Apache Kafka Connector
Apache Flink® officially provides a connector to Apache Kafka connector for reading from or writing to a Kafka topic, providing exactly once processing semantics.
KafkaSource and KafkaSink in StreamPark are further encapsulated based on kafka connector from the official website, simplifying the development steps, making it easier to read and write data.
Dependencies
Apache Flink integrates with the generic Kafka connector, which tries to keep up with the latest version of the Kafka client. The version of the Kafka client used by this connector may change between Flink versions. The current Kafka client is backward compatible with Kafka broker version 0.10.0 or later. For more details on Kafka compatibility, please refer to the Apache Kafka official documentation.
<dependency>
<groupId>org.apache.streampark</groupId>
<artifactId>streampark-flink-core</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.0</version>
</dependency>
In the development phase, the following dependencies are also necessary:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
Kafka Source (Consumer)
First, we introduce the standard kafka consumer approach based on the official website, the following code is taken from the official website documentation:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val stream = env.addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties))
You can see a series of kafka connection information defined. In this way, the parameters are hard-coded and insensitive. Let's see how to use StreamPark to access data in Kafka. You need to define the configuration file in the rule format, and then write the code.
example
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: test_user
group.id: user_01
auto.offset.reset: earliest
enable.auto.commit: true
The prefix kafka.source is fixed, and the parameters related to Kafka properties must comply with the official specification for setting the parameter key.
- Scala
- Java
package org.apache.streampark.flink.quickstart
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object kafkaSourceApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource().getDataStream[String]()
print(source)
}
}
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
public class KafkaSimpleJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
source.print();
context.start();
}
}
Advanced configuration parameters
KafkaSource is based on the Flink Kafka Connector construct a simpler kafka reading class, the constructor needs to pass StreamingContext, when the program starts to pass the configuration file can be, framework will automatically parse the configuration file, when new KafkaSource it will automatically get the relevant information from the configuration file, initialize and return a Kafka Consumer, in this case, only configuration one topic, so in the consumption of the time without specifying the topic directly by default to get this topic to consume, this is the simple example, more complex rules and read operations through the . getDataStream() pass parameters in the method to achieve
Let's look at the signature of the getDataStream method:
def getDataStream[T: TypeInformation](topic: java.io.Serializable = null,
alias: String = "",
deserializer: KafkaDeserializationSchema[T],
strategy: WatermarkStrategy[KafkaRecord[T]] = null
): DataStream[KafkaRecord[T]]
The specific description of the parameters are as follows:
| Parameter Name | Parameter Type | Description | Default |
|---|---|---|---|
topic | Serializable | a topic or group of topics | |
alias | String | distinguish different kafka instances | |
deserializer | DeserializationSchema | deserialize class of the data in the topic | KafkaStringDeserializationSchema |
strategy | WatermarkStrategy | watermark generation strategy |
Let's take a look at more usage and configuration methods.
- Consume multiple Kafka instances
- Consume multiple topics
- Topic dynamic discovery
- Consume from the specified offset
- Specific KafkaDeserializationSchema
- Specific WatermarkStrategy
Consume multiple Kafka instances
StreamPark has taken into account the configuration of kafka of multiple different instances at the beginning of development . How to unify the configuration, and standardize the format? The solution in streampark is this, if we want to consume two different instances of kafka at the same time, the configuration file is defined as follows,
As you can see in the kafka.source directly under the kafka instance name, here we unified called alias , alias must be unique, to distinguish between different instances
If there is only one kafka instance, then you can not configure alias
When writing the code for consumption, pay attention to the corresponding alias can be specified, the configuration and code is as follows
- Setting
- Scala
- Java
kafka.source:
kafka1:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: test_user
group.id: user_01
auto.offset.reset: earliest
enable.auto.commit: true
kafka2:
bootstrap.servers: kfk4:9092,kfk5:9092,kfk6:9092
topic: kafka2
group.id: kafka2
auto.offset.reset: earliest
enable.auto.commit: true
KafkaSource().getDataStream[String](alias = "kafka1")
.uid("kfkSource1")
.name("kfkSource1")
.print()
KafkaSource().getDataStream[String](alias = "kafka2")
.uid("kfkSource2")
.name("kfkSource2")
.print()
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source1 = new KafkaSource<String>(context)
.alias("kafka1")
.getDataStream()
print();
DataStream<String> source2 = new KafkaSource<String>(context)
.alias("kafka2")
.getDataStream()
.print();
context.start();
When writing code in java api, be sure to place the settings of these parameters such as alias before calling getDataStream()
Consume multiple topics
Configure the consumption of multiple topic is also very simple, in the configuration file topic can be configured under multiple topic name, separated by , or space, in the scala api, if the consumption of a topic, then directly pass the topic name can be, if you want to consume multiple, pass a List can be
java api through the topic() method to pass in the topic name, which is a variable parameter of type String, can be accepted in one or more topic name, configuration and code as follows
- Setting
- Scala
- Java
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: topic1,topic2,topic3...
group.id: user_01
auto.offset.reset: earliest # (earliest | latest)
...
KafkaSource().getDataStream[String](topic = "topic1")
.uid("kfkSource1")
.name("kfkSource1")
.print()
KafkaSource().getDataStream[String](topic = List("topic1","topic2","topic3"))
.uid("kfkSource1")
.name("kfkSource1")
.print()
DataStream<String> source1 = new KafkaSource<String>(context)
.topic("topic1")
.getDataStream()
.print();
DataStream<String> source1 = new KafkaSource<String>(context)
.topic("topic1","topic2")
.getDataStream()
.print();
topic supports configuring multiple instances of topic, each topic is directly separated by , or separated by spaces, if multiple instances are configured under the topic, the specific topic name must be specified when consuming
Topic dynamic discovery
Regarding kafka's partition dynamics, by default, partition discovery is disabled. To enable it, please set flink.partition-discovery.interval-millis to greater than 0 in the provided configuration, which means the interval between partition discovery is in milliseconds
For more details, please refer to the official website documentation
Flink Kafka Consumer is also able to discover Topics using regular expressions, please refer to the official website documentation
A simpler way is provided in StreamPark, you need to configure the regular pattern of the matching topic instance name in pattern
- Setting
- Scala
- Java
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
pattern: ^topic[1-9]
group.id: user_02
auto.offset.reset: earliest # (earliest | latest)
...
KafkaSource().getDataStream[String](topic = "topic-a")
.uid("kfkSource1")
.name("kfkSource1")
.print()
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
new KafkaSource<String>(context)
.topic("topic-a")
.getDataStream()
.print();
context.start();
topic and pattern can not be configured at the same time, when configured with pattern regular match, you can still specify a definite topic name, at this time, will check whether pattern matches the current topic, if not, will be reported an error
Consume from the specified offset
Flink Kafka Consumer allows the starting position of Kafka partitions to be determined by configuration, official website documentation The starting position of a Kafka partition is specified as follows
- scala
- Java
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val myConsumer = new FlinkKafkaConsumer[String](...)
myConsumer.setStartFromEarliest()
myConsumer.setStartFromLatest()
myConsumer.setStartFromTimestamp(...)
myConsumer.setStartFromGroupOffsets()
val stream = env.addSource(myConsumer)
...
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(...);
myConsumer.setStartFromEarliest();
myConsumer.setStartFromLatest();
myConsumer.setStartFromTimestamp(...);
myConsumer.setStartFromGroupOffsets();
DataStream<String> stream = env.addSource(myConsumer);
...
This setting is not recommended in StreamPark, a more convenient way is provided by specifying auto.offset.reset in the configuration
earliestconsume from earliest recordlatestconsume from latest record
Consume from the specified offset
You can also specify the offset to start consumption for each partition, simply by configuring the start.from related information in the following configuration file
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: topic1,topic2,topic3...
group.id: user_01
auto.offset.reset: earliest # (earliest | latest)
start.from:
timestamp: 1591286400000 # Specify timestamp to take effect for all topics
offset: # Specify an offset for the topic's partition
topic: topic_abc,topic_123
topic_abc: 0:182,1:183,2:182 # Partition 0 starts consumption from 182, partition 1 starts from 183, and partition 2 starts from 182...
topic_123: 0:182,1:183,2:182
...
Specific deserializer
If you do not specify deserializer, the data in the topic will be deserialized by using String by default. At the same time, you can also manually specify deserializer. The complete code is as follows
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
object KafkaSourceApp extends FlinkStreaming {
override def handle(): Unit = {
KafkaSource()
.getDataStream[String](deserializer = new UserSchema)
.map(_.value)
.print()
}
}
class UserSchema extends KafkaDeserializationSchema[User] {
override def isEndOfStream(nextElement: User): Boolean = false
override def getProducedType: TypeInformation[User] = getForClass(classOf[User])
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): User = {
val value = new String(record.value())
JsonUtils.read[User](value)
}
}
case class User(name:String,age:Int,gender:Int,address:String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.io.Serializable;
import static org.apache.flink.api.java.typeutils.TypeExtractor.getForClass;
public class KafkaSourceJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
new KafkaSource<JavaUser>(context)
.deserializer(new JavaUserSchema())
.getDataStream()
.map((MapFunction<KafkaRecord<JavaUser>, JavaUser>) KafkaRecord::value)
.print();
context.start();
}
}
class JavaUserSchema implements KafkaDeserializationSchema<JavaUser> {
private ObjectMapper mapper = new ObjectMapper();
@Override public boolean isEndOfStream(JavaUser nextElement) return false;
@Override public TypeInformation<JavaUser> getProducedType() return getForClass(JavaUser.class);
@Override public JavaUser deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
String value = new String(record.value());
return mapper.readValue(value, JavaUser.class);
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
Return record Kafka Record
The returned object is wrapped in a KafkaRecord, which has the current offset, partition, timestamp and many other useful information for developers to use, where value is the target object returned, as shown below:
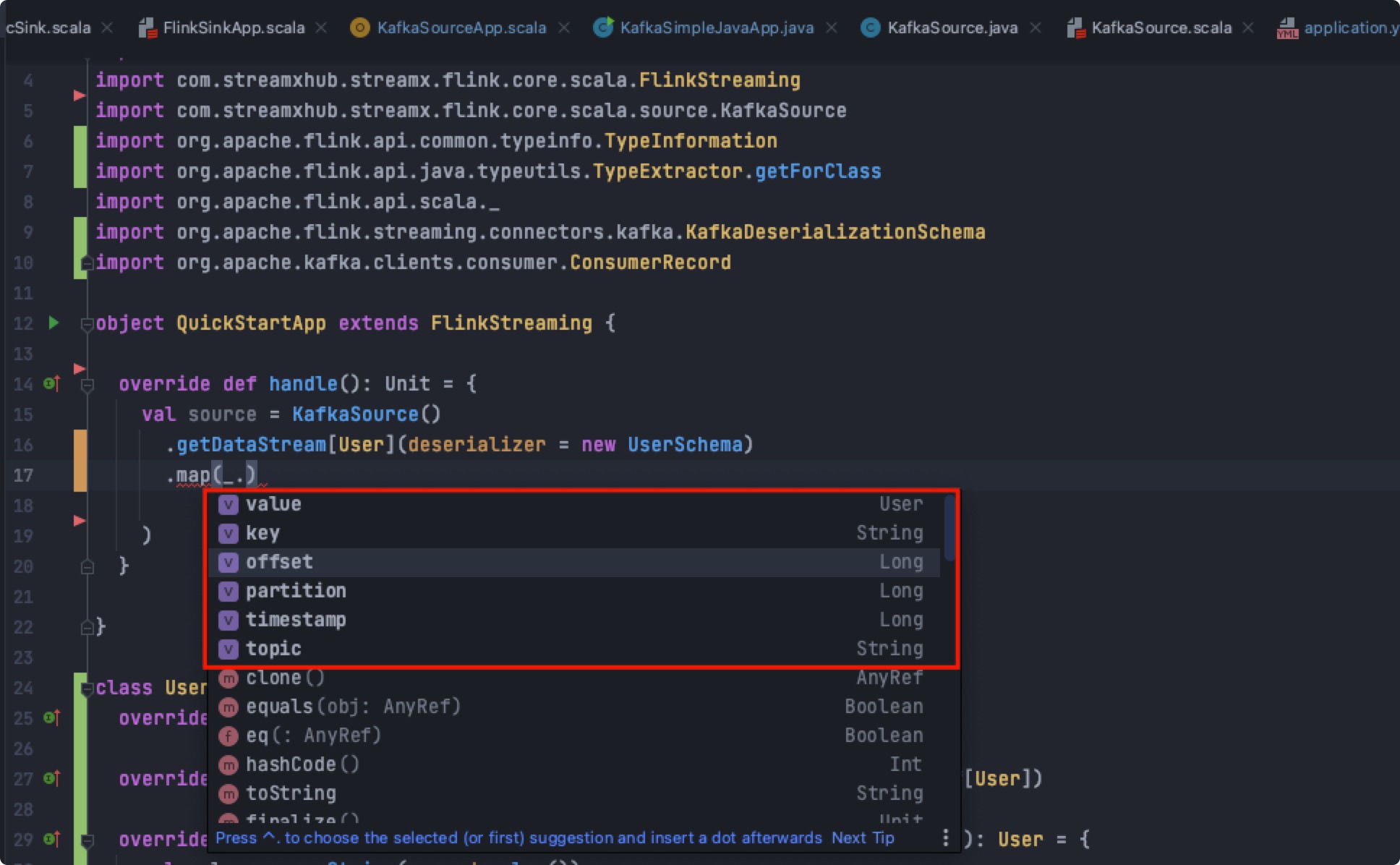
Specific strategy
In many case, the timestamp of the record is embedded (explicitly or implicitly) in the record itself. In addition, users may want to specify in a custom way, for example a special record in a Kafka stream containing a watermark of the current event time. For these cases, Flink Kafka Consumer is allowed to specify AssignerWithPeriodicWatermarks or AssignerWithPunctuatedWatermarks.
In the StreamPark run pass a WatermarkStrategy as a parameter to assign a Watermark, for example, parse the data in the topic as a user object, there is an orderTime in user which is a time type, we use this as a base to assign a Watermark to it
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.source.{KafkaRecord, KafkaSource}
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
import java.time.Duration
import java.util.Date
object KafkaSourceStrategyApp extends FlinkStreaming {
override def handle(): Unit = {
KafkaSource()
.getDataStream[User](
deserializer = new UserSchema,
strategy = WatermarkStrategy
.forBoundedOutOfOrderness[KafkaRecord[User]](Duration.ofMinutes(1))
.withTimestampAssigner(new SerializableTimestampAssigner[KafkaRecord[User]] {
override def extractTimestamp(element: KafkaRecord[User], recordTimestamp: Long): Long = {
element.value.orderTime.getTime
}
})
).map(_.value)
.print()
}
}
class UserSchema extends KafkaDeserializationSchema[User] {
override def isEndOfStream(nextElement: User): Boolean = false
override def getProducedType: TypeInformation[User] = getForClass(classOf[User])
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): User = {
val value = new String(record.value())
JsonUtils.read[User](value)
}
}
case class User(name: String, age: Int, gender: Int, address: String, orderTime: Date)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.io.Serializable;
import java.time.Duration;
import java.util.Date;
import static org.apache.flink.api.java.typeutils.TypeExtractor.getForClass;
public class KafkaSourceStrategyJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
new KafkaSource<JavaUser>(context)
.deserializer(new JavaUserSchema())
.strategy(
WatermarkStrategy.<KafkaRecord<JavaUser>>forBoundedOutOfOrderness(Duration.ofMinutes(1))
.withTimestampAssigner(
(SerializableTimestampAssigner<KafkaRecord<JavaUser>>)
(element, recordTimestamp) -> element.value().orderTime.getTime()
)
)
.getDataStream()
.map((MapFunction<KafkaRecord<JavaUser>, JavaUser>) KafkaRecord::value)
.print();
context.start();
}
}
class JavaUserSchema implements KafkaDeserializationSchema<JavaUser> {
private ObjectMapper mapper = new ObjectMapper();
@Override public boolean isEndOfStream(JavaUser nextElement) return false;
@Override public TypeInformation<JavaUser> getProducedType() return getForClass(JavaUser.class);
@Override public JavaUser deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
String value = new String(record.value());
return mapper.readValue(value, JavaUser.class);
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
Date orderTime;
}
If the watermark assigner relies on messages read from Kafka to raise the watermark (which is usually the case), then all topics and partitions need to have a continuous stream of messages. Otherwise, the application's watermark will not rise and all time-based arithmetic (such as time windows or functions with timers) will not work. A single Kafka partition can also cause this reaction. Consider setting the appropriate idelness timeouts to mitigate this problem.
Kafka Sink (Producer)
In StreamPark the Kafka Producer is called KafkaSink, which allows messages to be written to one or more Kafka topics.
- Scala
- Java
val source = KafkaSource().getDataStream[String]().map(_.value)
KafkaSink().sink(source)
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
new KafkaSink<String>(context).sink(source);
context.start();
sink is a specific method for writing data, and the list of parameters is as follows
| Parameter Name | Parameter Type | Description | Default | Required |
|---|---|---|---|---|
stream | DataStream[T] | data stream to write | yes | |
alias | String | kafka instance alias | no | |
serializationSchema | SerializationSchema[T] | serializer written | SimpleStringSchema | no |
partitioner | FlinkKafkaPartitioner[T] | kafka partitioner | KafkaEqualityPartitioner[T] | no |
Fault Tolerance and Semantics
After enabling Flink's checkpointing, KafkaSink can provide once-exactly semantic, please refer to Chapter 2 on project configuration for the specific setting of checkpointing.
In addition to enabling checkpointing for Flink, you can also choose from three different modes by passing the appropriate semantic parameters to KafkaSink
- EXACTLY_ONCE Provide exactly-once semantics with Kafka transactions
- AT_LEAST_ONCE At least once, it is guaranteed that no records will be lost (but records may be duplicated)
- NONE Flink There is no guarantee of semantics, and the resulting records may be lost or duplicated
configure semantic under the kafka.sink
kafka.sink:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
kafka EXACTLY_ONCE Semantic Description
The Semantic.EXACTLY_ONCE relies on the ability for transactions to be committed. Transaction commits occur before the checkpoint is triggered and after recovery from the checkpoint. If the time between a Flink application crash and a full restart exceeds Kafka's transaction timeout, then there will be caused data loss (Kafka automatically discards transactions that exceed the timeout). With this in mind, please configure the transaction timeout time based on the expected downtime.
By default, the Kafka broker sets transaction.max.timeout.ms to 15 minutes. This property does not allow setting the transaction timeout larger than producers value. By default, FlinkKafkaProducer sets the transaction.timeout.ms property in the producer config to 1 hour, so you should increase the transaction.max.timeout. ms before using Semantic.
In the read_committed mode of KafkaConsumer, any uncompleted (neither aborted nor completed) transaction will block all reads after the uncompleted transaction from the given Kafka topic. In other words, after following the following sequence of events.
- User started transaction1 and used it to write some records
- User started transaction2 and used it to write some other records
- User committed transaction2
Even if the records in transaction2 are committed, they will not be visible to the consumer until transaction1 is committed or aborted. This has 2 levels of implications.
- First, during normal operation of the Flink application, the user can expect a delay in the visibility of records, it equals to the average time between completed checkpoints.
- Second, in the case of a failed Flink application, the topic written by this application will be blocked until the application is restarted or the configured transaction timeout has elapsed, and normalcy will resume. This annotation only applies multi agents or applications writing to the same Kafka topic.
Note: The Semantic.EXACTLY_ONCE mode uses a fixed size pool of KafkaProducers for each FlinkKafkaProducer instance. Each checkpoint uses one of the producers. If the number of concurrent checkpoints exceeds the pool size, FlinkKafkaProducer will throw an exception and cause the entire application to fail. Please configure the maximum pool size and the maximum number of concurrent checkpoints wisely.
Note: Semantic.EXACTLY_ONCE will do everything possible to not leave any stay transactions that would otherwise block other consumers from reading data from this Kafka topic. However, if a Flink application fails before the first checkpoint, there will be no information about the previous pool size in the system after restarting such an application. Therefore, it is not safe to scale down a Flink application before the first checkpoint is completed and the concurrent number of scaling is greater than the value of the safety factor FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR.
Multiple instance kafka specifies alias
If there are multiple instances of kafka that need to be configured at the time of writing, used alias to distinguish between multi kafka instances, configured as follows:
kafka.sink:
kafka_cluster1:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
kafka_cluster2:
bootstrap.servers: kfk6:9092,kfk7:9092,kfk8:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
When writing data, you need to manually specify alias. Note that the scala api and java api are different in code. scala specifies parameters directly in the sink method, while the java api is It is set by the alias() method
- Scala
- Java
val source = KafkaSource().getDataStream[String]().map(_.value)
KafkaSink().sink(source,alias = "kafka_cluster1")
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
new KafkaSink<String>(context).alias("kafka_cluster1").sink(source);
context.start();
Specific SerializationSchema
Flink Kafka Producer needs know how to convert Java/Scala objects to binary data. KafkaSerializationSchema allows users to specify such a schema, please refer to the official documentation for how to do this and documentation
In KafkaSink, the default serialization is not specified, and the SimpleStringSchema is used for serialization, where the developer can specify a custom serializer, specified by the serializationSchema parameter, for example, to write the user object to a custom format kafka
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource()
.getDataStream[String]()
.map(x => JsonUtils.read[User](x.value))
KafkaSink().sink[User](source, serialization = new SerializationSchema[User]() {
override def serialize(user: User): Array[Byte] = {
s"${user.name},${user.age},${user.gender},${user.address}".getBytes
}
})
}
}
case class User(name: String, age: Int, gender: Int, address: String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.sink.KafkaSink;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import java.io.Serializable;
public class kafkaSinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
ObjectMapper mapper = new ObjectMapper();
DataStream<JavaUser> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, JavaUser>) value ->
mapper.readValue(value.value(), JavaUser.class));
new KafkaSink<JavaUser>(context)
.serializer(
(SerializationSchema<JavaUser>) element ->
String.format("%s,%d,%d,%s", element.name, element.age, element.gender, element.address).getBytes()
).sink(source);
context.start();
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
Specific SerializationSchema
Flink Kafka Producer needs know how to convert Java/Scala objects to binary data. KafkaSerializationSchema allows users to specify such a schema, please refer to the official documentation for how to do this and documentation
In KafkaSink, the default serialization is not specified, and the SimpleStringSchema is used for serialization, where the developer can specify a custom serializer, specified by the serializationSchema parameter, for example, to write the user object to a custom format kafka
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource()
.getDataStream[String]()
.map(x => JsonUtils.read[User](x.value))
KafkaSink().sink[User](source, serialization = new SerializationSchema[User]() {
override def serialize(user: User): Array[Byte] = {
s"${user.name},${user.age},${user.gender},${user.address}".getBytes
}
})
}
}
case class User(name: String, age: Int, gender: Int, address: String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.sink.KafkaSink;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import java.io.Serializable;
public class kafkaSinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
ObjectMapper mapper = new ObjectMapper();
DataStream<JavaUser> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, JavaUser>) value ->
mapper.readValue(value.value(), JavaUser.class));
new KafkaSink<JavaUser>(context)
.serializer(
(SerializationSchema<JavaUser>) element ->
String.format("%s,%d,%d,%s", element.name, element.age, element.gender, element.address).getBytes()
).sink(source);
context.start();
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
specific partitioner
KafkaSink allows you to specify a kafka partitioner, if you don't specify it, the default is to use StreamPark built-in KafkaEqualityPartitioner partitioner, as the name, the partitioner can write data to each partition evenly, the scala api is set by the partitioner parameter to set the partitioner,
java api is set by partitioner() method
The default partitioner used in Flink Kafka Connector is FlinkFixedPartitioner, which requires special attention to the parallelism of sink and the number of partitions of kafka, otherwise it will write to a partition