark + Paimon 这套组合方案后有效地解决了数据集成中遇到的困境和挑战,分享了 StreamPark + Paimon 在实际应用中具体的实践方案,以及这套新秀组合方案带来的优势和收益。
StreamPark: https://github.com/apache/streampark
Paimon: https://github.com/apache/paimon
欢迎关注、Star、Fork,参与贡献
供稿单位|北京自如信息科技有限公司
文章作者|刘涛、梁研生、魏林子
文章整理|杨林伟
内容校对|潘月鹏
9
2026年2月

导读:本文主要介绍天眼查在实时计算业务近千个 Flink 作业运维时面临作业开发和管理上的挑战,通过引入 Apache StreamPark 来解决这些挑战,介绍了在引入 StreamPark 落地过程中遇到的一些问题以及如何解决这些问题并成功落地,最后极大地降低运维成本,显著地提升人效。
Github: https://github.com/apache/streampark
欢迎关注、Star、Fork,参与贡献
供稿单位 | 北京天眼查
文章作者 | 李治霖
文章整理 | 杨林伟
内容校对 | 潘月鹏
9
2026年2月

导读:本文主要详细介绍欢乐互娱在实战中对大数据技术架构的应用,阐述为何选择 “Kubernetes + StreamPark” 来持续优化和增强现有的架构。不仅系统地阐述了如何在实际环境中部署并运用这些关键技术,更是深入地讲解了 StreamPark 的实践使用,强调理论与实践的完美融合,相信读者通过阅读这篇文章,将有助于理解和掌握相关技术,并能在实践中进步,从而取得显著的学习效果。
Github: https://github.com/apache/streampark
欢迎关注、Star、Fork,参与贡献
供稿单位 | 欢乐互娱
文章作者 | 杜遥
文章整理 | 杨林伟
内容校对 | 潘月鹏
9
2026年2月
**摘要:**本文整理自联通数科实时计算团队负责人、Apache StreamPark Committer 穆纯进在 Flink Forward Asia 2022 平台建设专场的分享,本篇内容主要分为四个部分:
- 实时计算平台背景介绍
- Flink 实时作业运维挑战
- 基于 StreamPark 一体化管理
- 未来规划与演进