雾芯科技创立于2018年1月。目前主营业务包括 RELX 悦刻品牌产品的研发、设计、制造及销售。凭借覆盖全产业链的核心技术与能力,RELX 悦刻致力于为用户提供兼具高品质和安全性的产品。
为什么选择 Native Kubernetes
Native Kubernetes 具有以下优势:
- 更短的 Failover 时间
- 可以实现资源托管,不需要手动创建 TaskManager 的 Pod,可以自动完成销毁
- 具有更加便捷的 HA,Flink 1.12 版本之后在 Native Kubernetes 模式下,可以依赖于原生 Kubernetes 的 Leader选举机制来完成 JobManager 的 HA
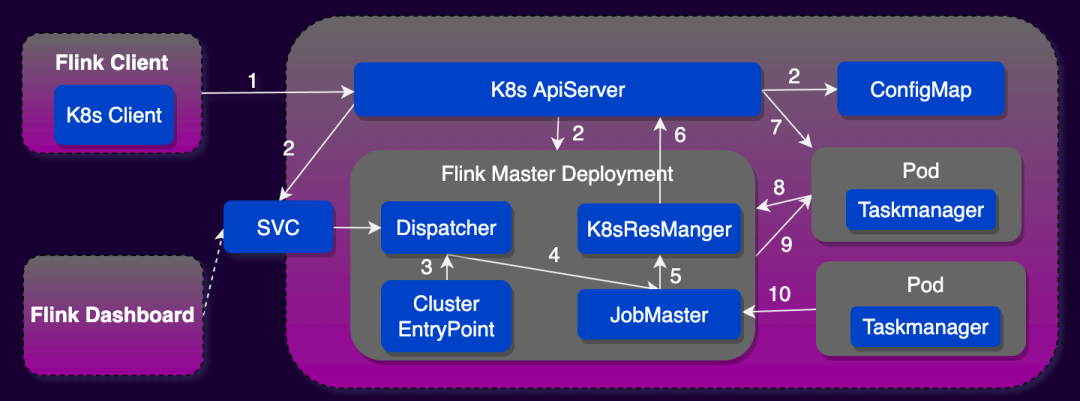
Native Kubernetes 和 Standalone Kubernetes 主要区别在于 Flink 与 Kubernetes 交互的方式不同以及由此产生的一系列优势。Standalone Kubernetes 需要用户自定义 JobManager 和 TaskManager 的 Kubernetes 资源描述文件,提交作业时需要用 kubectl 结合资源描述文件启动 Flink 集群。而 Native Kubernetes 模式 Flink Client 里面集成了一个 Kubernetes Client,它可以直接和 Kubernetes API Server 进行通讯,完成 JobManager Deployment 以及 ConfigMap 的创建。JobManager Development 创建完成之后,它里面的 Resource Manager 模块可以直接和 Kubernetes API Server 进行通讯,完成 TaskManager pod 的创建和销毁工作以及 Taskmanager 的弹性伸缩。因此生产环境中推荐使用 Flink on Native Kubernetes 模式部署 Flink 任务。
当 Flink On Kubernetes 遇见 Apache StreamPark™
Flink on Native Kubernetes 目前支持 Application 模式和 Session 模式,两者对比 Application 模式部署规避了 Session 模式的资源隔离问题、以及客户端资源消耗问题,因此**生产环境更推荐采用 Application Mode 部署 Flink 任务。**下面我们分别看看使用原始脚本的方式和使用 StreamPark 开发部署一个 Flink on Native Kubernetes 作业的流程。
使用脚本方式部署Kubernetes
在没有一个支持 Flink on Kubernetes 任务开发部署的平台的情况下,需要使用脚本的方式进行任务的提交和停止,这也是 Flink 提供的默认的方式,具体步骤如下:
- 在 Flink 客户端节点准备 kubectl 和 Docker 命令运行环境,创建部署 Flink 作业使用的 Kubernetes Namespace 和 Service Account 以及进行 RBAC
- 编写 Dockerfile 文件,将 Flink 基础镜像和用户的作业 Jar 打包到一起
FROM flink:1.13.6-scala_2.11
RUN mkdir -p $FLINK_HOME/usrlib
COPY my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
- 使用 Flink 客户端脚本启动 Flink 任务
./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.namespace=flink-cluster \
-Dkubernetes.jobmanager.service-account=default \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=relx_docker_url/streamx/relx_flink_1.13.6-scala_2.11:latest \
-Dkubernetes.rest-service.exposed.type=NodePort \
local:///opt/flink/usrlib/my-flink-job.jar
- 使用 Kubectl 命令获取到 Flink 作业的 WebUI 访问地址和 JobId
kubectl -n flink-cluster get svc
- 使用Flink命令停止作业
./bin/flink cancel
--target kubernetes-application
-Dkubernetes.cluster-id=my-first-application-cluster
-Dkubernetes.namespace=flink-cluster <jobId>
以上就是使用 Flink 提供的最原始的脚本方式把一个 Flink 任务部署到 Kubernetes 上的过程,只做到了最基本的��任务提交,如果要达到生产使用级别,还有一系列的问题需要解决,如:方式过于原始无法适配大批量任务、无法记录任务checkpoint 和实时状态跟踪、任务运维和监控困难、无告警机制、 无法集中化管理等等。
使用 Apache StreamPark™ 部署 Flink on Kubernetes
对于企业级生产环境使用 Flink on Kubernetes 会有着更高的要求,一般会选择自建平台或者购买相关商业产品,不论哪种方案在产品能力上满足: 大批量任务开发部署、状态跟踪、运维监控、失败告警、任务统一管理、高可用性 等这些是普遍的诉求。
针对以上问题我们调研了开源领域支持开发部署 Flink on Kubernetes 任务的开源项目,调研的过程中也不乏遇到了其他优秀的开源项目,在综合对比了多个开源项目后得出结论: **StreamPark 不论是完成度还是使用体验、稳定性等整体表现都非常出色,因此最终选择了 StreamPark 作为我们的一站式实时计算平台。**下面我们看看 StreamPark 是如何支持 Flink on Kubernetes :
基础环境配置
基础环境配置包括 Kubernetes 和 Docker 仓库信息以及 Flink 客户端的信息配置。对于 Kubernetes 基础环境最为简单的方式是直接拷贝 Kubernetes 节点的 .kube/config 到 StreamPark 节点用户目录,之后使用 kubectl 命令创建 Flink 专用的 Kubernetes Namespace 以及进行 RBAC 配置。
# 创建Flink作业使用的k8s namespace
kubectl create ns flink-cluster
# 对default用户进行RBAC资源绑定
kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=flink-cluster:default
Docker 账户信息直接在 Docker Setting 界面配置即可:
StreamPark 可适配多版本 Flink 作业开发,Flink 客户端直接在 StreamPark Setting 界面配置即可:
作业开发
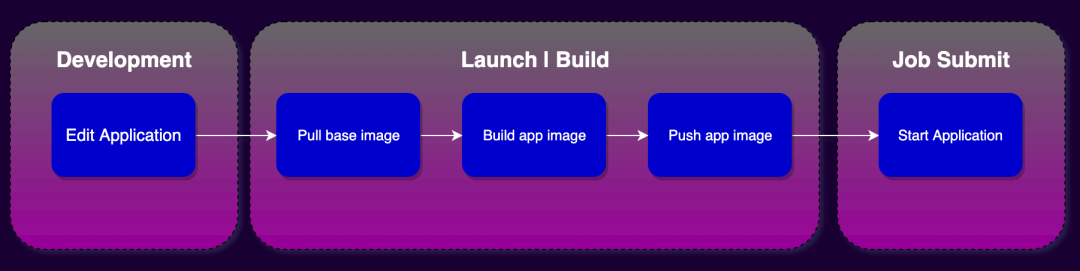
StreamPark 做好基础环境配置之后只需要三步即可开发部署一个 Flink 作业:
StreamPark 既支持 Upload Jar 也支持直接编写 Flink SQL 作业, Flink SQL 作业只需要输入SQL 和 依赖项即可, 该方式大大提升了开发体验, **并且规避了依赖冲突等问题,**对此部分本文不重点介绍。
这里需要选择部署模式为 kubernetes application, 并且需要在作业开发页面进行以下参数的配置:红框中参数为 Flink on Kubernetes 基础参数。
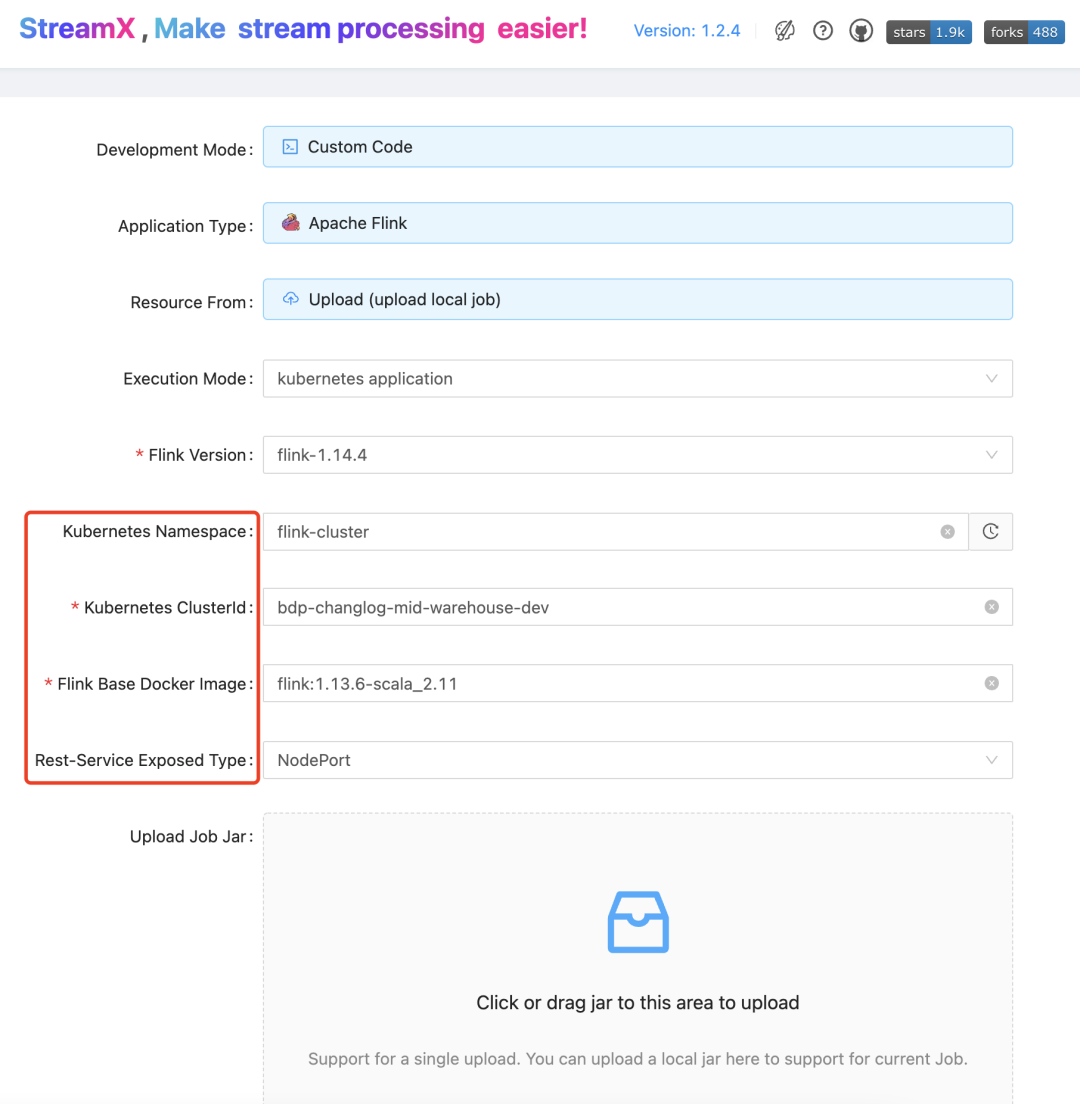
下面参数为 Flink 作业和资源相关的参数,Resolve Order 的选择与代码加载模式有关,对于 DataStream API 开发的 Upload Jar上传的作业选择使用 Child-first,Flink SQL 作业选择使用 Parent-first 加载。
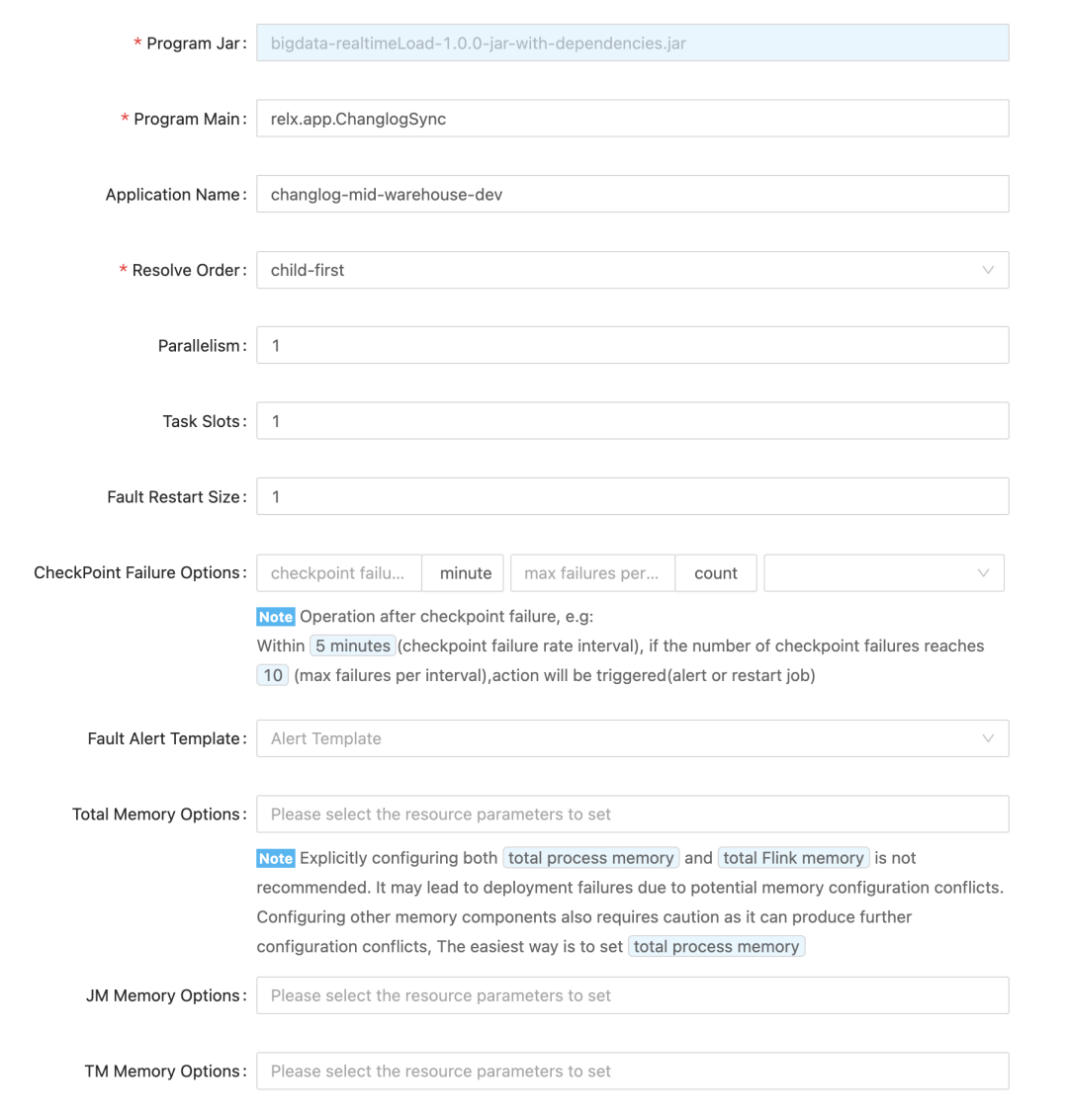
最后就是下面这两个重量级参数了,对于 Native Kubernetes 而言,k8s-pod-template 一般只需要进行 pod-template 配置即可,Dynamic Option 是 pod-template 参数的补充,对于一些个性化配置可以在 Dynamic Option 中配置。更多 Dynamic Option 直接参考 Flink 官网即可。
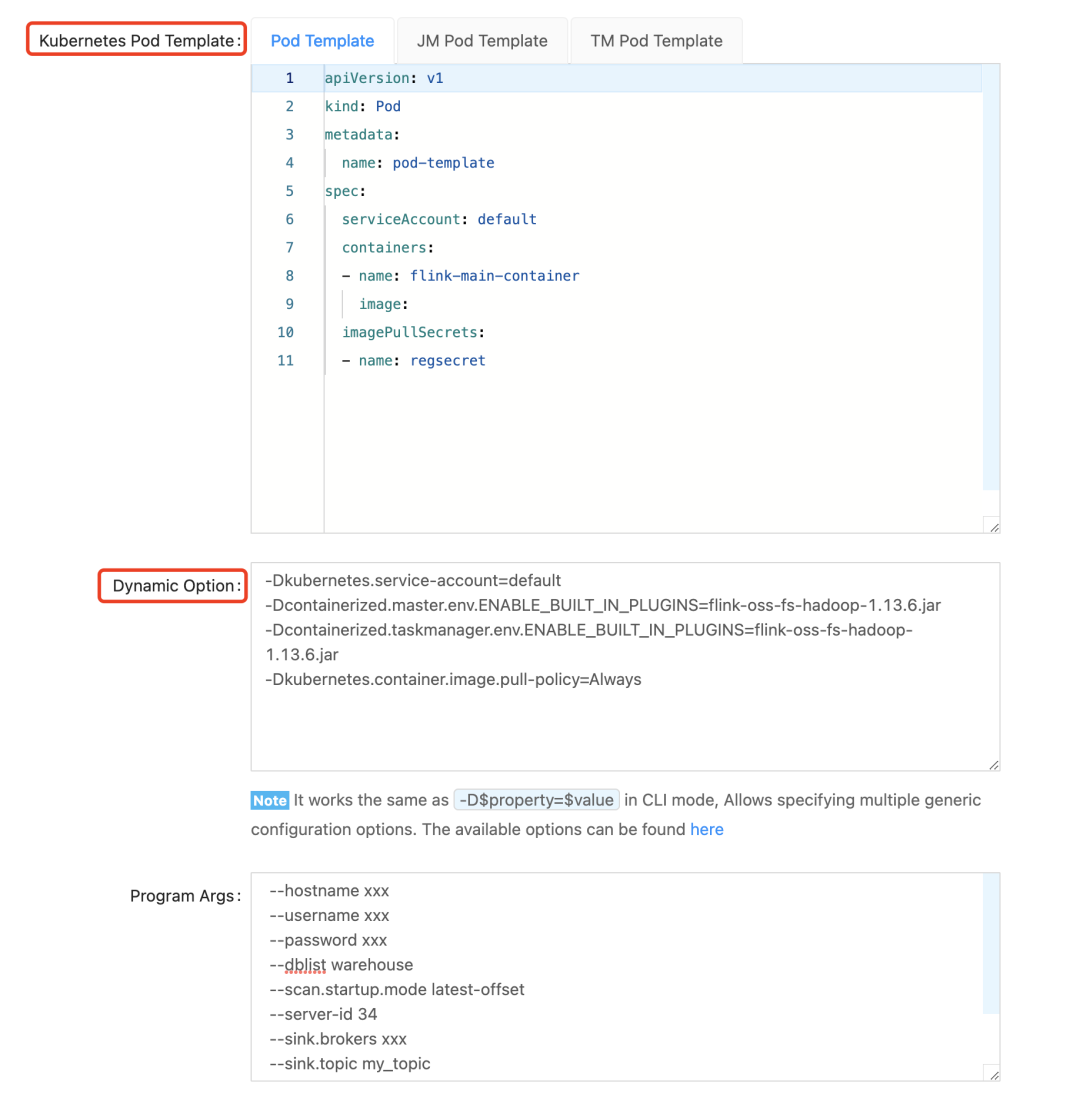
作业上线
作业开发完成之后是作业上线环节,在这一环节中 StreamPark 做了大量的工作,具体如下:
- 准备环境
- 作业中的依赖下载
- 构建作业(打JAR包)
- 构建镜像
- 推送镜像到远程仓库
对于用户来说: 只需要点击任务列表中的云状的上线按钮即可。
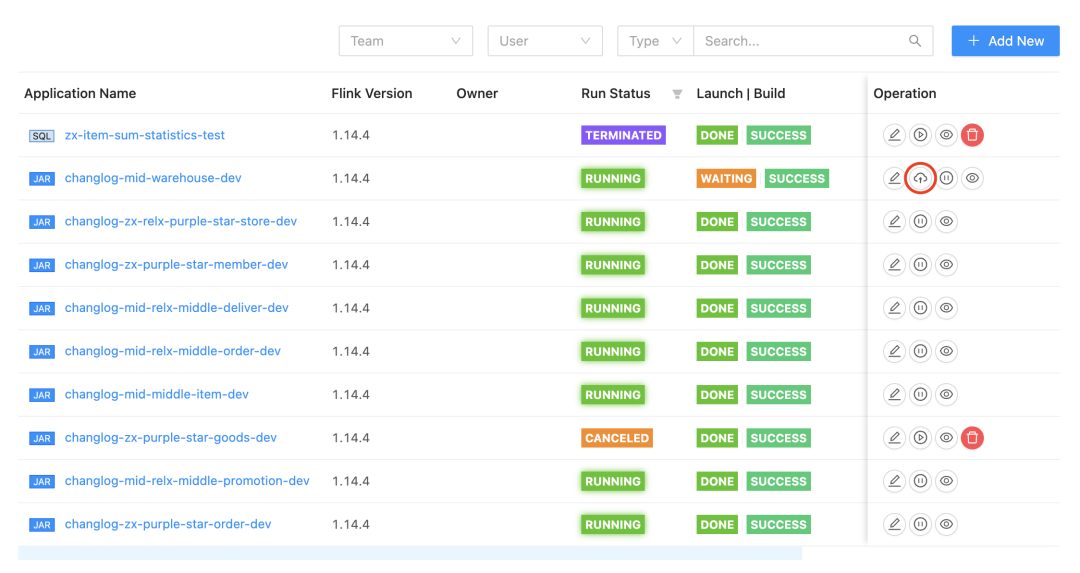
在镜像构建和推送的时候我们可以看到 StreamPark 做的一系列工作: 读取配置、构建镜像、推送镜像到远程仓库... 这里要给StreamPark 一个大大的赞!
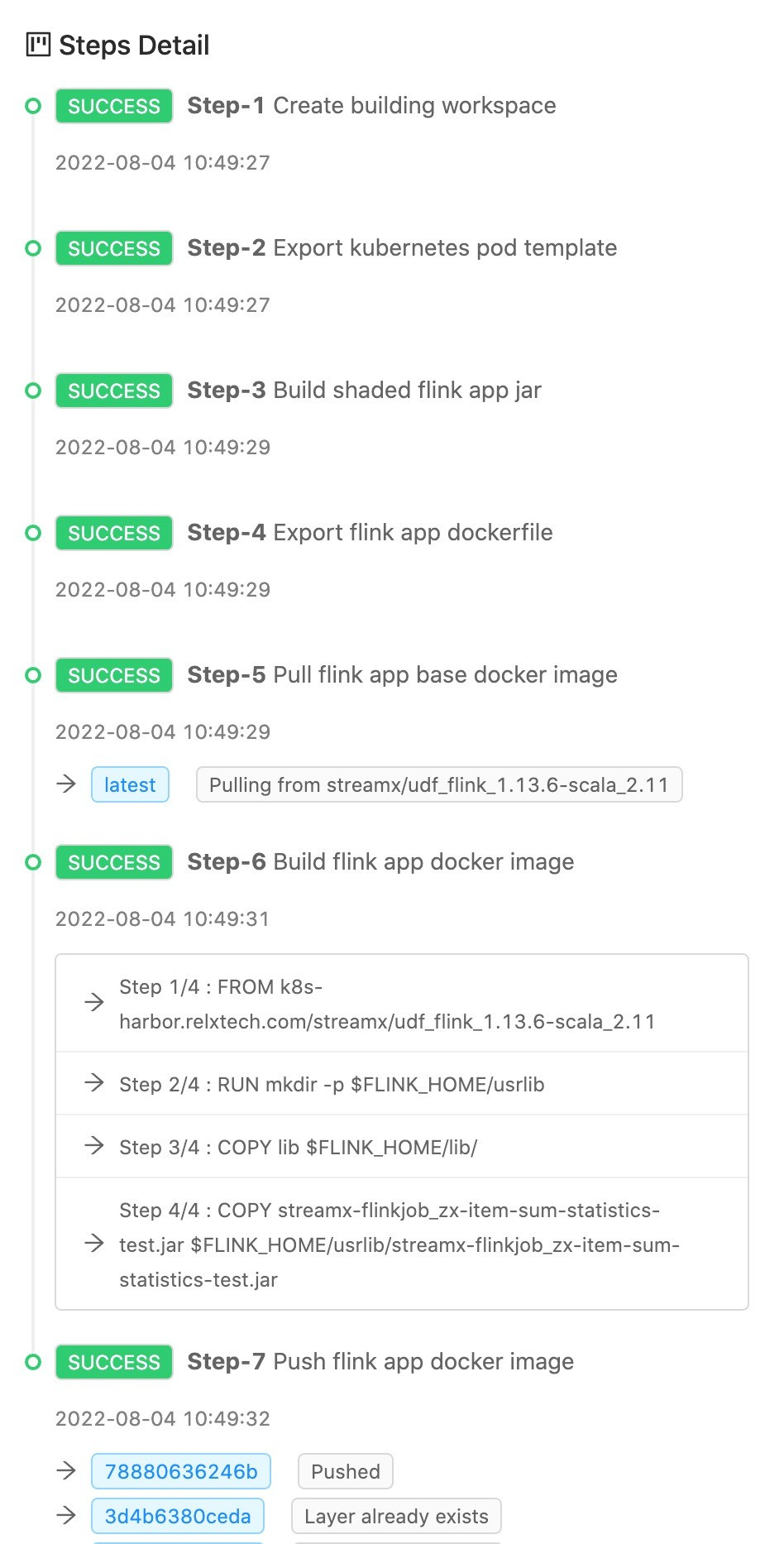
作业提交
最后只需要点击 Operation 里 start Application 按钮便可启动一个 Flink on Kubernetes 作业,作业启动成功之后点击作业名便可跳转到 Jobmanager WebUI 页面、整个过程非常简单丝滑。

整个过程仅需上述三步,即可完成在 StreamPark 上开发和部署一个Flink on Kubernetes 作业。而 StreamPark 对于 Flink on Kubernetes 的支持远远不止提交个任务这么简单。
作业管理
在作业提交之后,StreamPark 能实时获取到任务的最新 checkpoint 地址、任务的运行状态、集群实时的资源消耗信息,针对运行的任务可以非常方便的一键启停, 在停止作业时支持记录 savepoint 的位置, 以及再次启动时从 savepoint 恢复状态等功能,从而保证了生产环境的数据一致性,真正具备 Flink on Kubernetes 的 一站式开发、部署、运维监控的能力。
接下来我们来看看这一块的能力 StreamPark 是如何进行支持的:
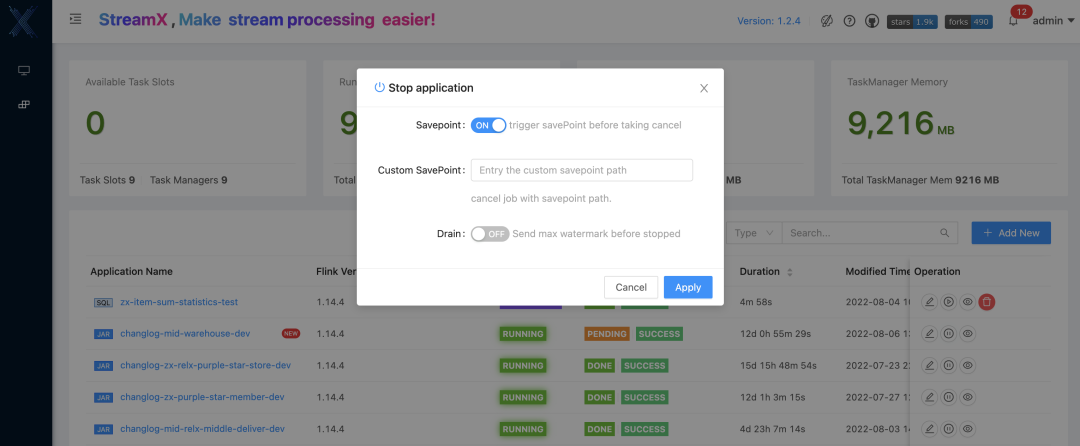
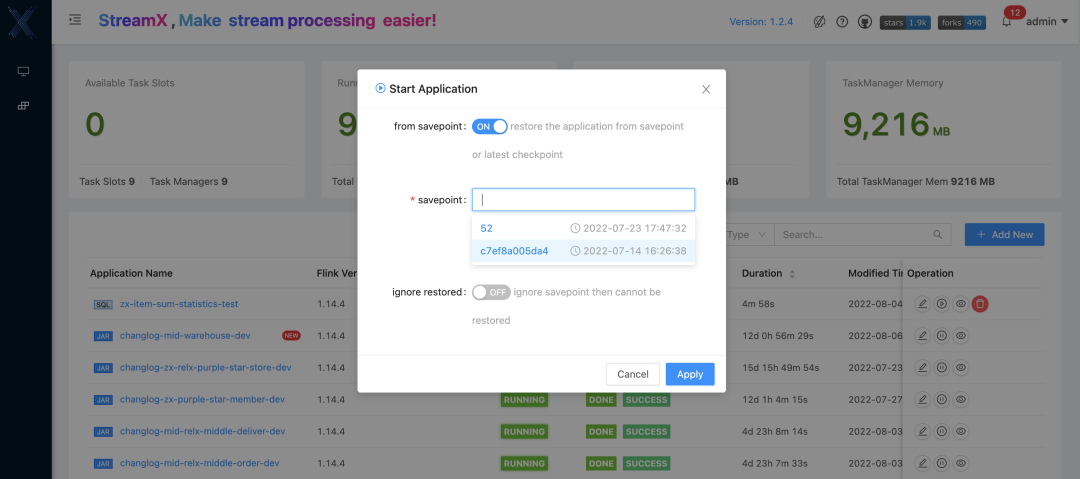
- 实时记录checkpoint
在作业提交之后,有时候需要更改作业逻辑但是要保证数据的一致性,那么就需要平台具有实时记录每一次 checkpoint 位置的能力, 以及停止时记录最后的 savepoint 位置的能力,StreamPark 在 Flink on Kubernetes 上很好的实现了该功能。默认会每隔5秒获取一次 checkpoint 信息记录到对应的表中,并且会按照 Flink 中保留 checkpoint 数量的策略,只保留 state.checkpoints.num-retained 个,超过的部分则删除。在任务停止时有勾选 savepoint 的选项,如勾选了savepoint 选项,在任务停止时会做 savepoint 操作,同样会记录 savepoint 具体位置到表中。
默认 savepoint 的根路径只需要在 Flink Home flink-conf.yaml 文件中配置即可自动识别,除了默认地址,在停止时也可以自定义指定 savepoint 的根路径。
- 实时跟踪运行状态
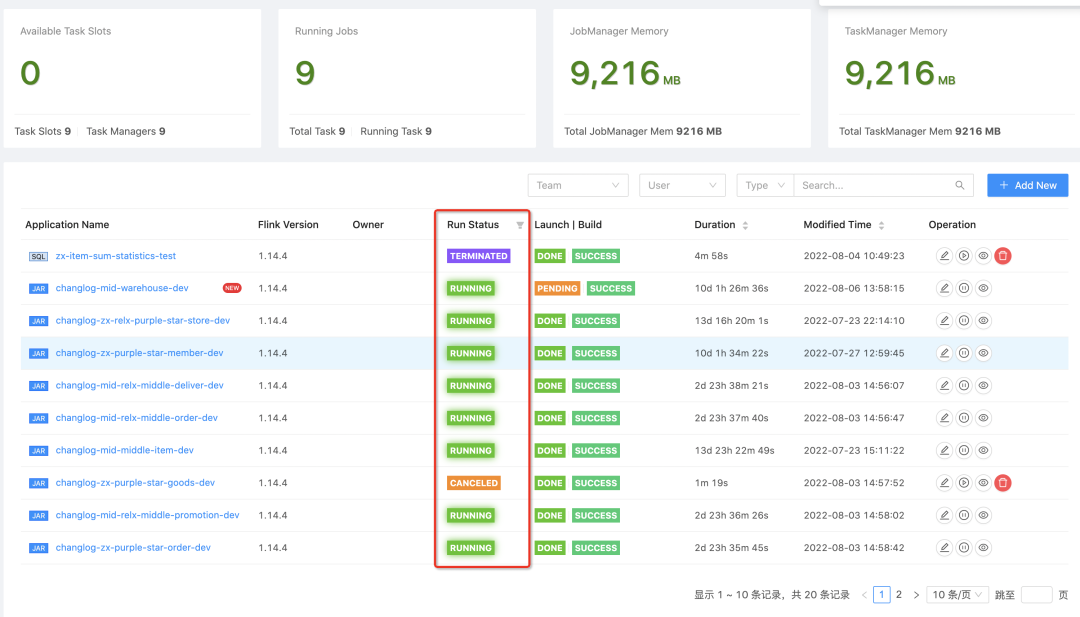
对于生产环境的挑战,很重要的一点就是监控是否到位,Flink on Kubernetes 更是如此。这点很重要, 也是最基本需要具备的能力,StreamPark 可实时监控 Flink on Kubernetes 作业的运行状态并在平台上展示给用户,在页面上可以很方便的根据各种运行状态来检索任务。
- 完善的告警机制
除此之外 StreamPark 还具备完善的报警功能: 支持邮件、钉钉、微信和短信 等。这也是当初公司调研之后选择 StreamPark 作为 Flink on Kubernetes 一站式平台的重要原因。
通过以上我们看到 StreamPark 在支持 Flink on Kubernetes 开发部署过程中具备的能力, 包括:作业的开发能力、部署能力、监控能力、运维能力、异常处理能力等,StreamPark 提供的是一套相对完整的解决方案。 且已经具备了一些 CICD/DevOps 的能力,整体的完成度还在持续提升。是在整个开源领域中对于 Flink on Kubernetes 一站式开发部署运维工作全链路都支持的产品,StreamPark 是值得被称赞的。
Apache StreamPark™ 在雾芯科技的落地实践
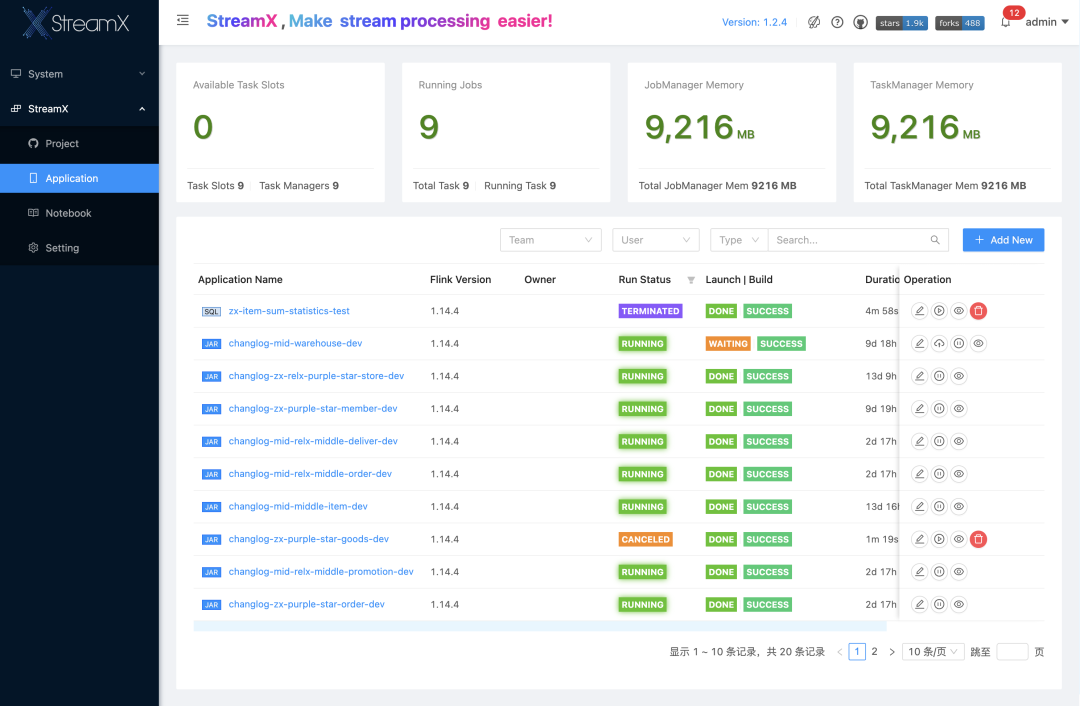
StreamPark 在雾芯科技落地较晚,目前主要用于实时数据集成作业和实时指标计算作业的开发部署,有 Jar 任务也有 Flink SQL 任务,全部使用 Native Kubernetes 部署;数据源有CDC、Kafka 等,Sink 端有 Maxcompute、kafka、Hive 等,以下是公司开发环境StreamPark 平台截图:
遇到的问题
任何新技术都有探索与踩坑的过程,失败的经验是宝贵的,这里介绍下 StreamPark 在雾芯科技落地过程中踩的一些坑和经验,这块的内容不仅仅关于 StreamPark 的部分, 相信会带给所有使用 Flink on Kubernetes 的小伙伴一些参考。
常见问题总结如下
- kubernetes pod 拉取镜像失败
这个问题主要在于 Kubernetes pod-template 缺少 docker的 imagePullSecrets
- scala 版本不一致
由于 StreamPark 部署需要 Scala 环境,而且 Flink SQL 运行需要用到 StreamPark 提供的 Flink SQL Client,因此一定要保证 Flink 作业的 Scala 版本和 StreamPark 的 Scala 版本保持一致。
- 注意类冲突
进行 Flink SQL 作业开发的时候需要注意 Flink 镜像和 Flink connector 及 UDF 中有没有类冲突,最好的避免类冲突的办法是将 Flink 镜像和常用的 Flink connector 及用户 UDF 打成一个可用的基础镜像,之后其他 Flink SQL 作业直接复用即可。
- 没有 Hadoop 环境怎么存储 checkpoint?
HDFS 阿里云 OSS/AWS S3 都可以进行 checkpoint 和 savepoint 存储,Flink 基础镜像已经有了对于 OSS 和 S3 的支持,如果没有 HDFS 可以使用阿里云 OSS 或者 S3存储状态和 checkpoint 和 savepoint 数据,只需要在 Flink 动态参数中简单配置一下即可。
-Dstate.backend=rocksdb
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-oss-fs-hadoop-1.13.6.jar
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-oss-fs-hadoop-1.13.6.jar
-Dfs.oss.endpoint=xxyy.aliyuncs.com
-Dfs.oss.accessKeyId=xxxxxxxxxx
-Dfs.oss.accessKeySecret=xxxxxxxxxx
-Dstate.checkpoints.dir=oss://realtime-xxx/streamx/dev/checkpoints/
-Dstate.savepoints.dir=oss://realtime-xxx/streamx/dev/savepoints/
- 改了代码重新发布后并未生效
该问题与 Kubernetes pod 镜像拉取策略有关,建议将 Pod 镜像拉取策略设置为 Always:
-Dkubernetes.container.image.pull-policy=Always
- 任务每次重启都会导致多出一个 Job 实例
在配置了基于 kubernetes 的HA的前提条件下,当需要停止 Flink 任务时,需要通过 StreamPark 的 cancel 来进行,不要直接通过 kubernetes 集群删除 Flink 任务的 Deployment。因为 Flink 的关闭有其自有的关闭流程,在删除 pod 同时 Configmap 中的相应配置文件也会被一并删除,而直接删除 pod 会导致 Configmap 的残留。当相同名称的任务重启时,会出现两个相同 Job 现象,因为在启动时,任务会加载之前残留的配置文件,尝试将已经关闭的任务恢复。
- kubernetes pod 域名访问怎么实现
域名配置只需要按照 Kubernetes 资源在 pod-template 中配置即,可针对以上问题给大家分享一个本人总结的一个 pod-template.yaml 模板:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
serviceAccount: default
containers:
- name: flink-main-container
image:
imagePullSecrets:
- name: regsecret
hostAliases:
- ip: "192.168.0.1"
hostnames:
- "node1"
- ip: "192.168.0.2"
hostnames:
- "node2"
- ip: "192.168.0.3"
hostnames:
- "node3"
最佳实践
悦刻的大数据组件很多基于阿里云,比如 Maxcompute、阿里云 Redis,同时我们这边 Flink SQL 作业需要用到一些 UDF。最开始我们是采用使用 Flink Base image + maven dependency + upload udf jar 的方式,但是实践过程中遇到了一些比如版本冲突、类冲突的问题,同时如果是大批量作业的话这种方式开发效率比较低,最后我们采取将公司级别的常用的 Flink connector 和 udf 和 Flink base image 打包成公司级别的基础镜像,新 Flink SQL 作业使用该基础镜像之后直接写 Flink SQL 即可,大大提高了开发效率。
下面分享一个制作基础镜像的简单步骤:
1. 准备需要的 JAR
将常用 Flink Connector Jar 和用户 Udf Jar 放置在同一文件夹 lib 下,以下都是Flink 1.13.6 常用的一些 connector 包
bigdata-udxf-1.0.0-shaded.jar
flink-connector-jdbc_2.11-1.13.6.jar
flink-sql-connector-kafka_2.11-1.13.6.jar
flink-sql-connector-mysql-cdc-2.0.2.jar
hudi-flink-bundle_2.11-0.10.0.jar
ververica-connector-odps-1.13-vvr-4.0.7.jar
ververica-connector-redis-1.13-vvr-4.0.7.jar
2. 准备 Dockerfile
创建 Dockerfile 文件,并将 Dockerfile 文件跟上面文件夹放置在同一文件夹下
FROM flink:1.13.6-scala_2.11COPY lib $FLINK_HOME/lib/
3. 基础镜像制作并推送私有仓库
docker login --username=xxxdocker \
build -t udf_flink_1.13.6-scala_2.11:latest \
.docker tag udf_flink_1.13.6-scala_2.11:latest \
k8s-harbor.xxx.com/streamx/udf_flink_1.13.6-scala_2.11:latestdocker \
push k8s-harbor.xxx.com/streamx/udf_flink_1.13.6-scala_2.11:latest
未来期待
- StreamPark 对于 Flink 作业 Metric 监控的支持
StreamPark 如果可以对接 Flink Metric 数据而且可以在 StreamPark 平台上展示每时每刻 Flink 的实时消费数据情况就太棒了
- StreamPark 对于Flink 作业日志持久化的支持
对于部署到 YARN 的 Flink 来说,如果 Flink 程序挂了,我们可以去 YARN 上看历史日志,但是对于 Kubernetes 来说,如果程序挂了,那么 Kubernetes 的 pod 就消失了,就没法查日志了。所以用户需要借助 Kubernetes 上的工具进行日志持久化,如果 StreamPark 支持 Kubernetes 日志持久化接口就更好了。
- 镜像过大的问题改进
StreamPark 目前对于 Flink on Kubernetes 作业的镜像支持是将基础镜像和用户代码打成一个 Fat 镜像推送到 Docker 仓库,这种方式存在的问题就是镜像过大的时候耗时比较久,希望未来基础镜像可以复用不需要每次都与业务代码打到一起,这样可以极大地提升开发效率和节约成本。