Quick Start
How to use
The installation of the one-stop platform streampark-console has been introduced in detail in the previous chapter. In this chapter, let's see how to quickly deploy and run a job with streampark-console. The official structure and specification) and projects developed with streampark are well supported. Let's use streampark-quickstart to quickly start the journey of streampark-console
streampark-quickstart is a sample program for developing Flink by StreamPark. For details, please refer to:
Deploy DataStream tasks
The following example demonstrates how to deploy a DataStream application
Deploy the FlinkSql task
The following example demonstrates how to deploy a FlinkSql application
- The flink sql used in the project demonstration is as follows
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP(3)
) WITH (
'connector' = 'kafka', -- Using the kafka connector
'properties.group.id' = 'group01' ,
'topic' = 'user_behavior', -- kafka topic
'properties.bootstrap.servers'='kafka-1:9092,kafka-2:9092,kafka-3:9092',
'scan.startup.mode' = 'earliest-offset', -- Read from start offset
'format' = 'json' -- The data source format is json
);
CREATE TABLE pvuv_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (dt,pv,uv) NOT ENFORCED
) WITH (
'connector' = 'jdbc', -- using jdbc connector
'url' = 'jdbc:mysql://test-mysql:3306/test', -- jdbc url
'table-name' = 'pvuv_sink', -- Table Name
'username' = 'root', -- username
'password' = '123456', --password
'sink.buffer-flush.max-rows' = '1' -- Default 5000, changed to 1 for demonstration
);
INSERT INTO pvuv_sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00');
- The maven dependencies are used as follows
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.11</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.6</version>
</dependency>
- The data sent by Kafka simulation is as follows
{"user_id": "543462", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts":"2021-02-01 01:00:00"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "pv", "ts":"2021-02-01 01:00:00"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "pv", "ts":"2021-02-01 01:00:00"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "learning flink", "ts":"2021-02-01 01:00:00"}
Task start process
The task startup flow chart is as follows
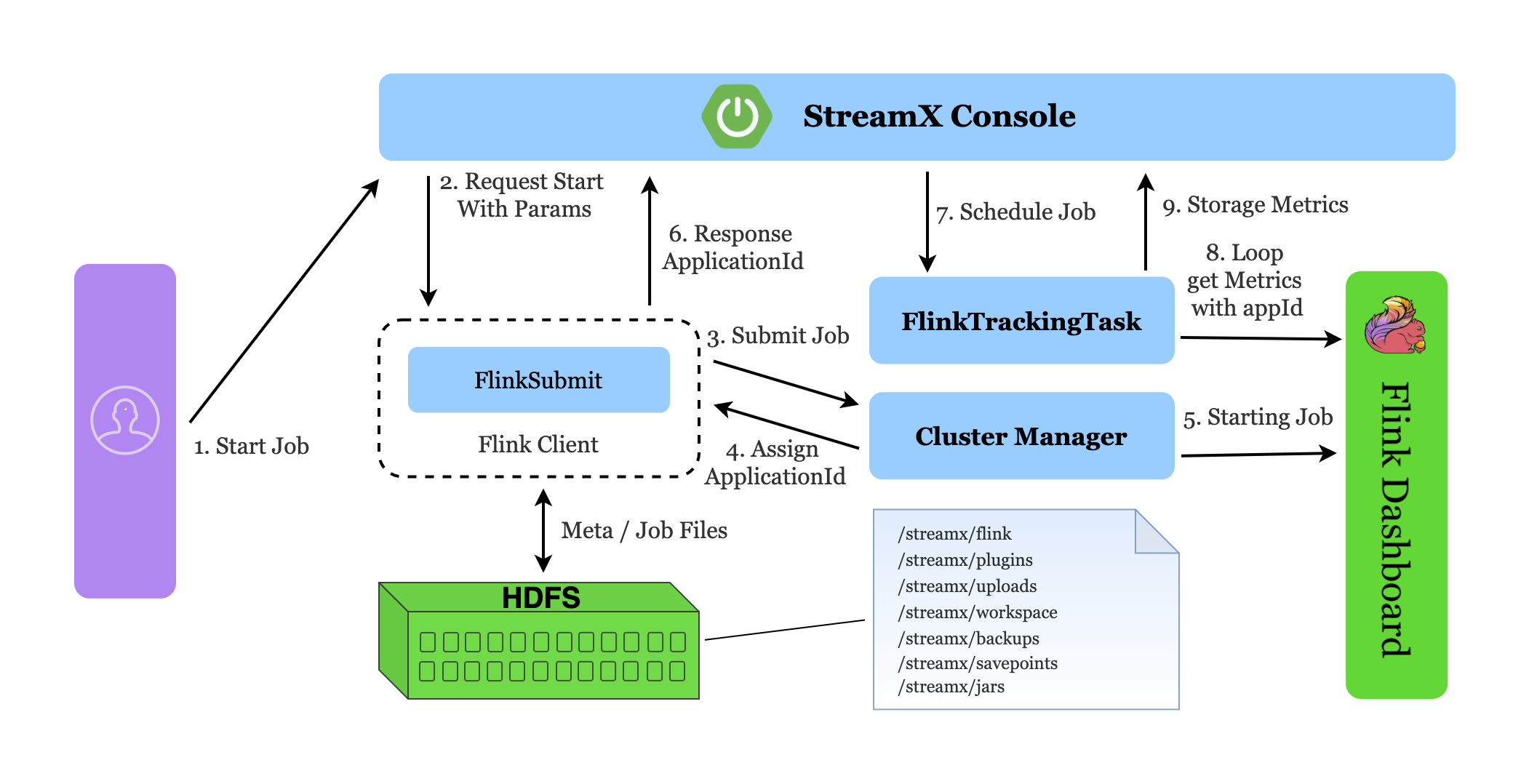
streampark-console submit task process
Regarding the concept of the project, Development Mode, savepoint, NoteBook, custom jar management, task release, task recovery, parameter configuration, parameter comparison, multi-version management and more tutorials and documents will be continuously updated. ..