Quick Start
Note: This section is designed to provide a convenient process for submitting Flink jobs using the StreamPark platform through simple operational steps.
Configure FLINK_HOME
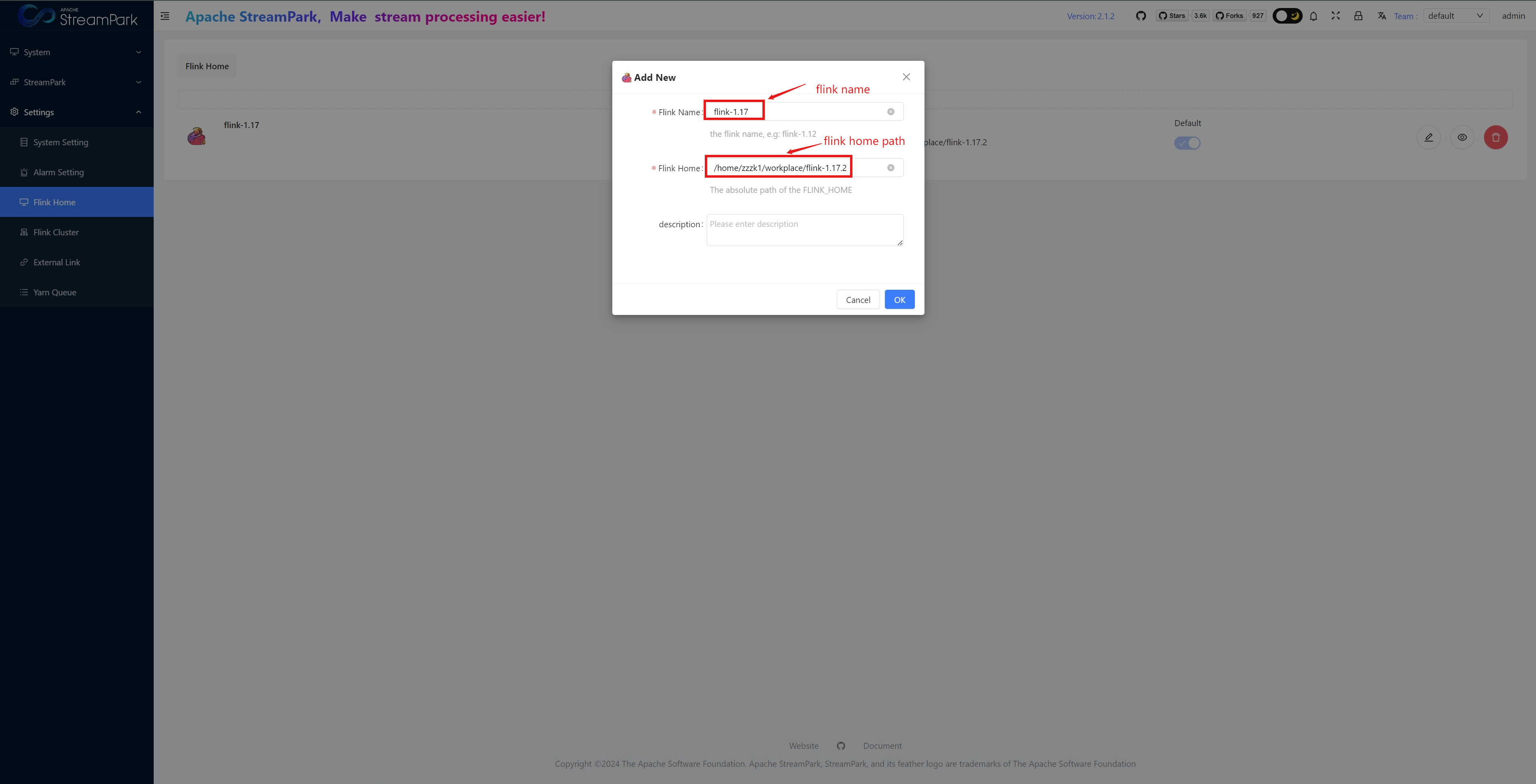
Click "OK" to save
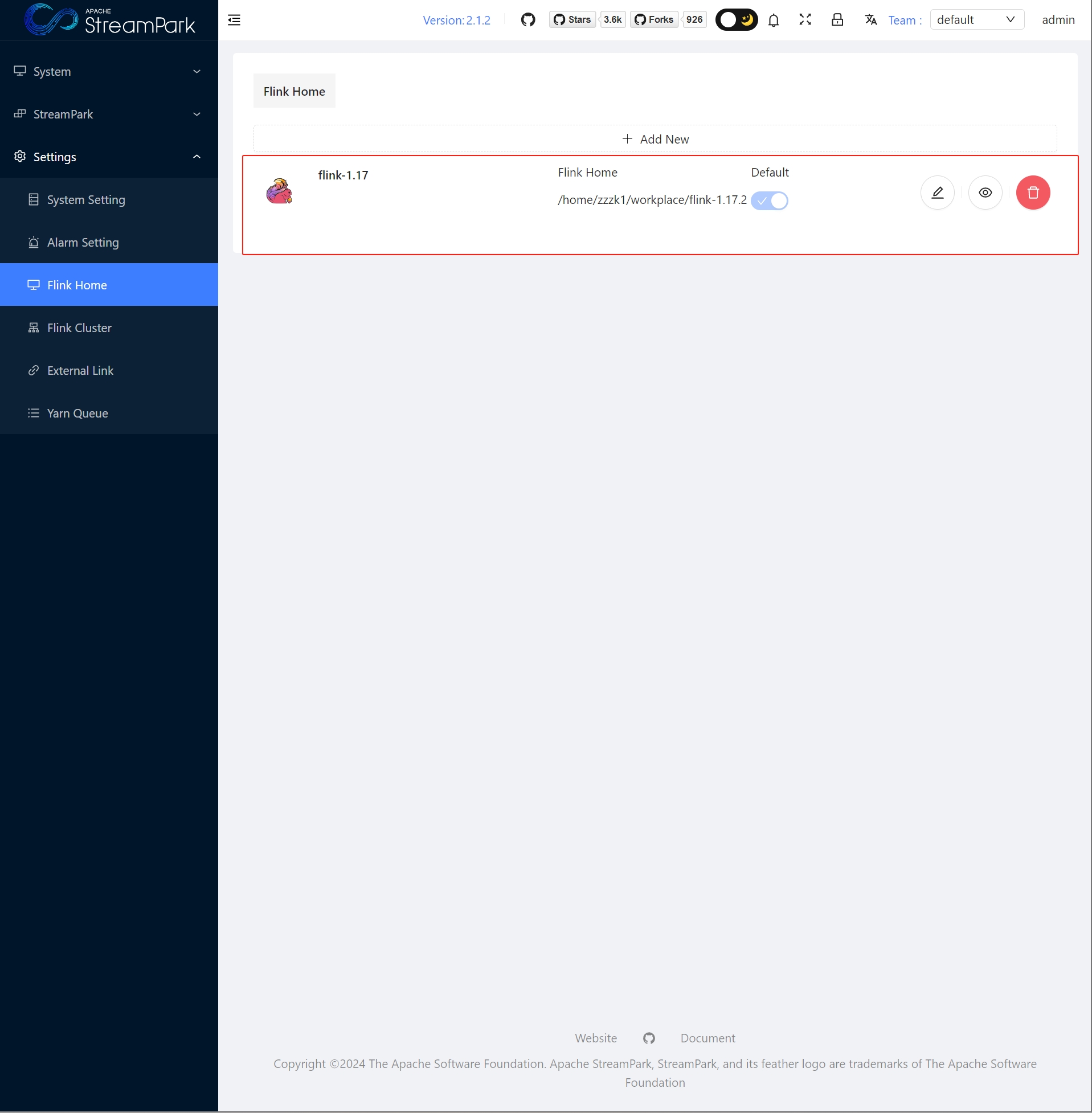
Configure Flink Cluster
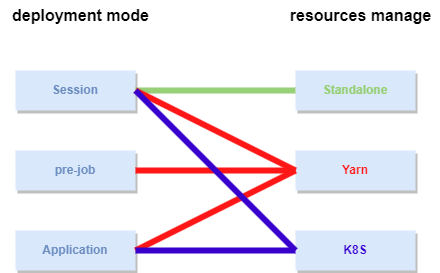
Depending on the Flink deployment mode and resource management method, StreamPark supports the following six job modes:
- Standalone Session
- Yarn Session
- Yarn Per-job
- Yarn Application
- K8s Session
- K8s Application
For this guide, choose the simpler Standalone Session mode (indicated by the green line in the image below) for a quick start.
Start Flink Standalone Session on Server
start-cluster.sh

Page access: http://vm:8081/
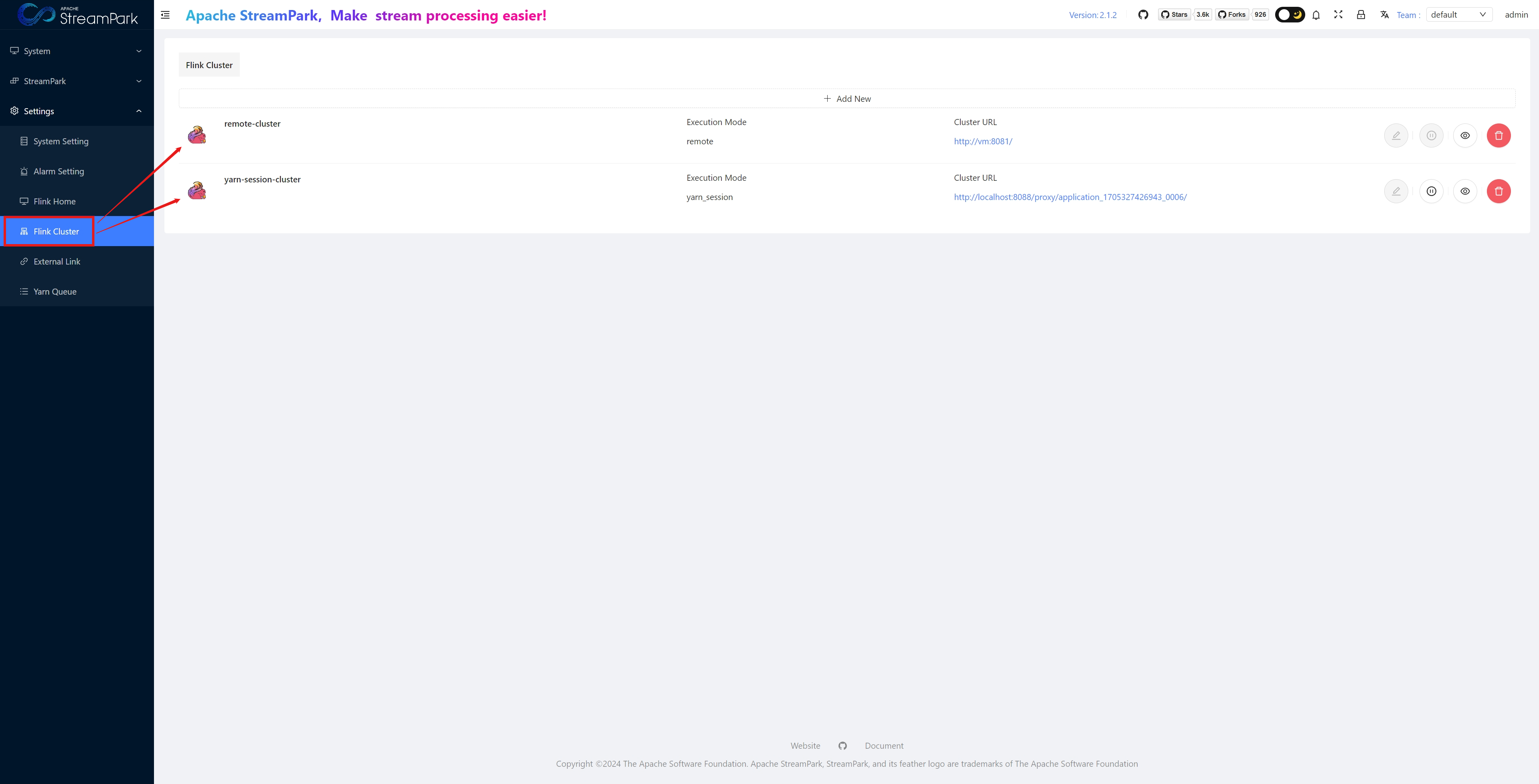
Configure Flink Cluster
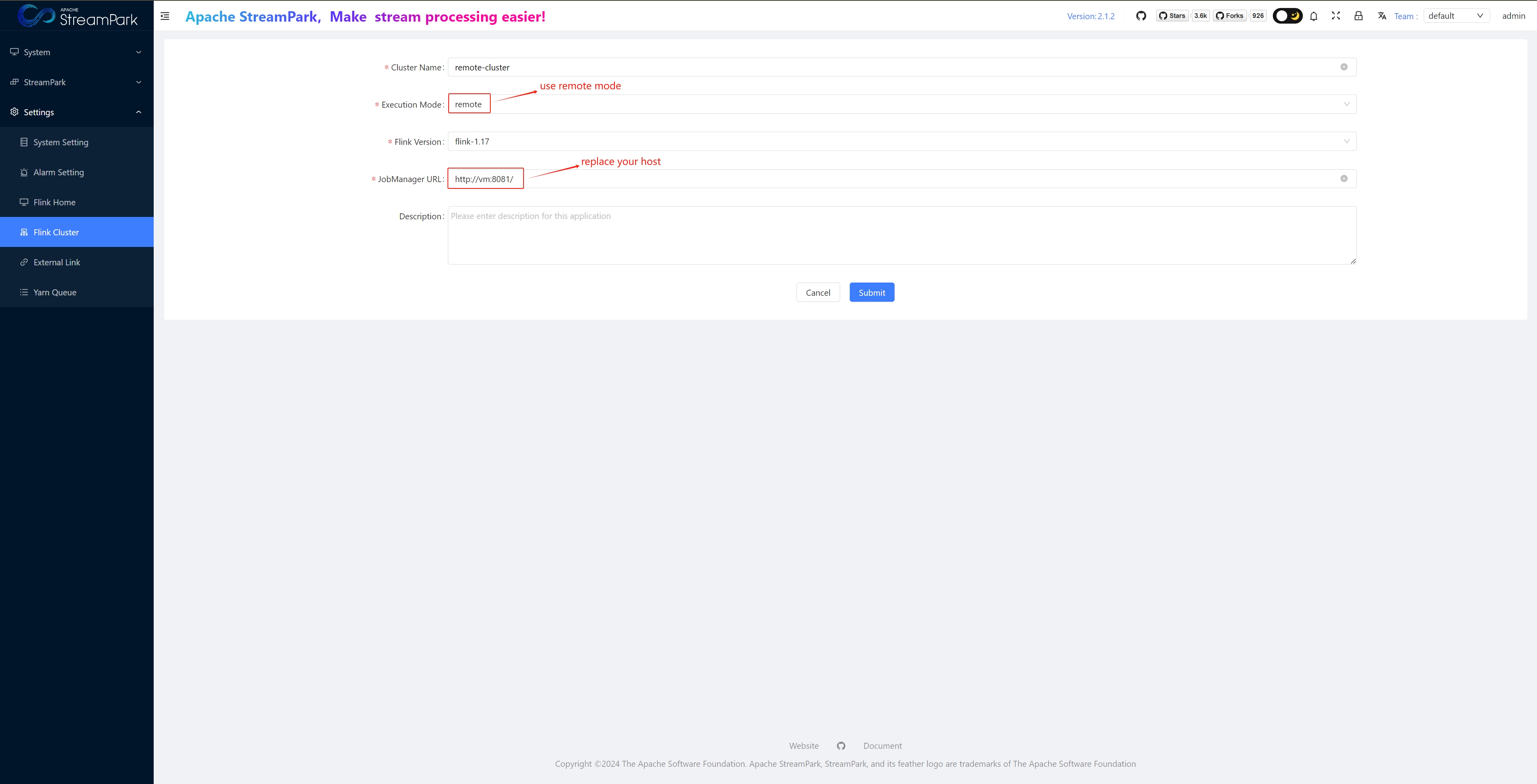
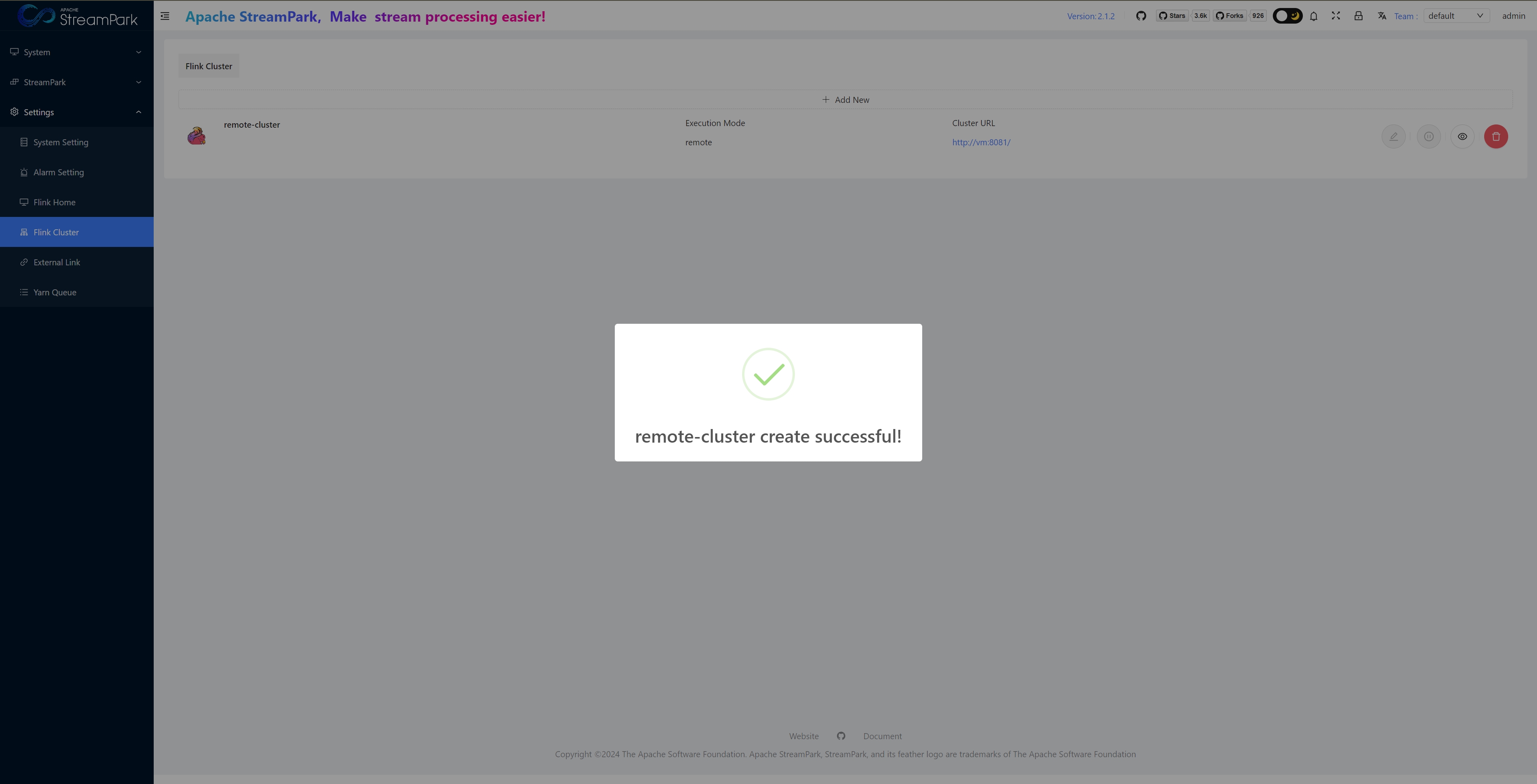
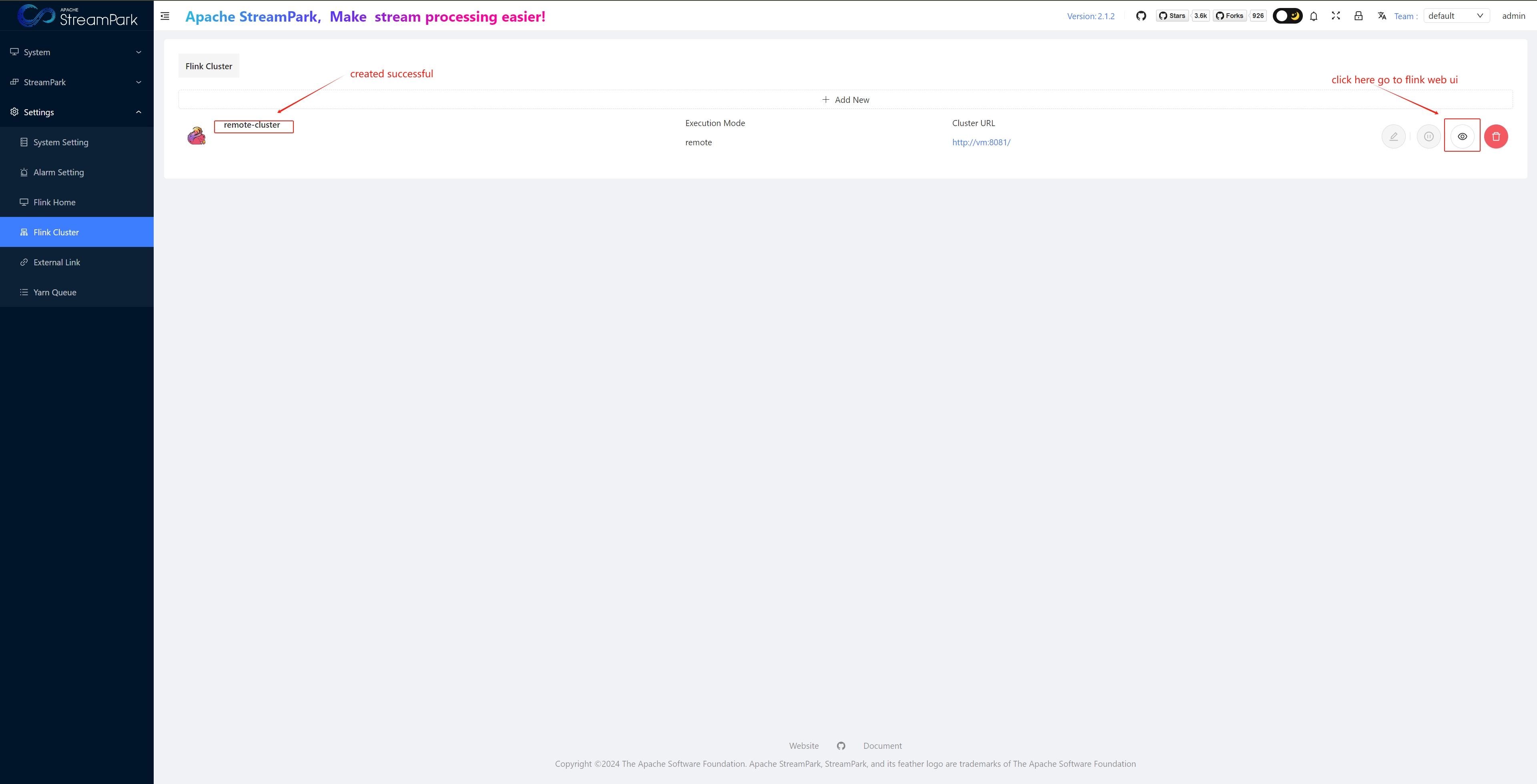
Create Job
Main Parameters
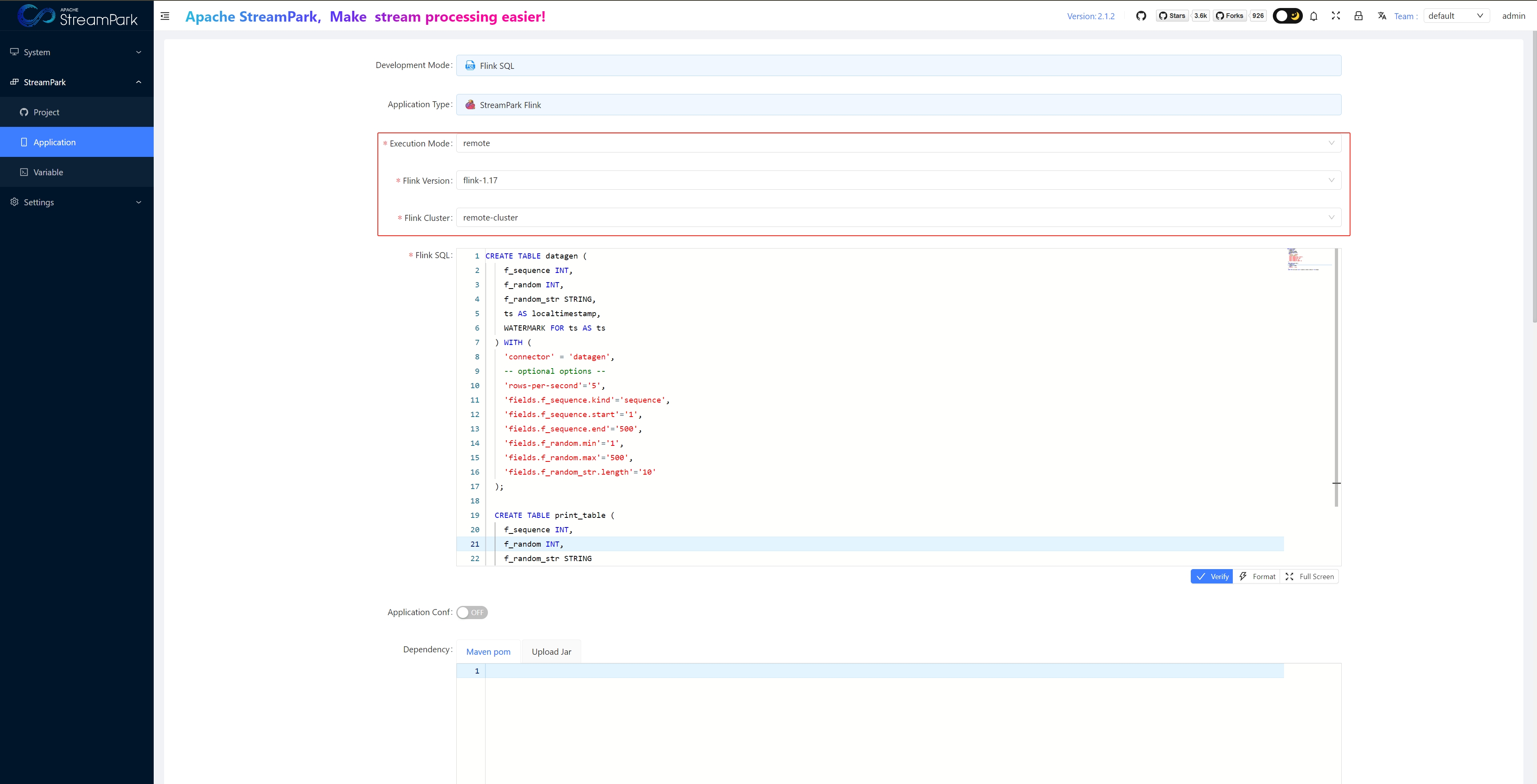
- Development Mode: Choose “Flink SQL”
- Execution Mode: Choose “remote”
- Flink Version: Select "flink-1.17", as configured in “1.1 Configure FLINK_HOME”
- Flink Cluster: Select “myStandalonSession”, as configured in “1.2 Configure FLINK Cluster”
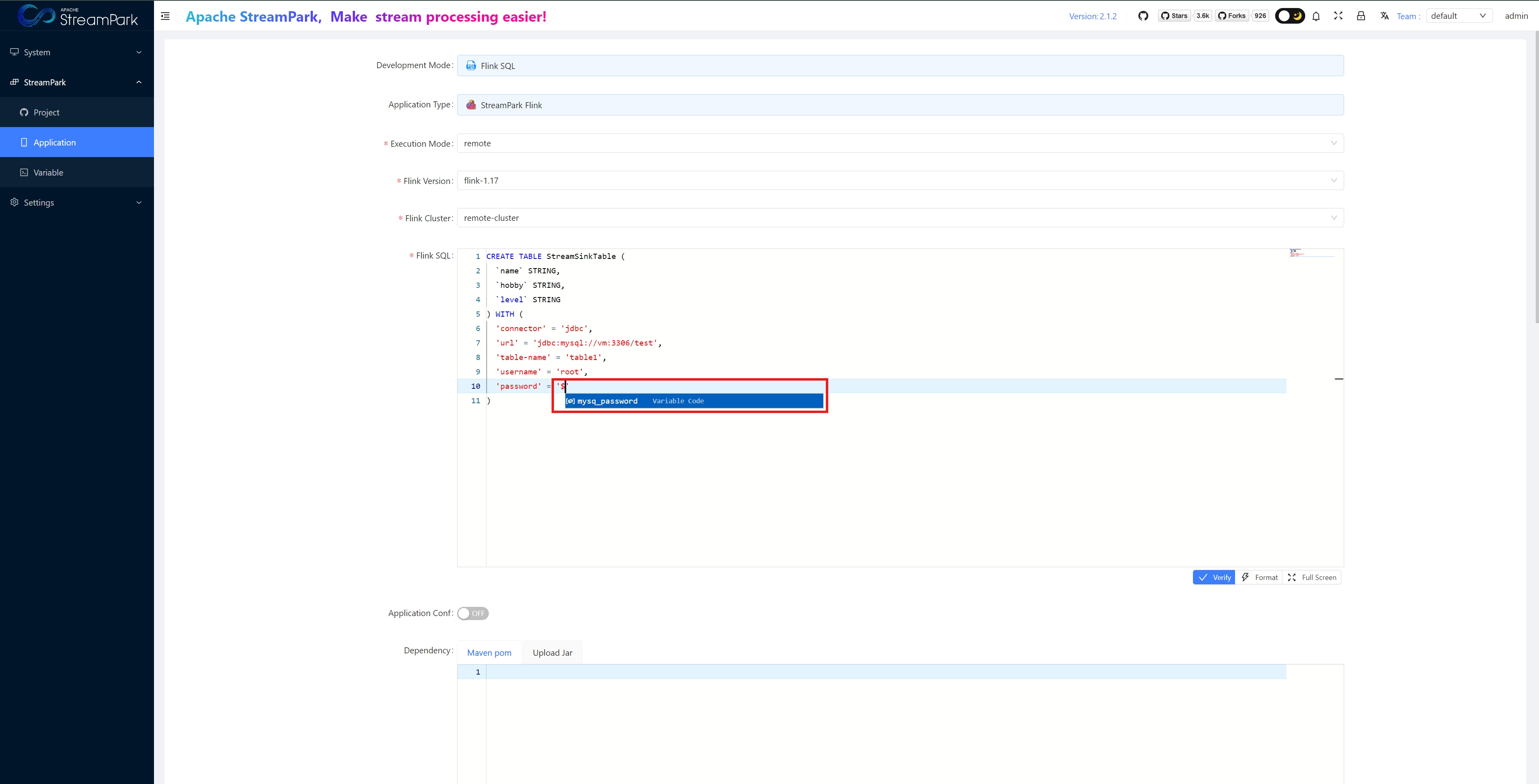
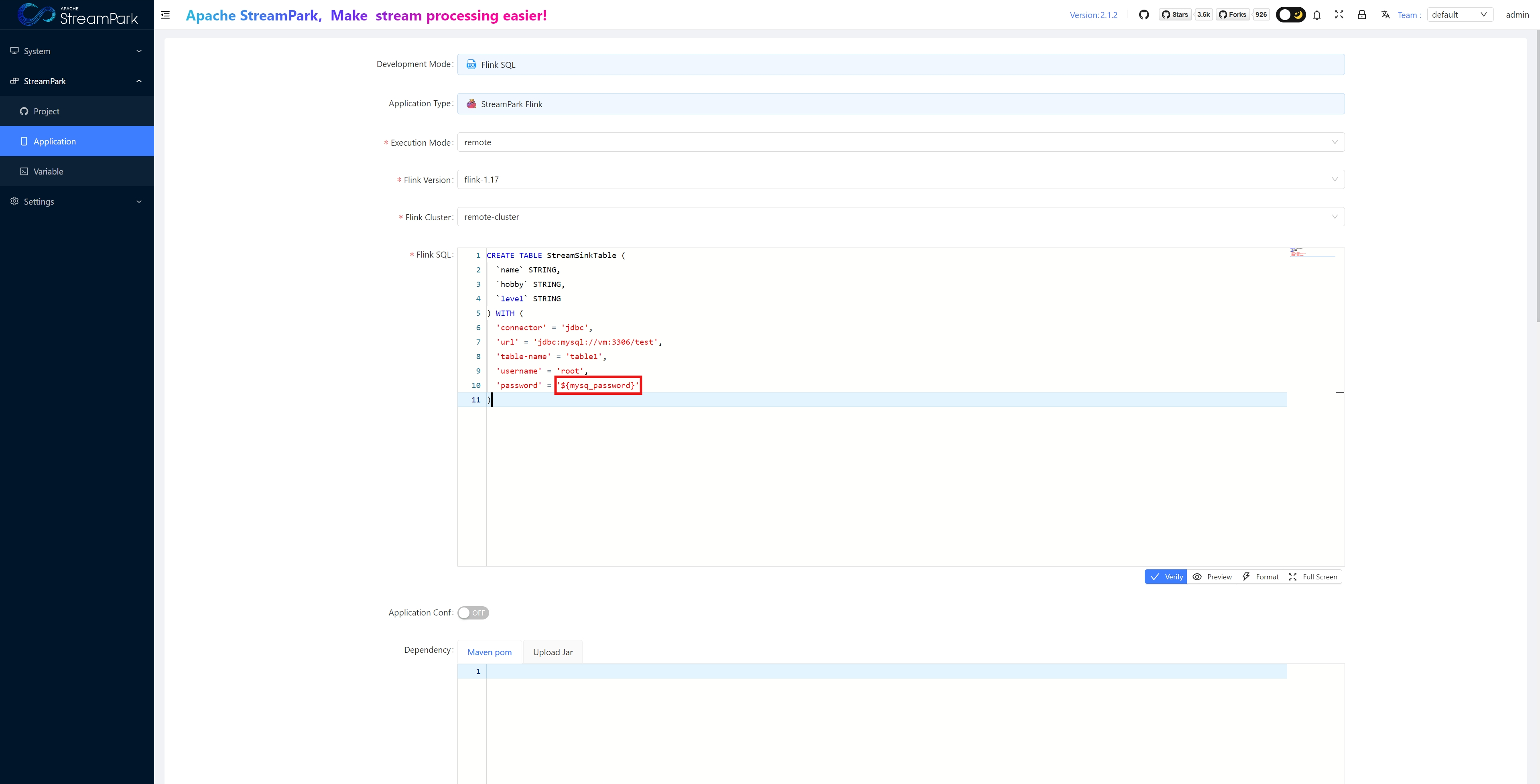
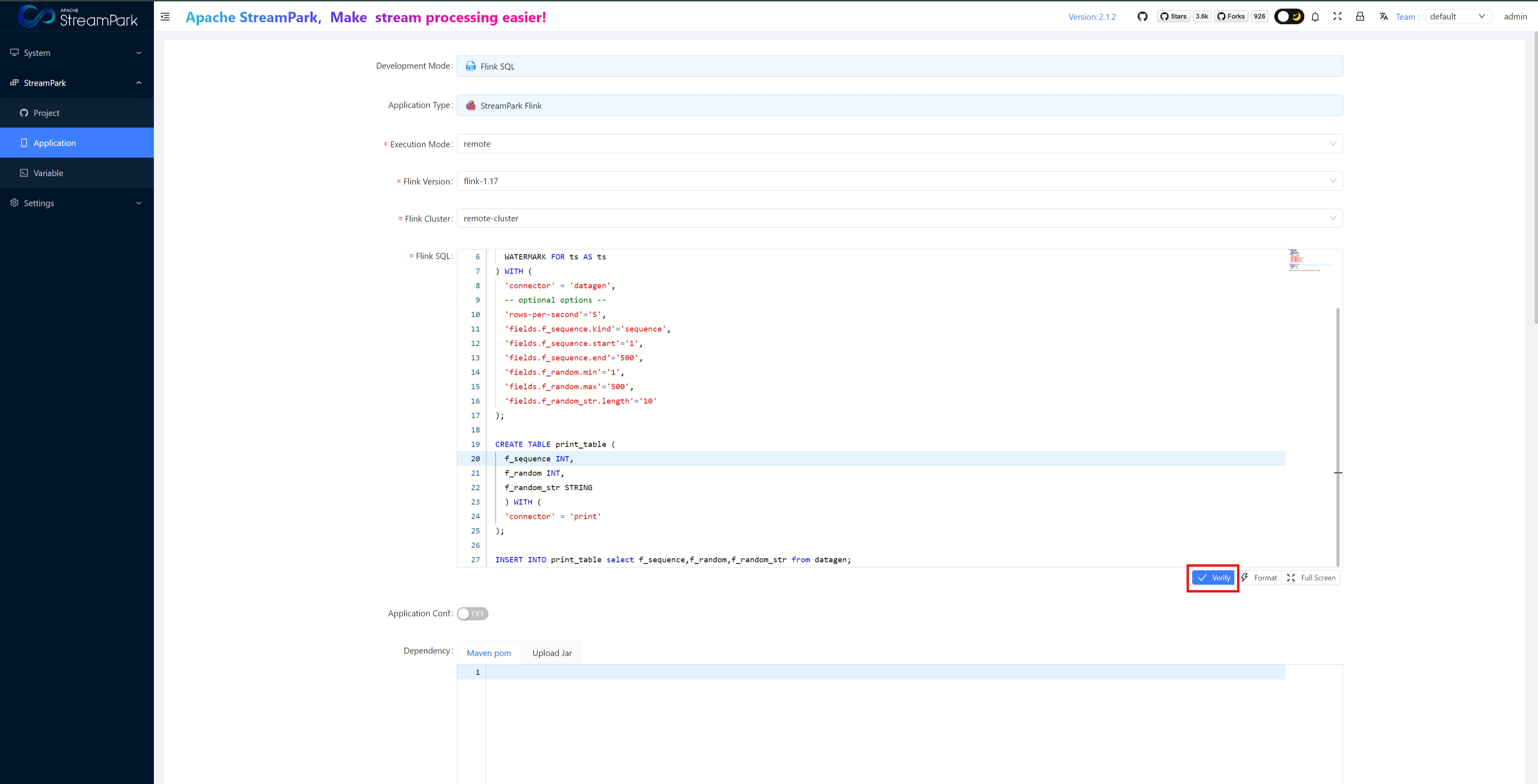
- Flink SQL: See example below
- Application Name: Job name
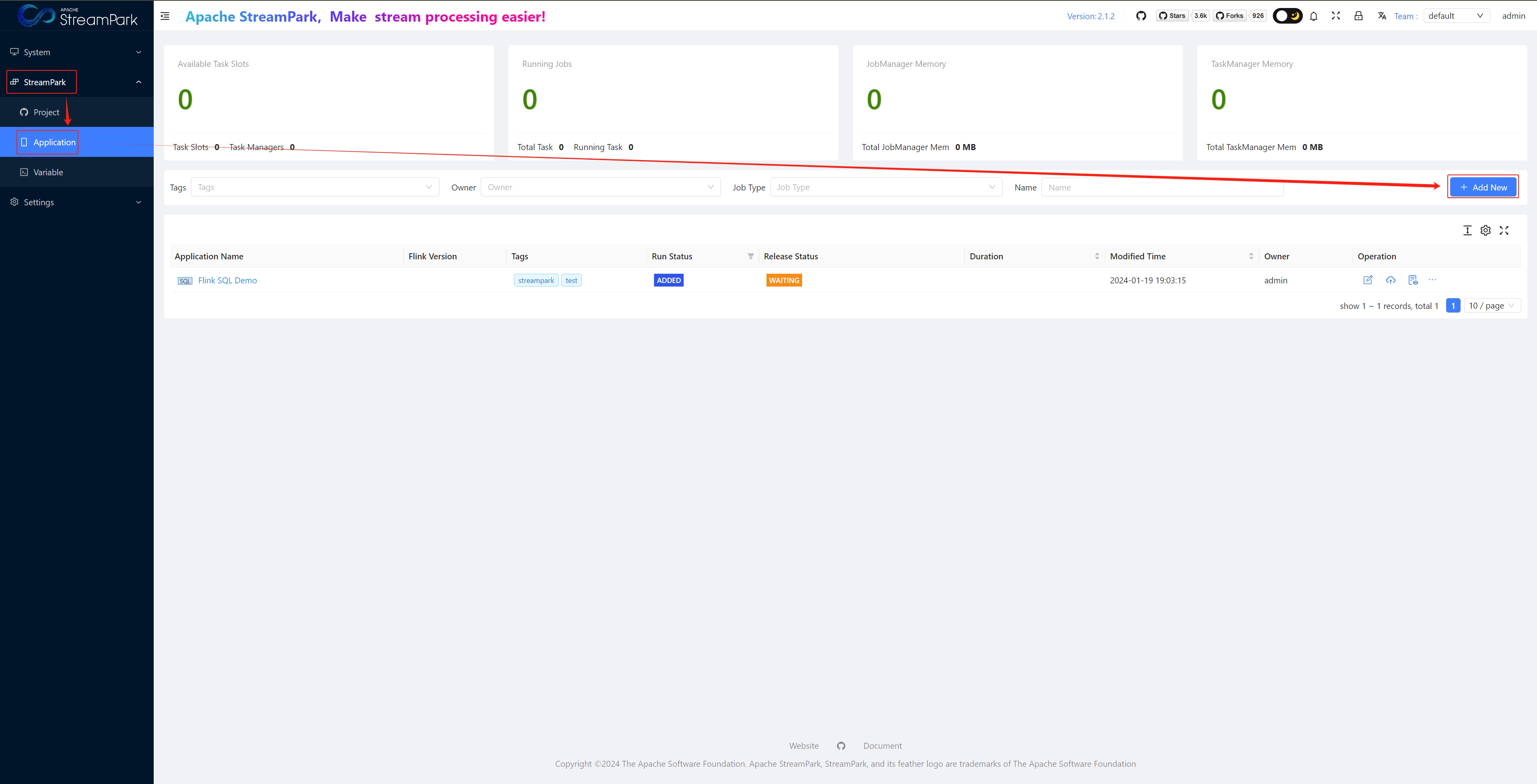
Create Job
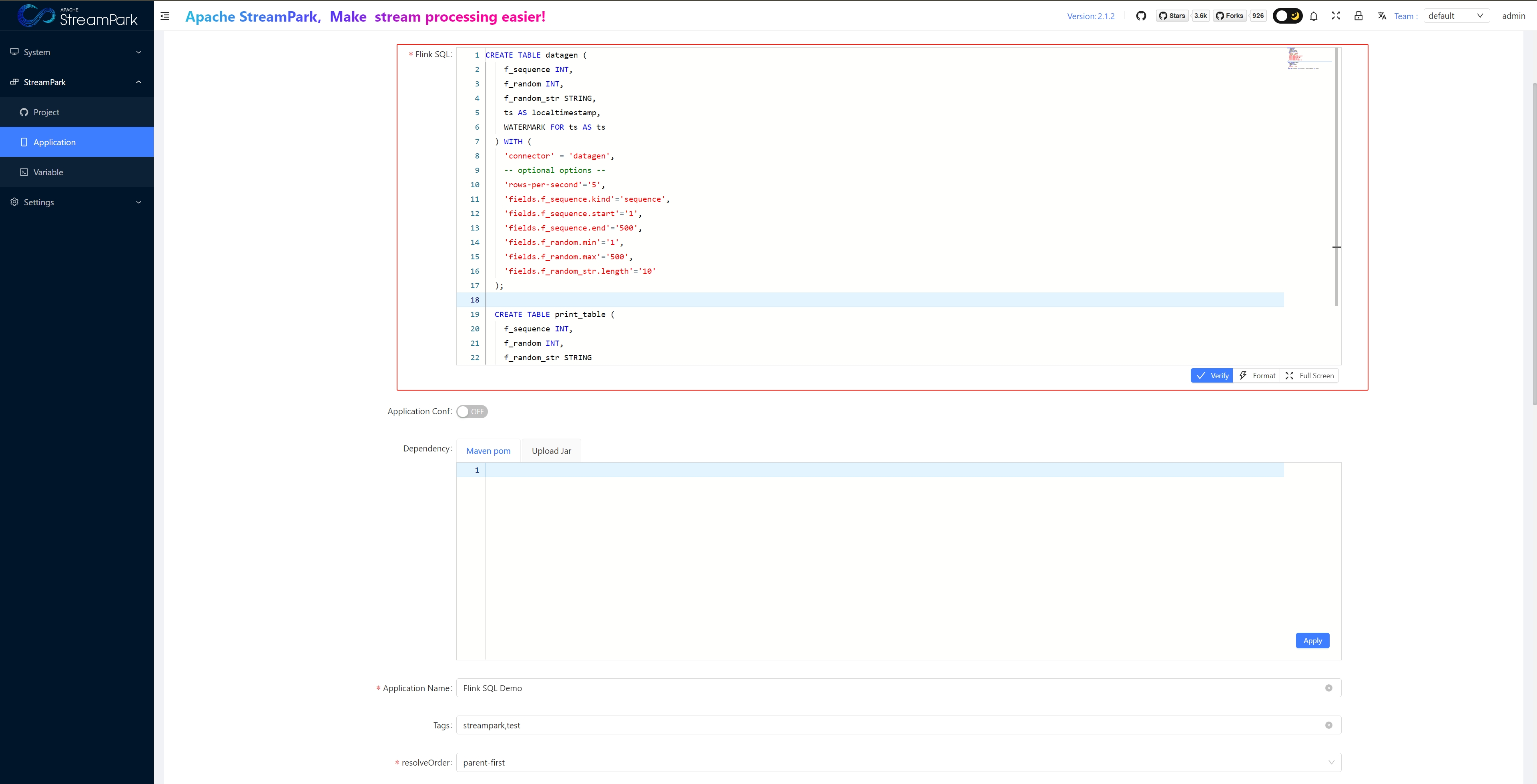
Save Job
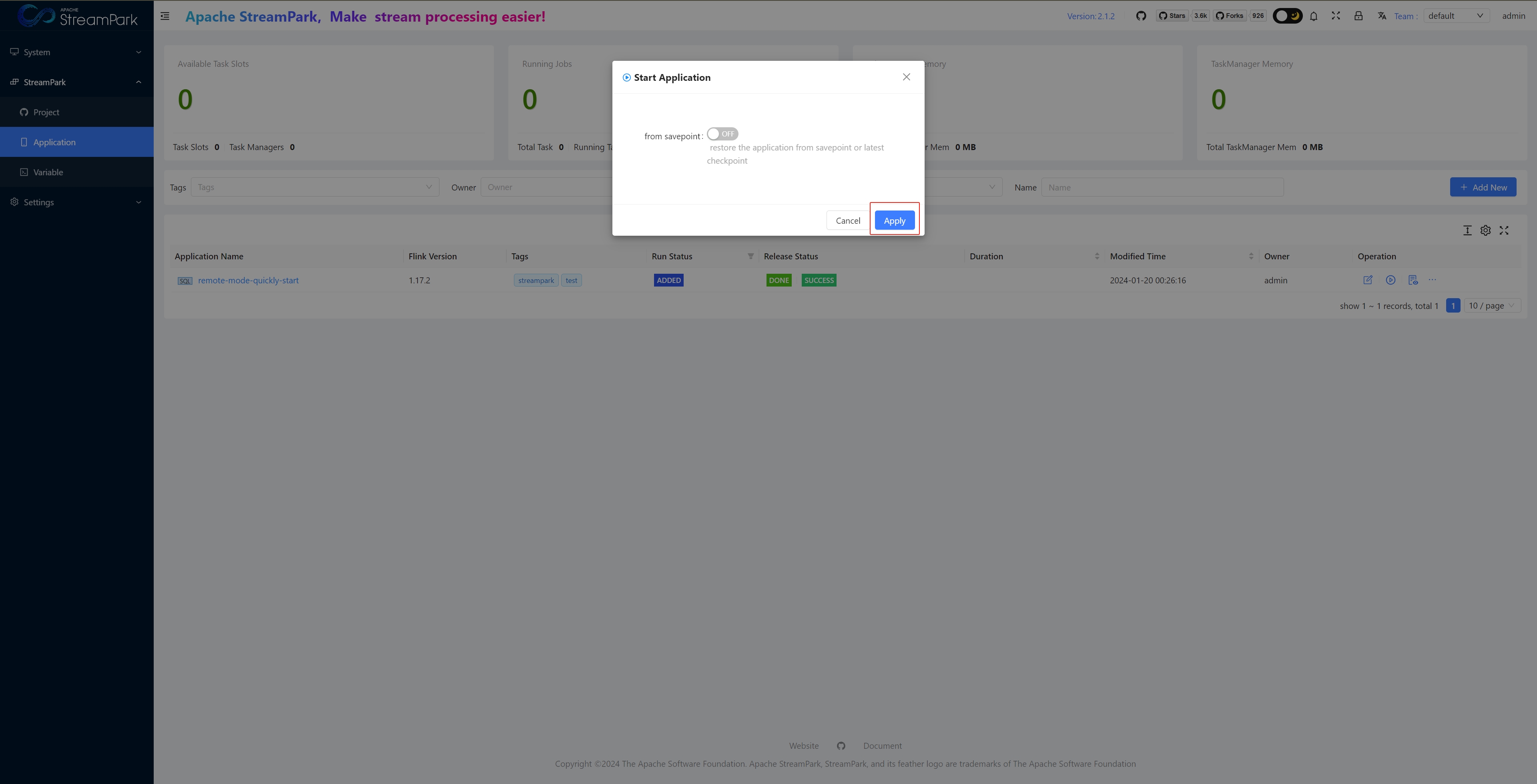
Click the blue “Submit” button to submit the job
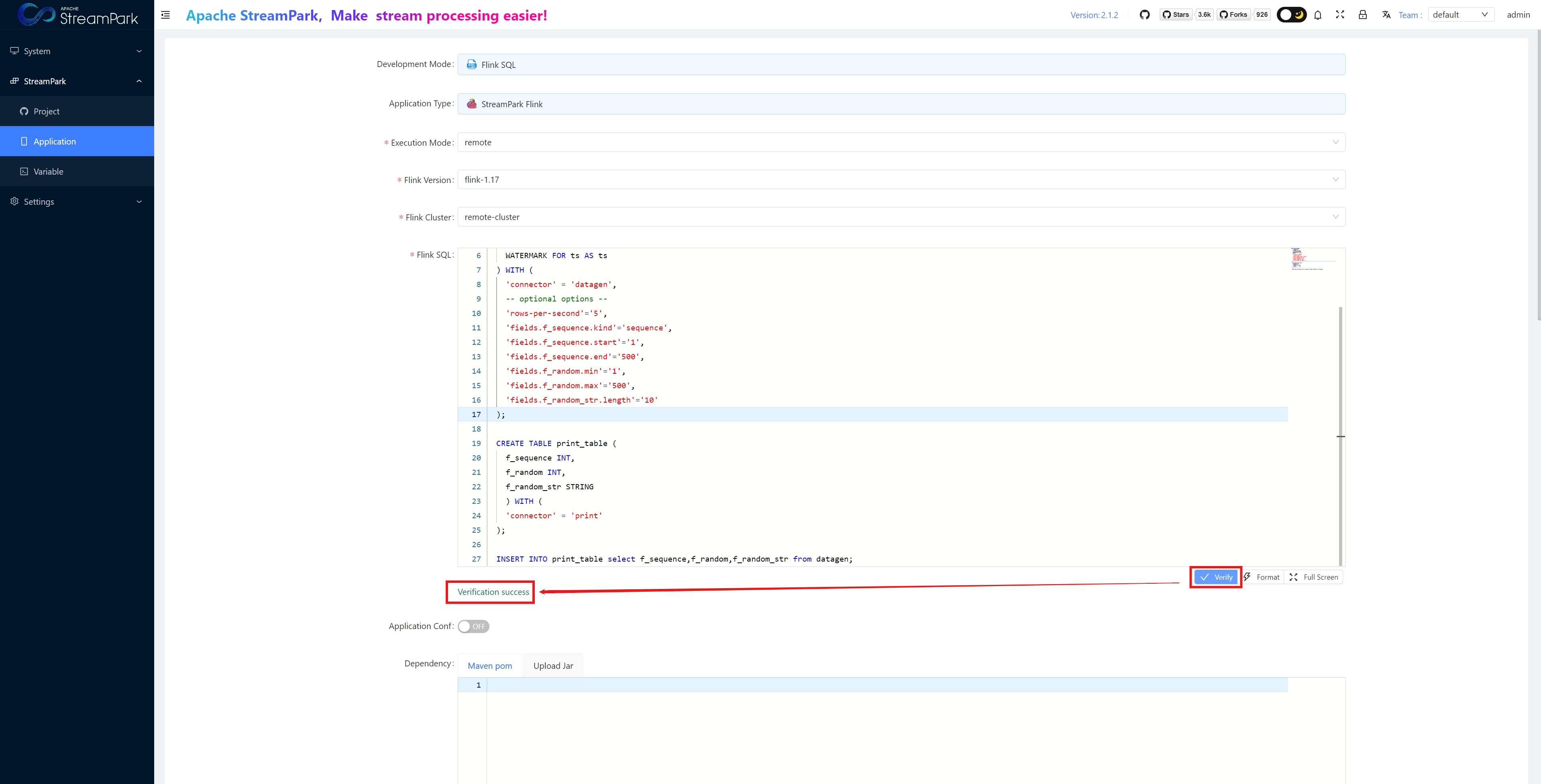
Build Job
Build successful
Start Job
Start Checkpoint Settings
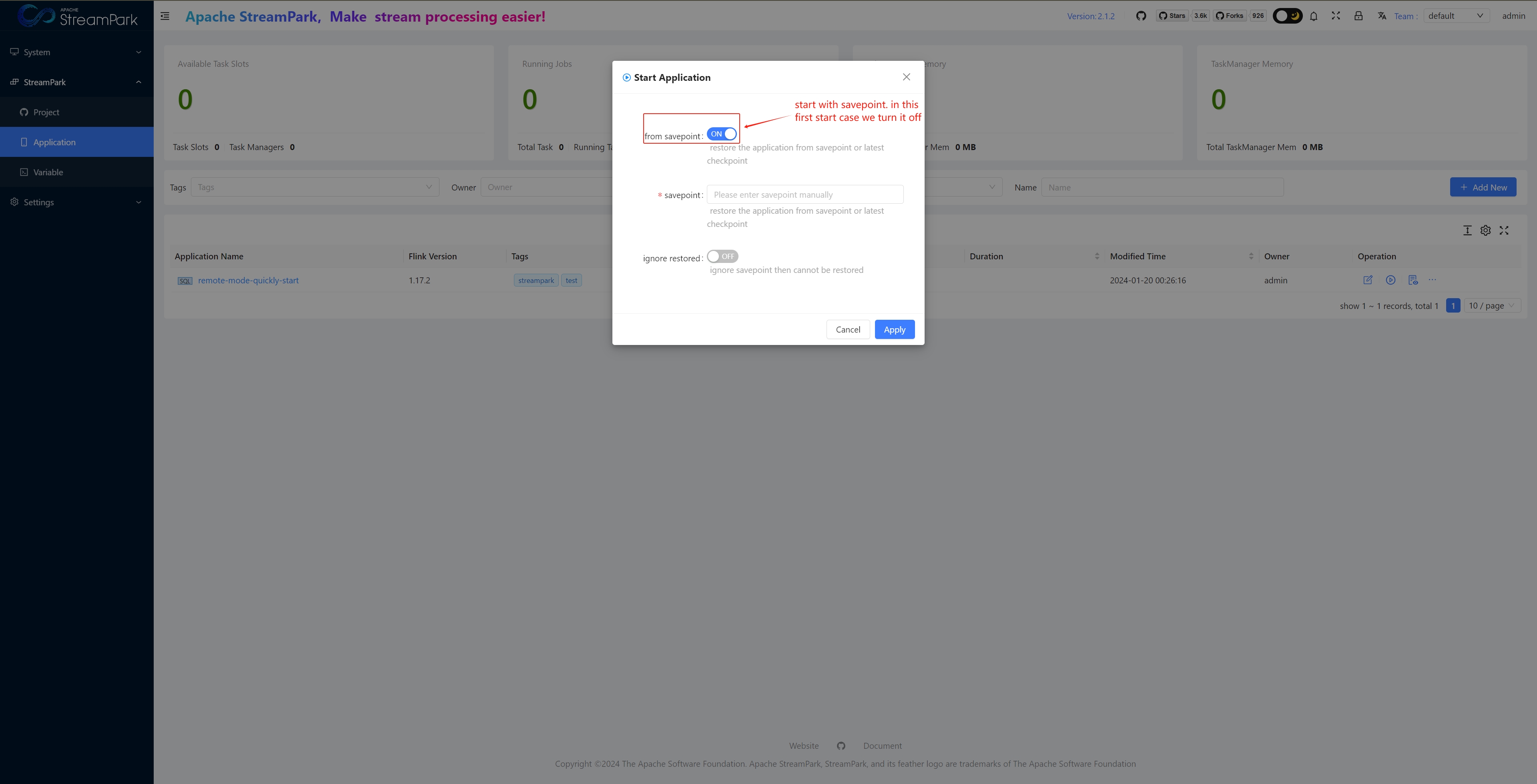
Submit Job
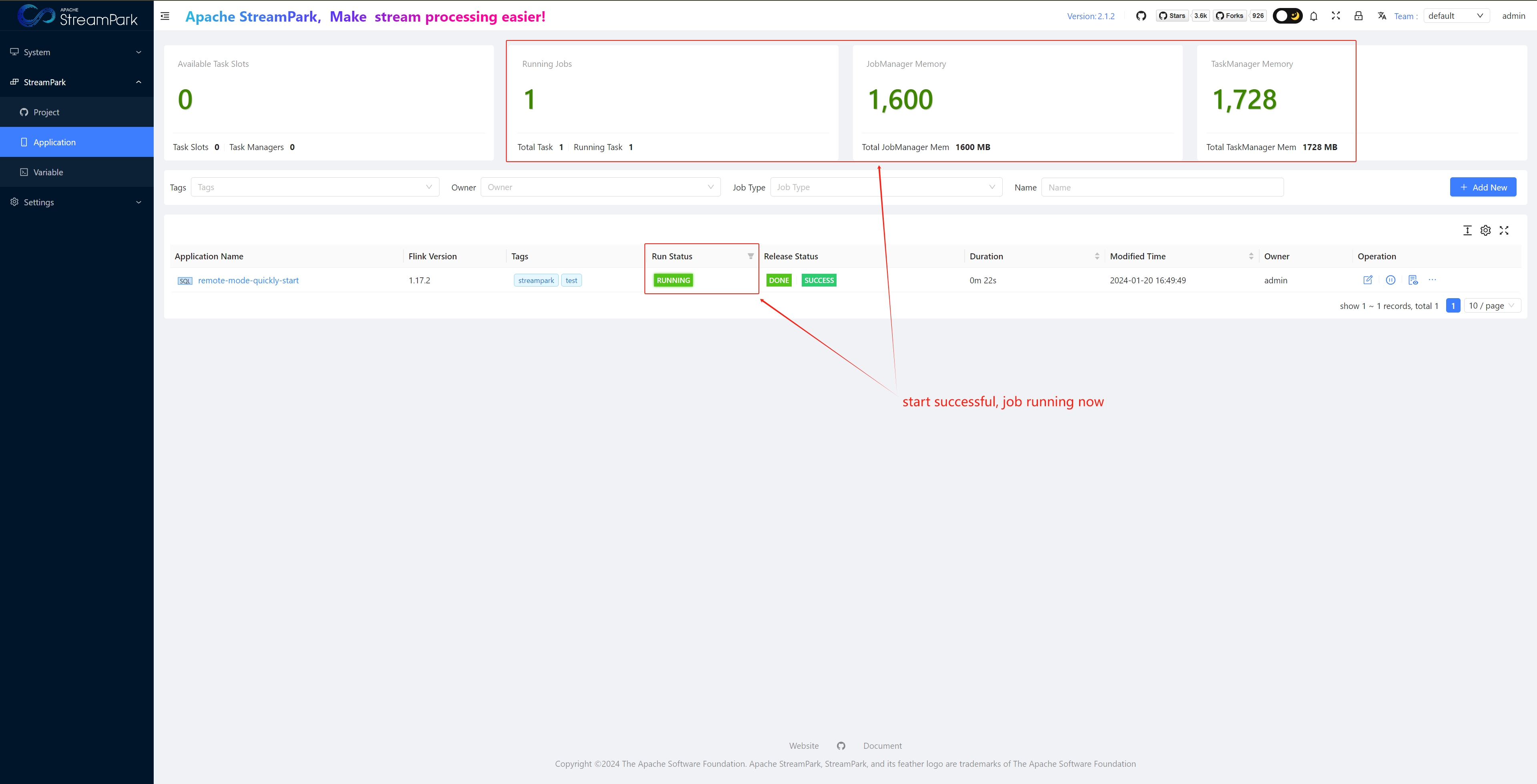
Check Job Status
View via Apache StreamPark™ Dashboard
StreamPark dashboard
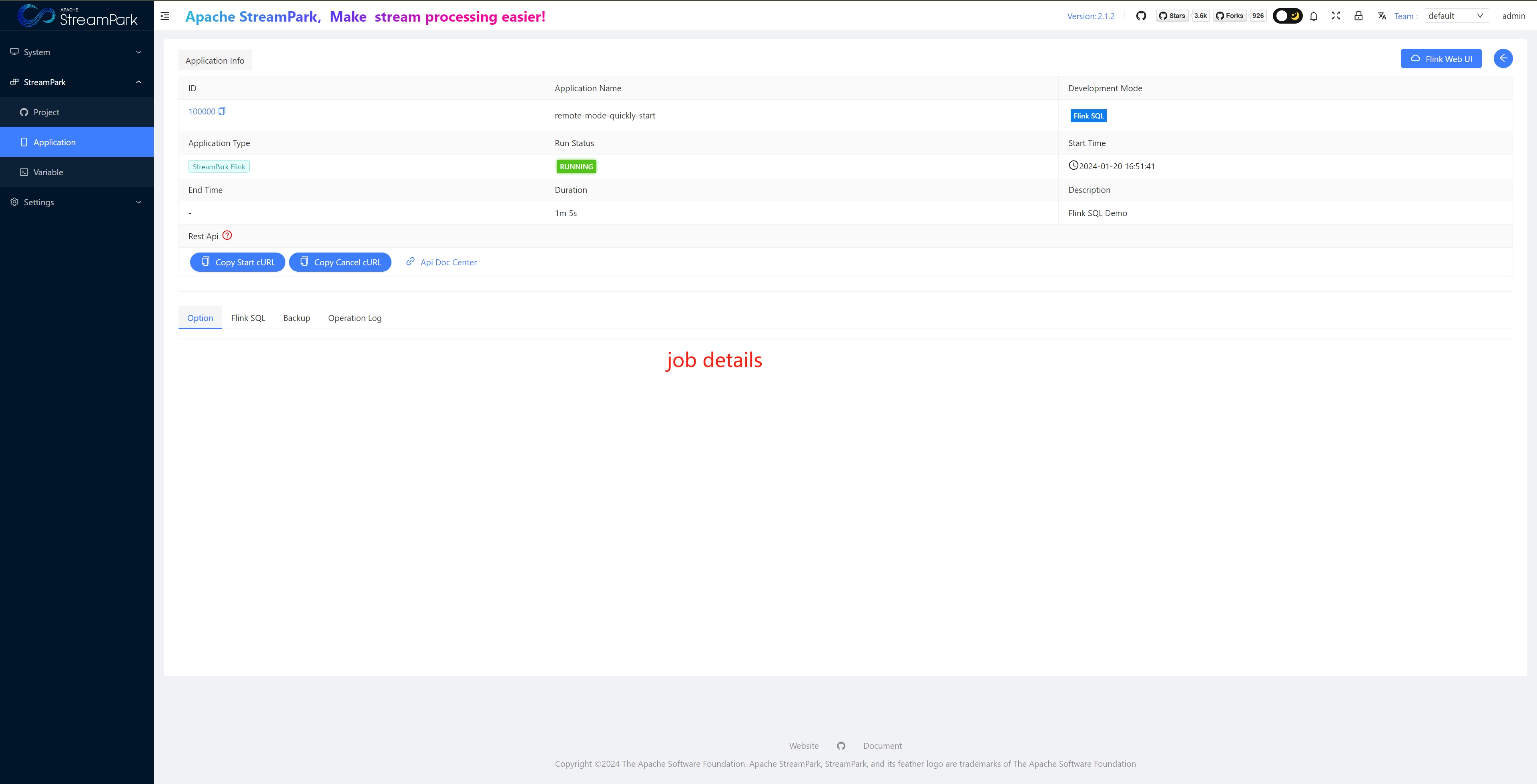
View job details
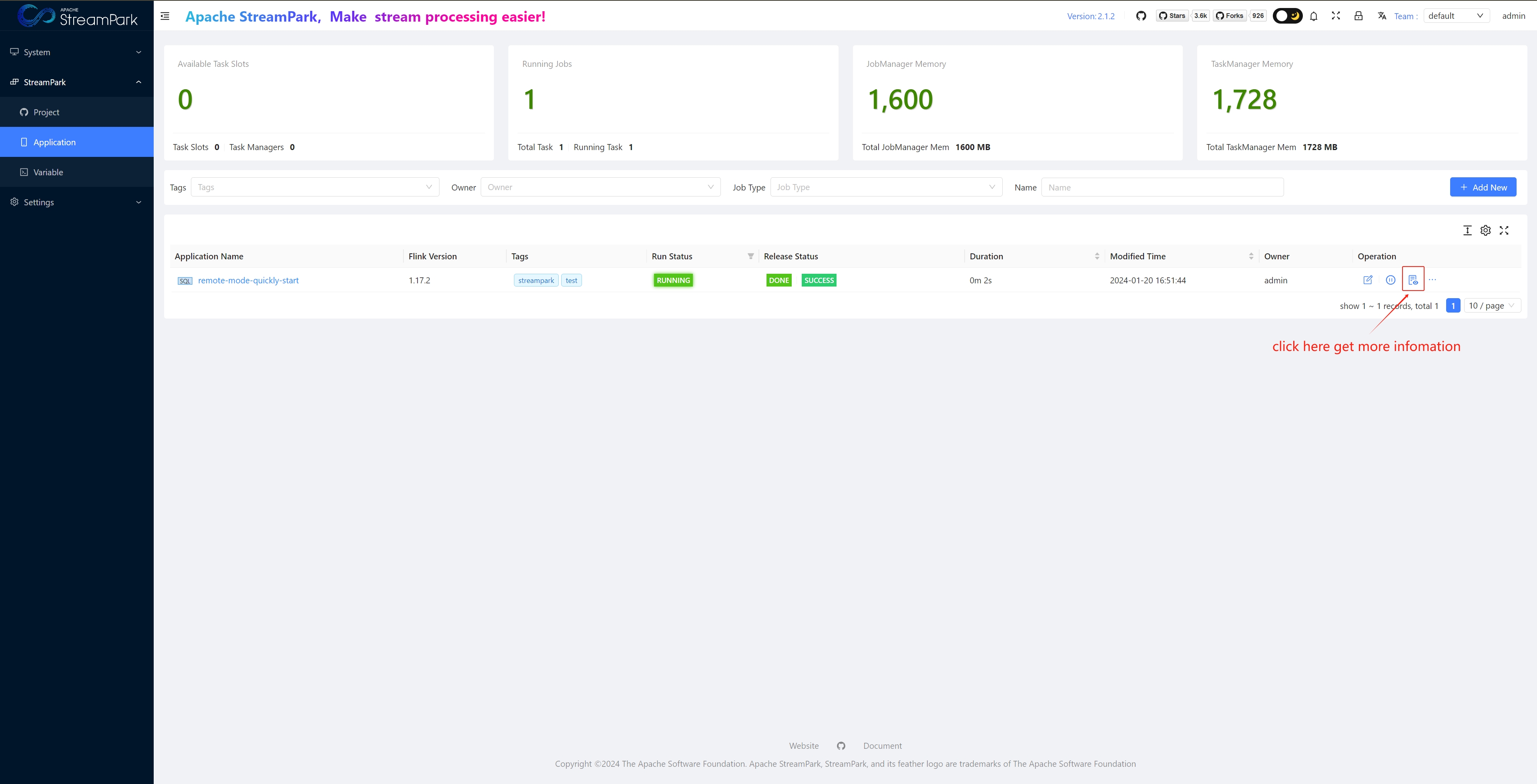
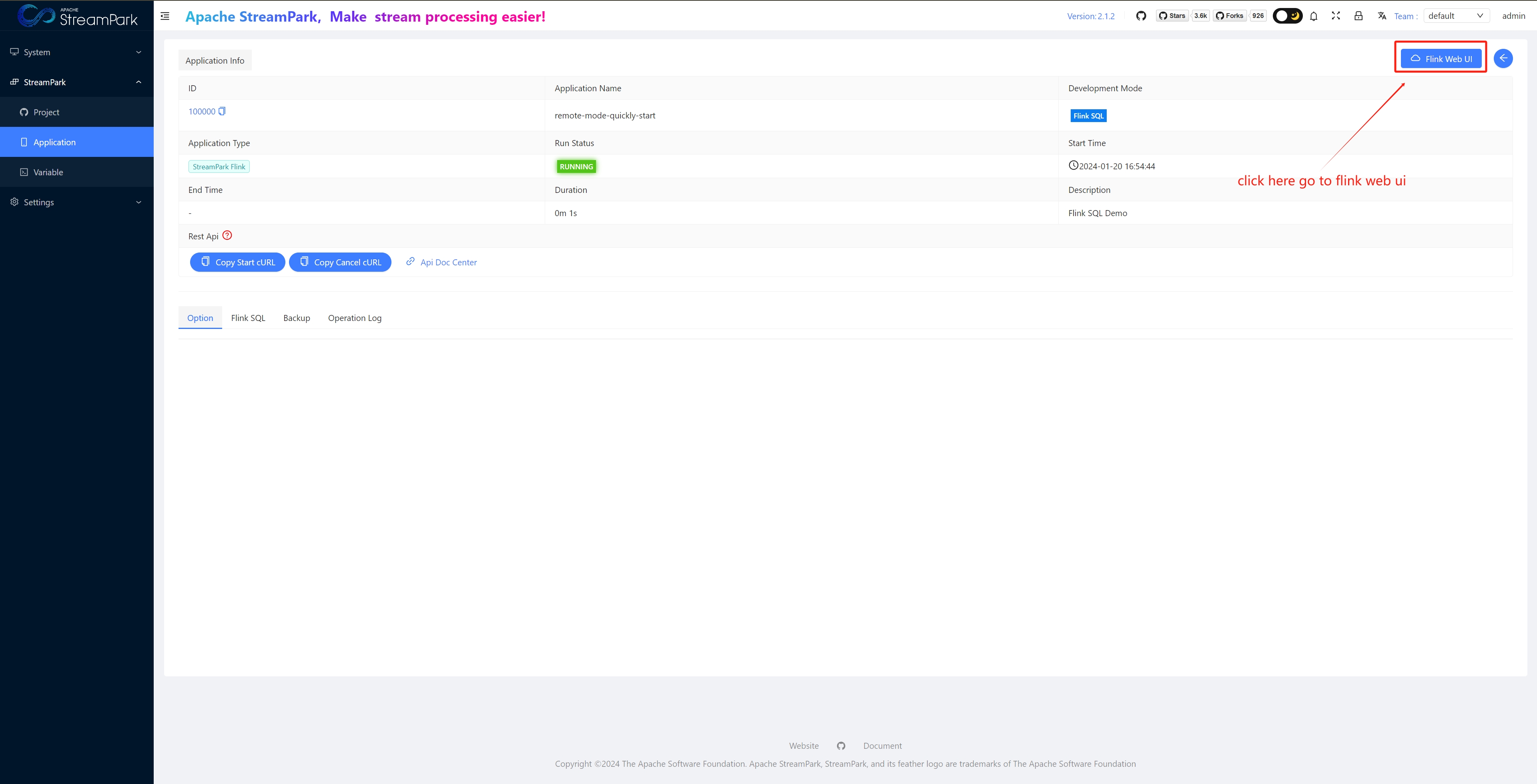
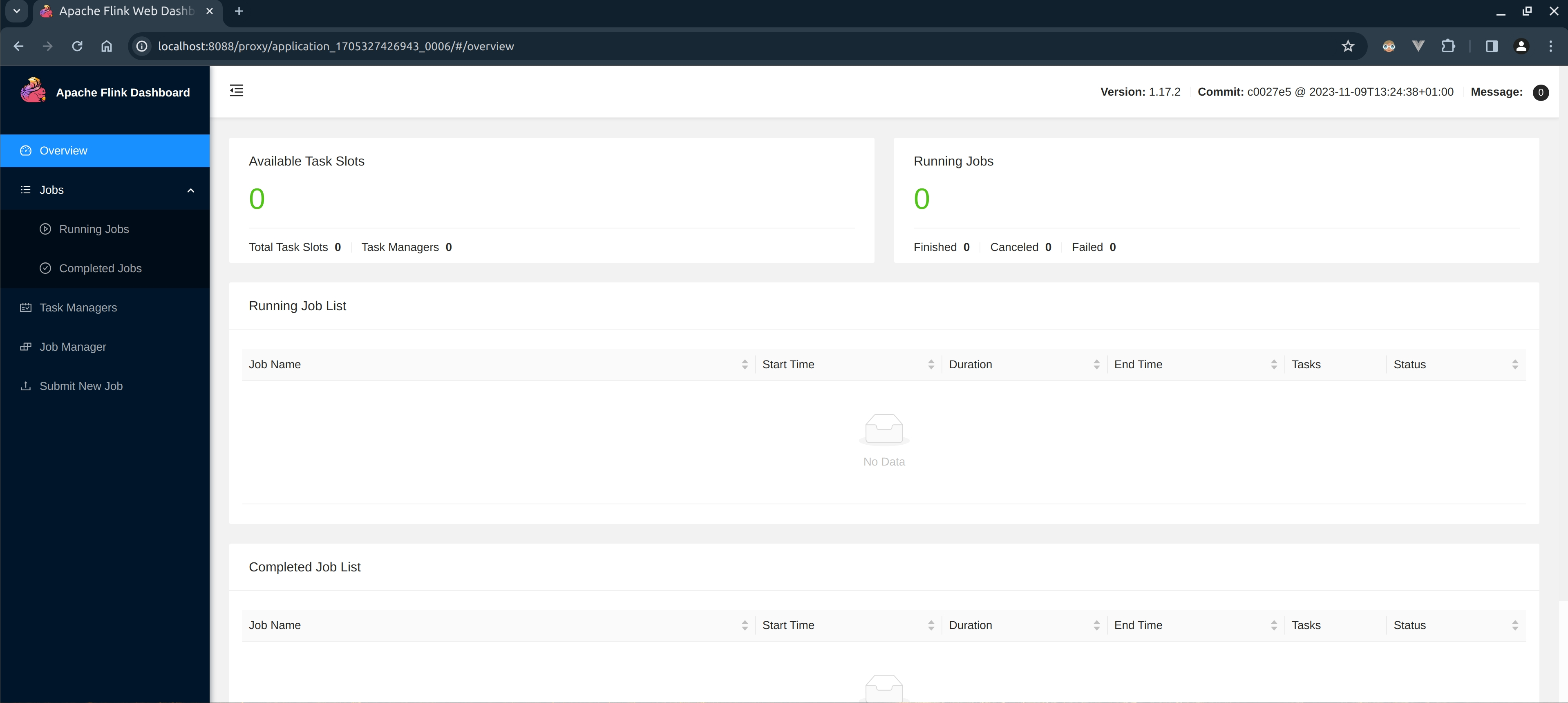
View Native Flink Web UI

With this, the process of submitting a Flink job using the StreamPark platform is essentially complete. Below is a brief summary of the general process for managing Flink jobs on the StreamPark platform.
Apache StreamPark™ Platform's Process for Managing Flink Jobs

Stopping, modifying, and deleting Flink jobs through the StreamPark platform is relatively simple and can be experienced by users themselves. It is worth noting that: If a job is in a running state, it cannot be deleted and must be stopped first.
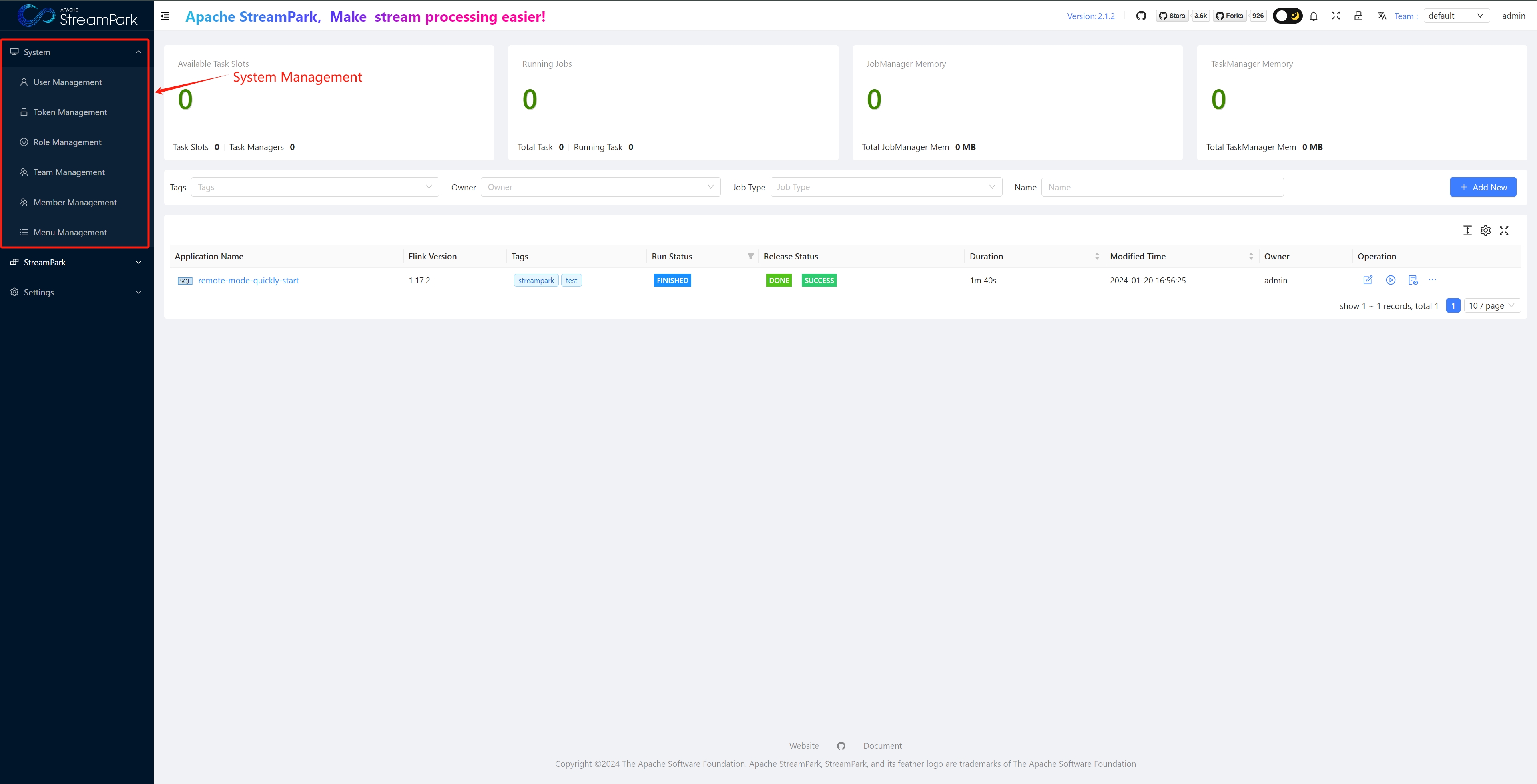
Apache StreamPark™ System Module Introduction
System Settings
Menu location
User Management
For managing users of the StreamPark platform
Token Management
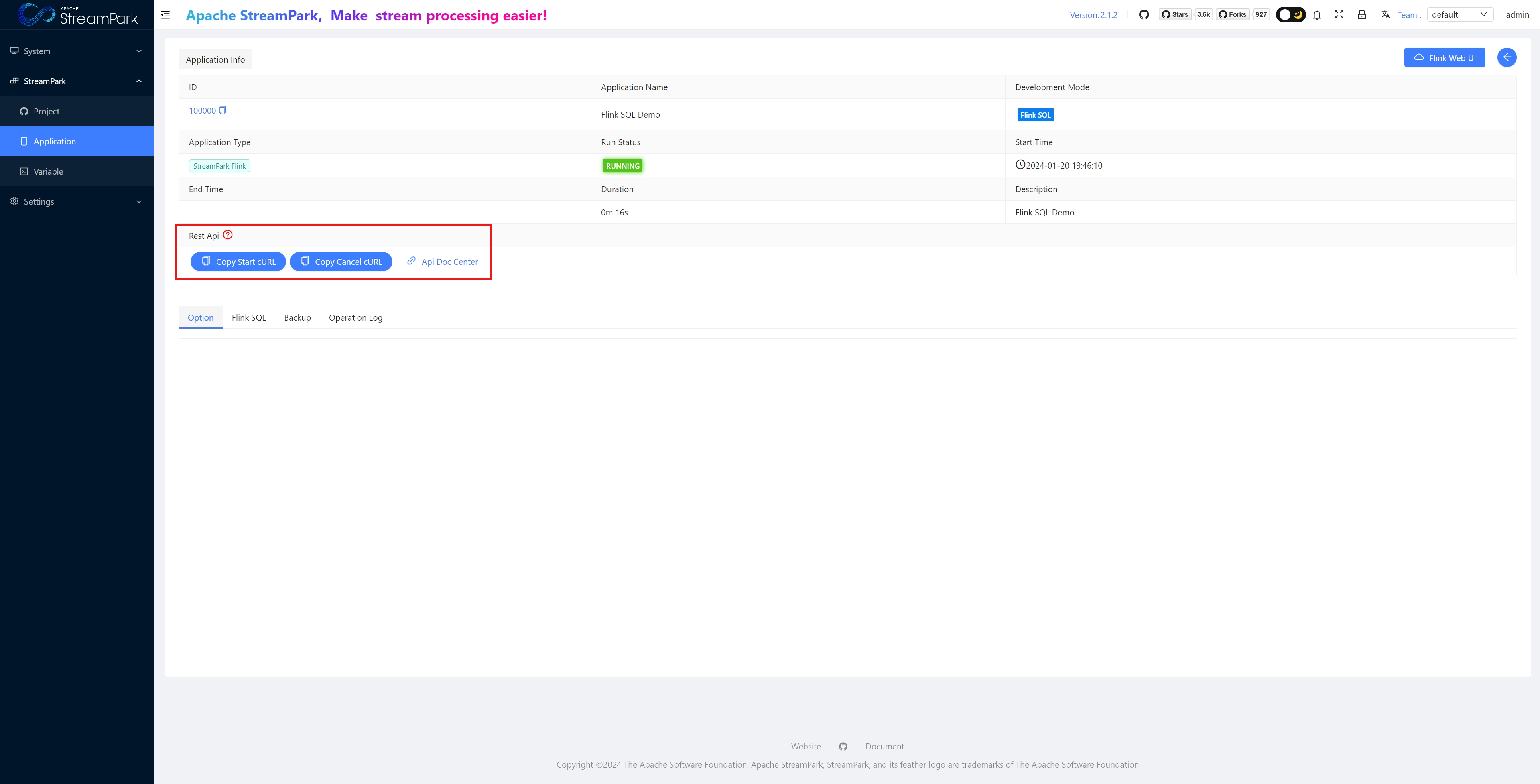
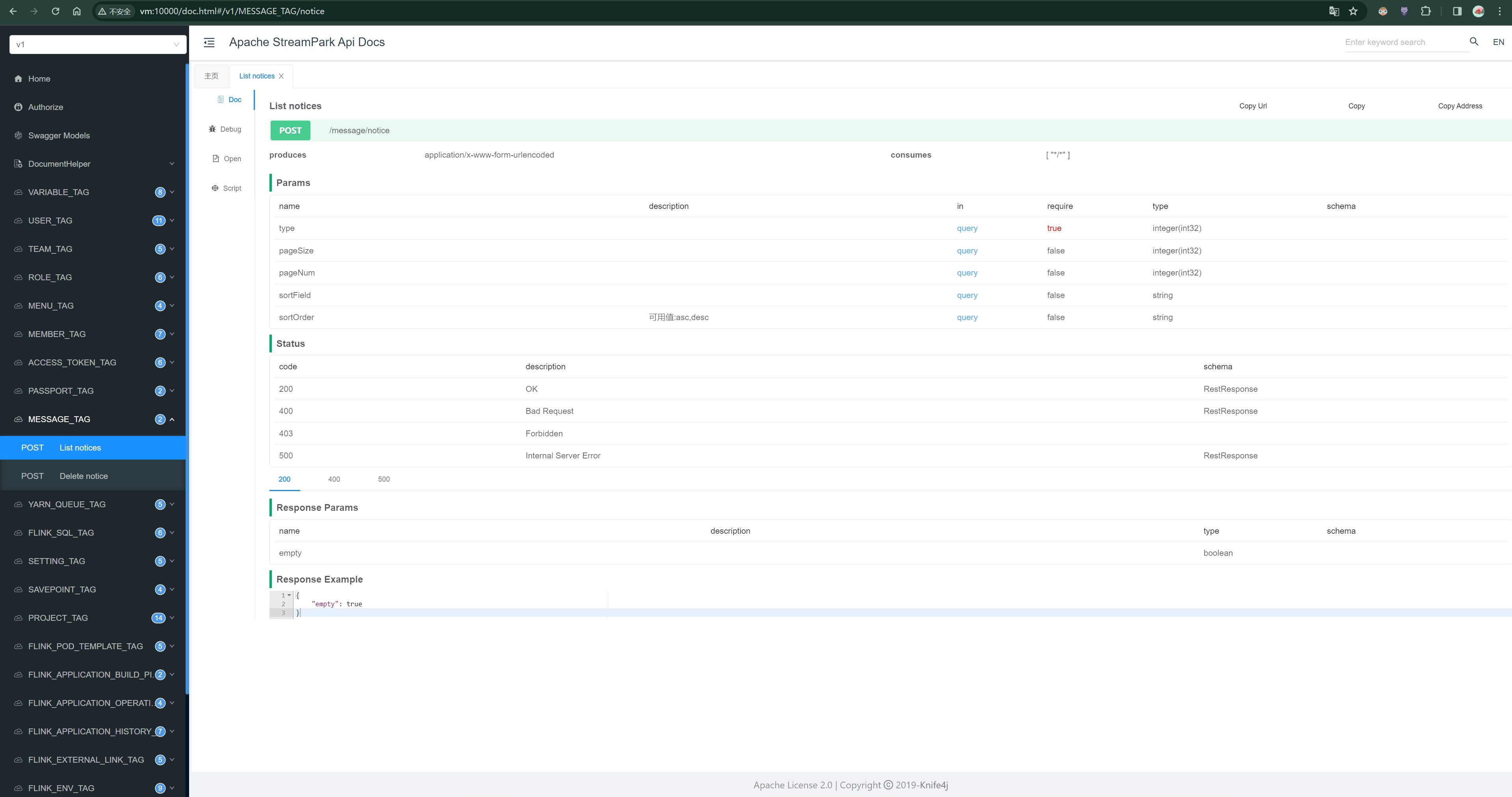
Allows users to operate Flink jobs in the form of Restful APIs
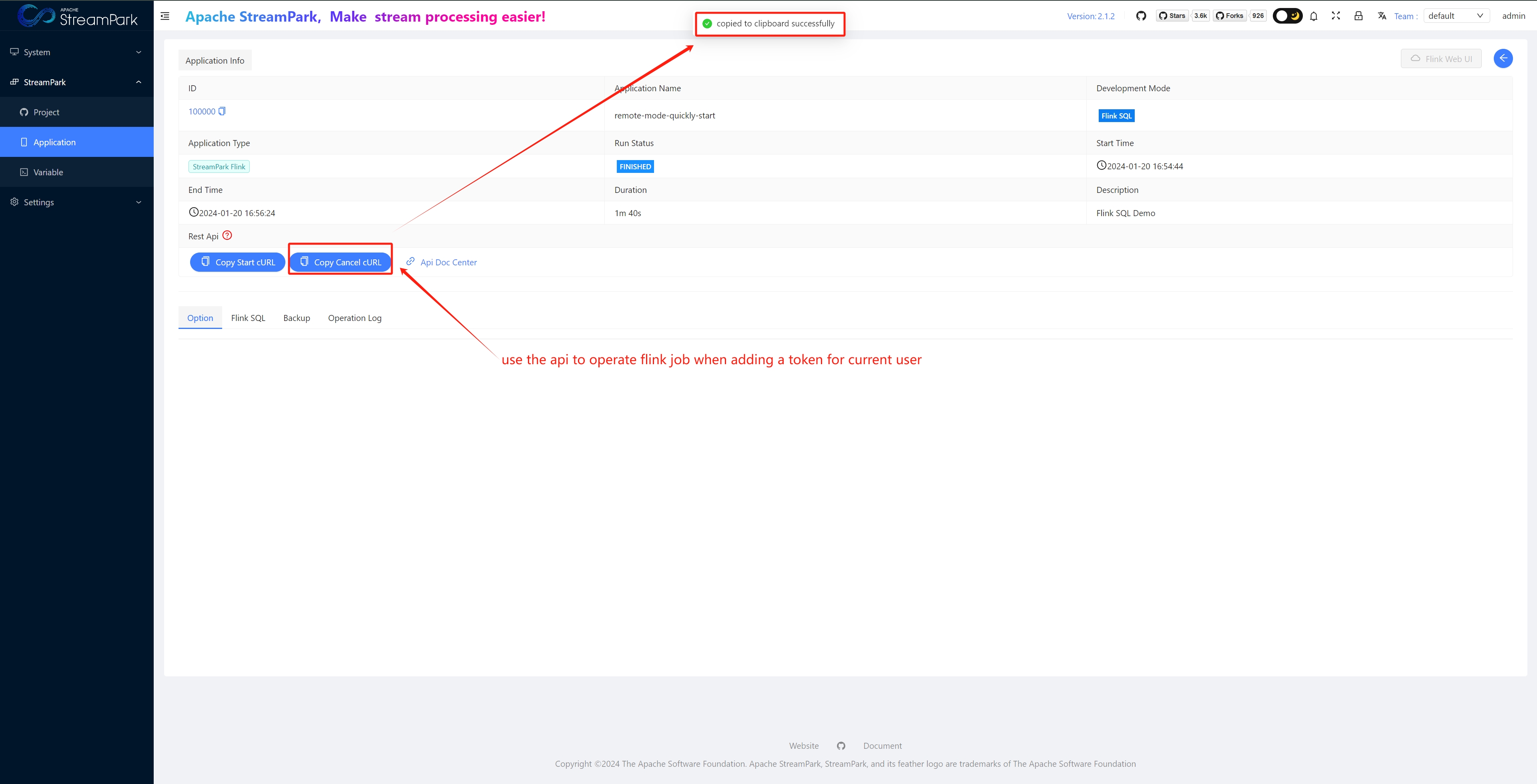
curl -X POST '/flink/app/cancel' \
-H 'Authorization: 69qMW7reOXhrAh29LjPWwwP+quFqLf++MbPbsB9/NcTCKGzZE2EU7tBUBU5gqG236VF5pMyVrsE5K7hBWiyuLuJRqmxKdPct4lbGrjZZqkv5lBBYExxYVMIl+f5MZ9dbqqslZifFx3P4A//NYgGwkx5PpizomwkE+oZOqg0+c2apU0UZ9T7Dpnu/tPLk9g5w9q+6ZS2p+rTllPiEgyBnSw==' \
-H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \
--data-urlencode 'savePoint=' \
--data-urlencode 'id=100001' \
--data-urlencode 'savePointed=false' \
--data-urlencode 'drain=false' \
-i
Role Management
User roles: Currently, there are two types, develop and admin.
Team Management
Teams: Used to distinguish and manage jobs of different teams in an enterprise.
Member Management
(Team) member management
Menu Management
Managing system menus
Apache StreamPark™ Menu Modules
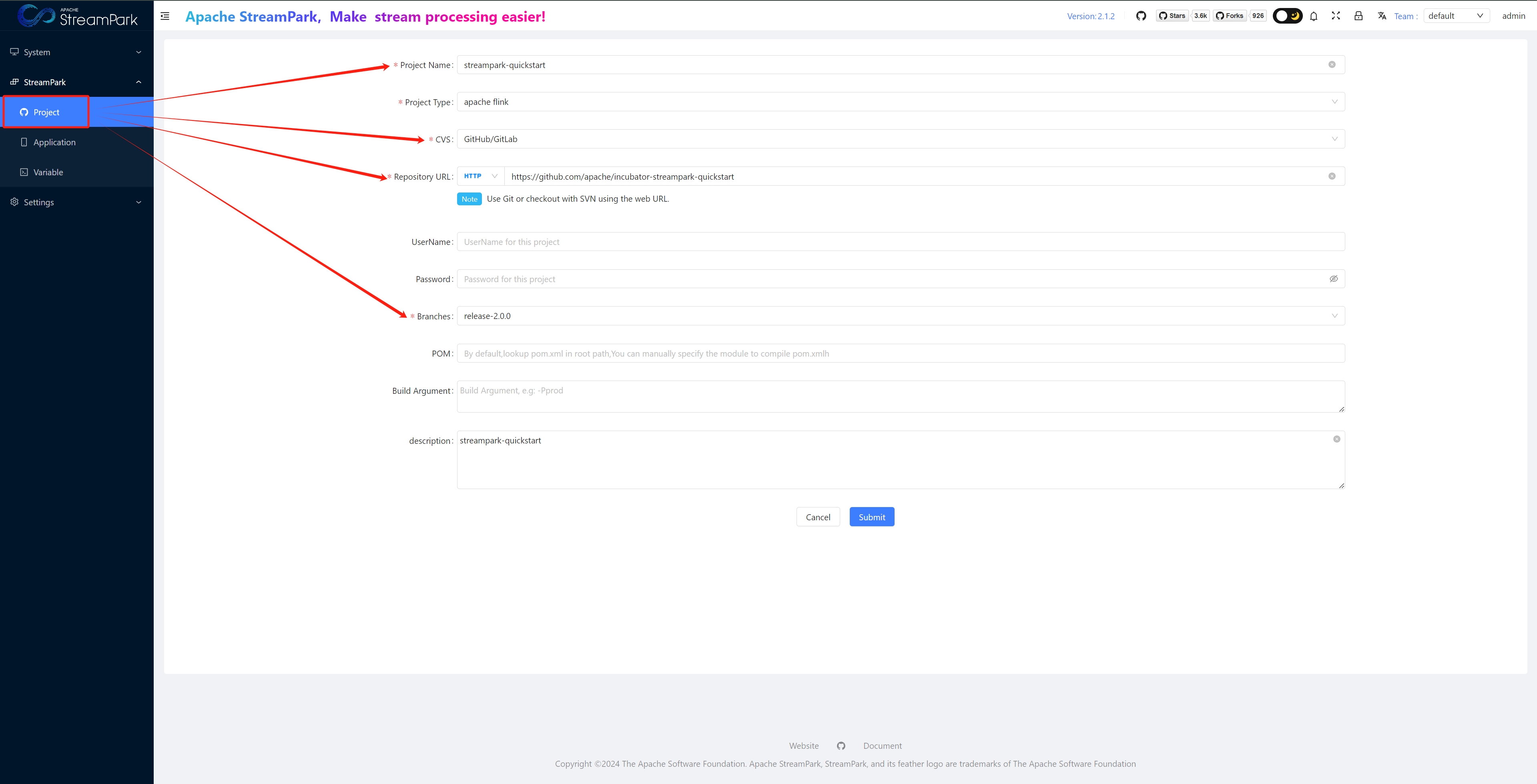
Project
StreamPark integrates with code repositories to achieve CICD
To use, click "+ Add new," configure repo information, and save.
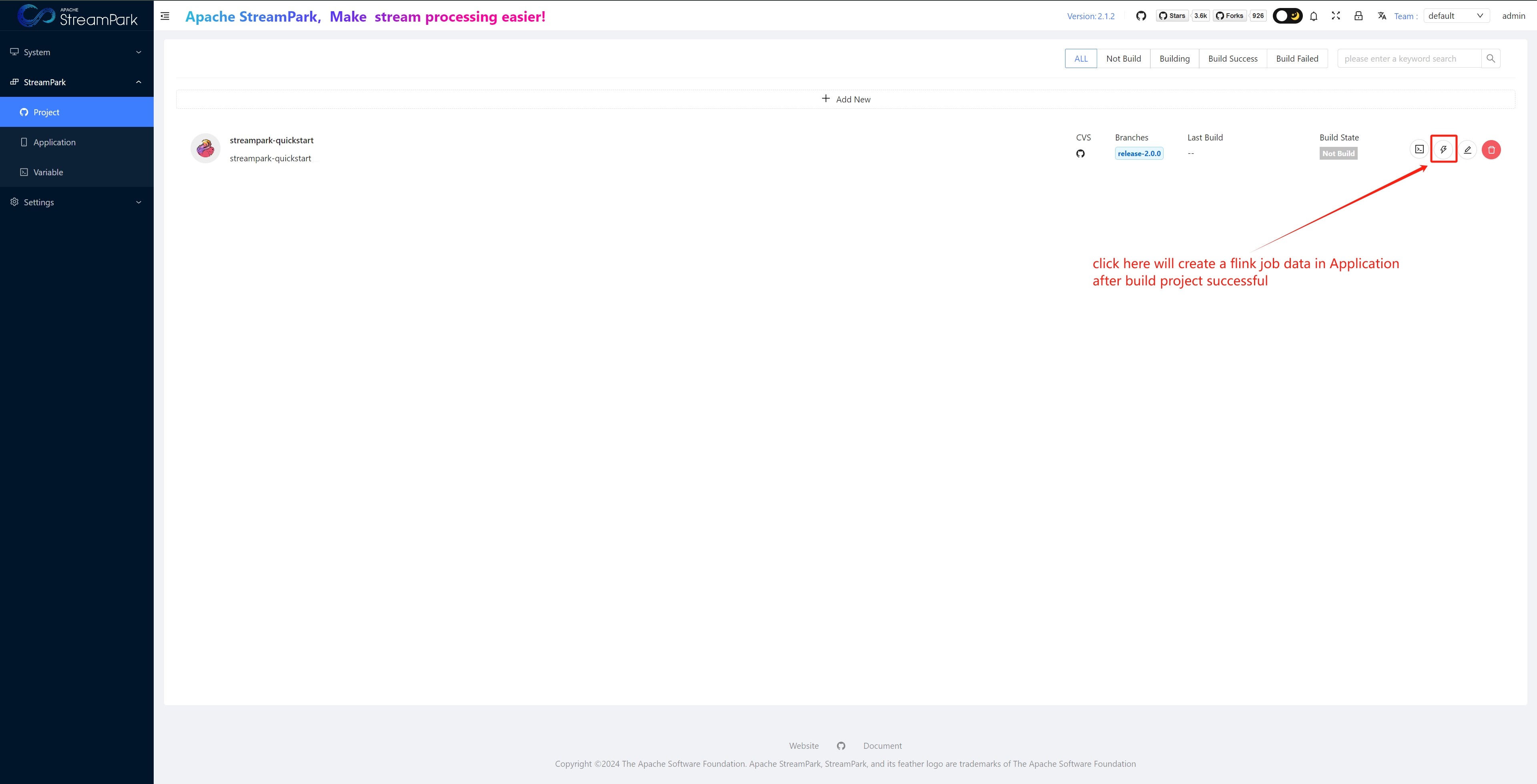
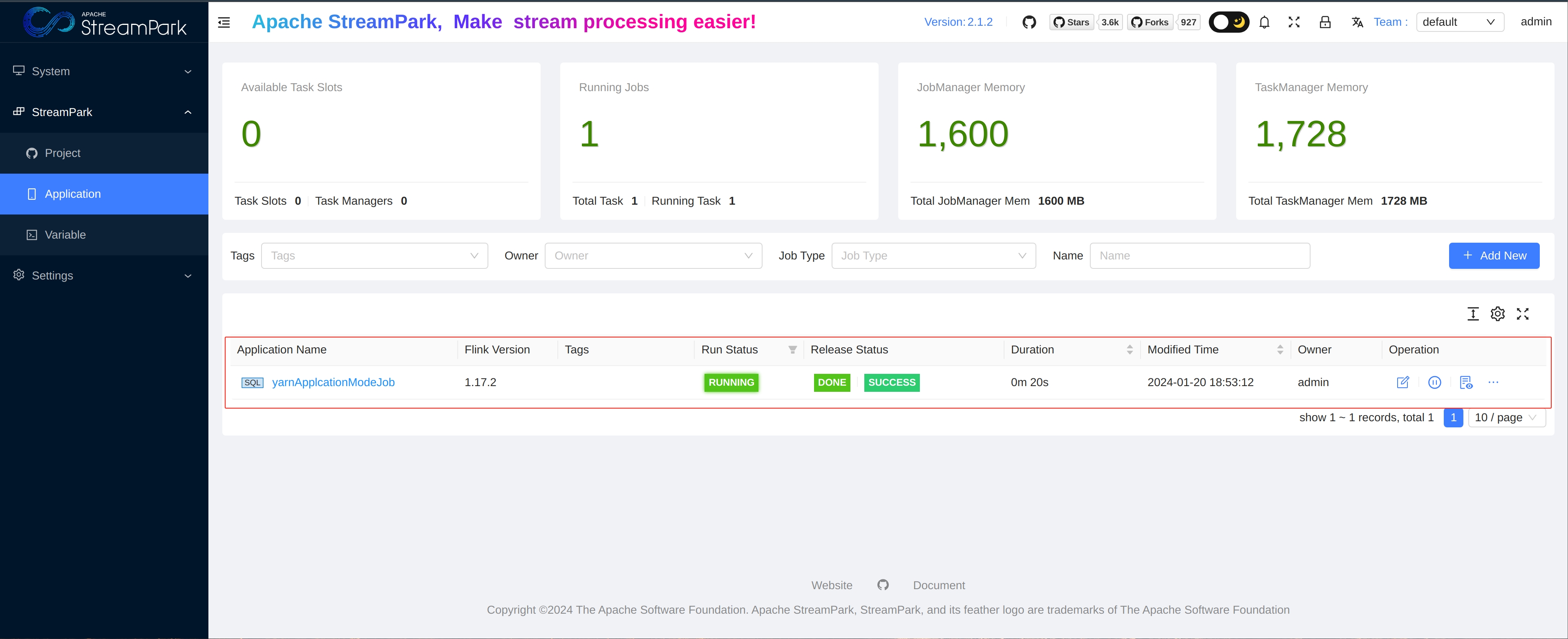
Application
Core Module: Used for full lifecycle management (creation, build, start, stop, delete, etc.) of Flink jobs.
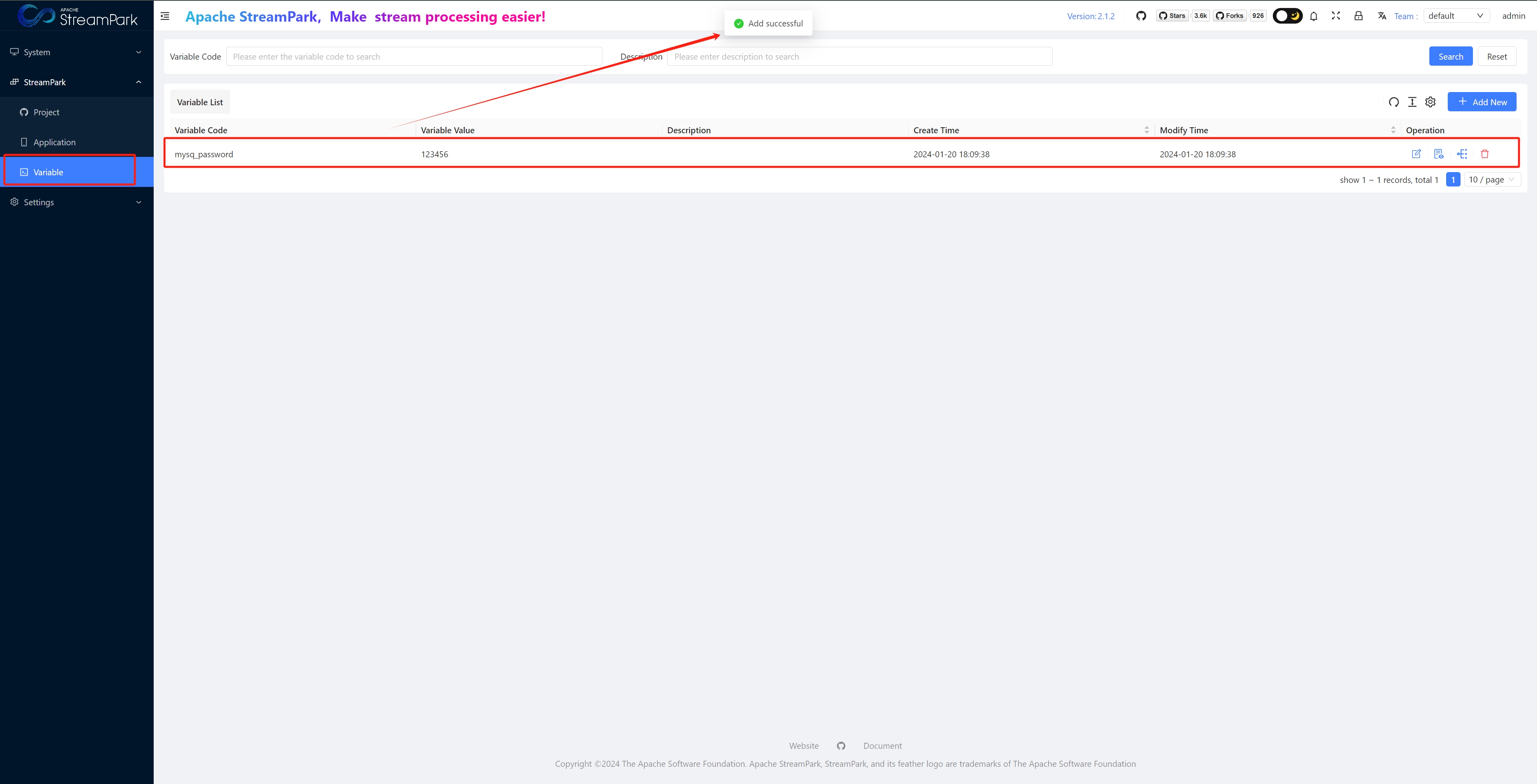
Variable
Variable management: Manage variables that can be used when creating Application jobs.
Setting
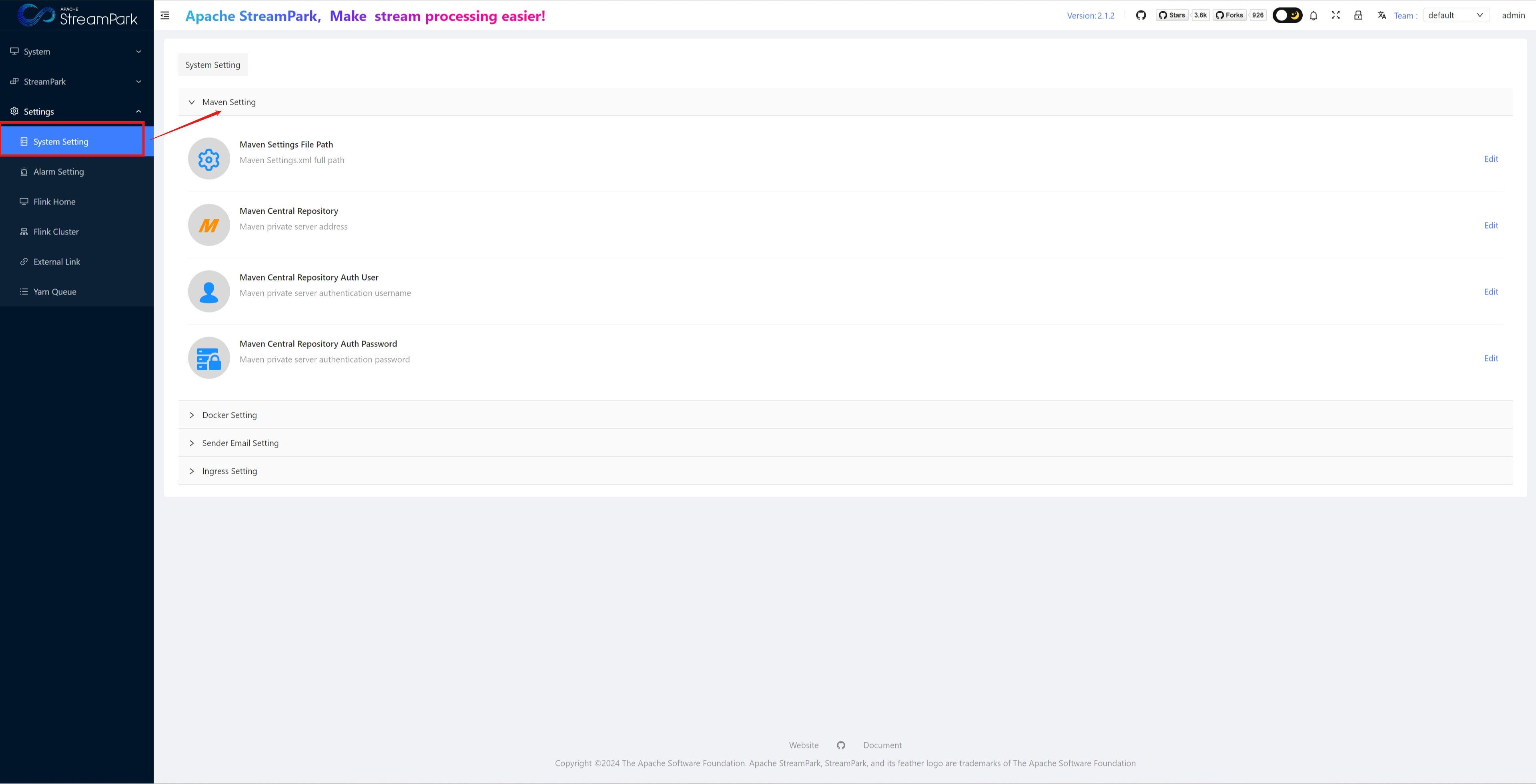
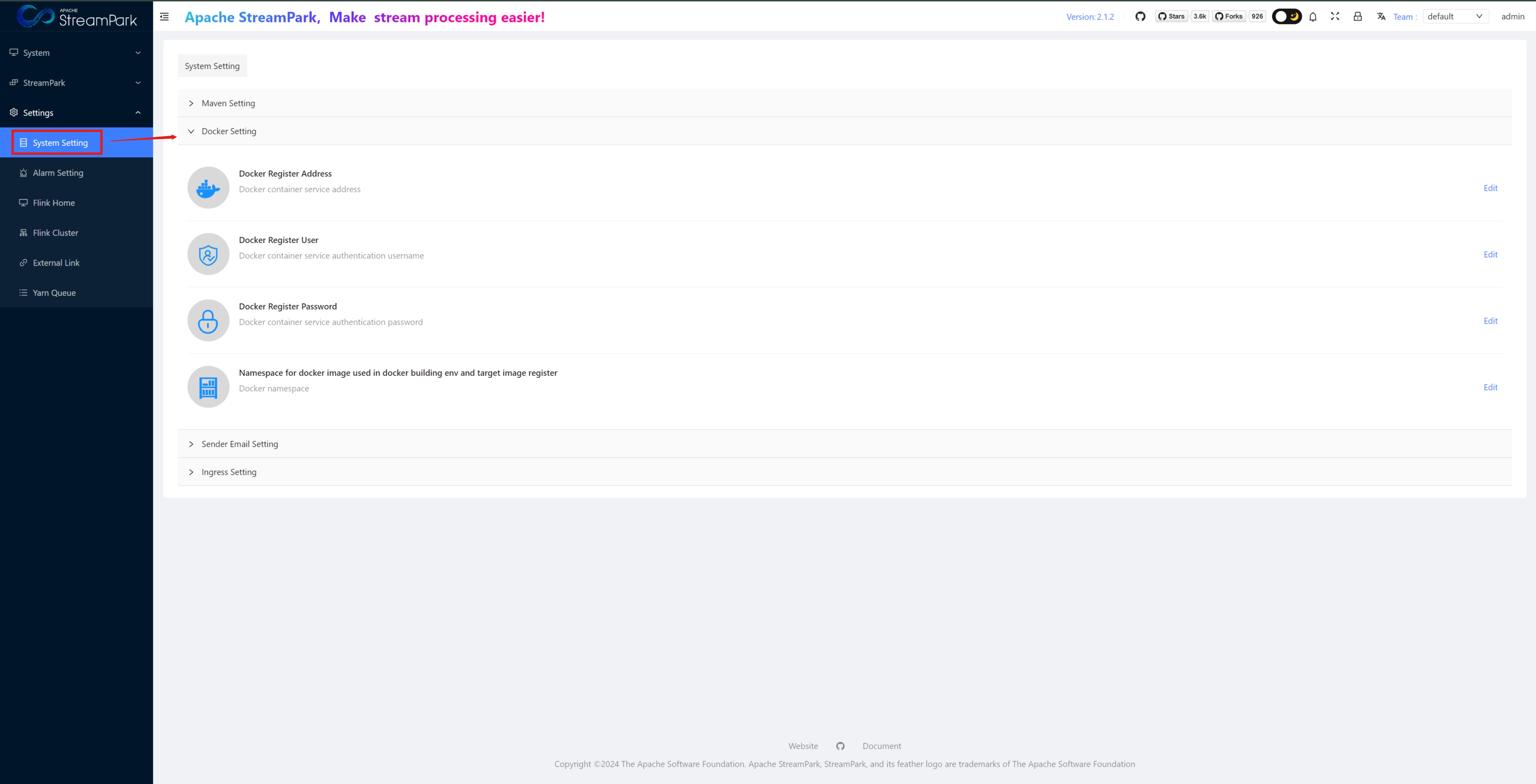
System Setting
For system configurations: Maven, Docker, alert email, Ingress
Alert Setting
Supports multiple alert notification modes
Flink Home
【To be improved】Can perform some operations on Flink jobs, such as validation of Flink SQL, etc.
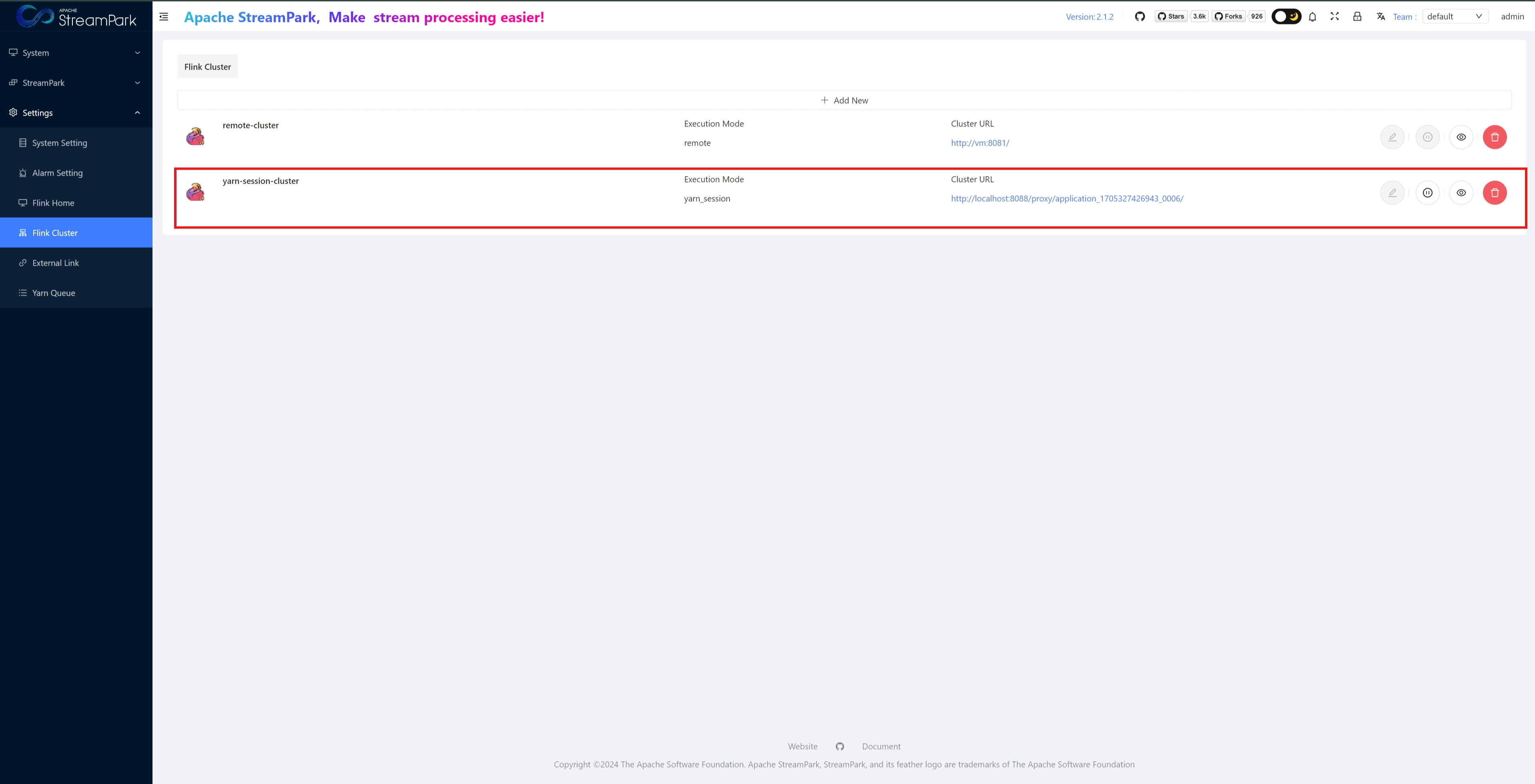
Flink Cluster
- For executing Flink jobs in Session mode, there are three types based on different resource management methods: Standalone, Yarn, K8s
- 【To be improved】Application scenario: Suitable for scenarios with sufficient resources and where job isolation requirements are not very strict
- For more on session mode, see: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/overview/#session-mode
Using Native Flink with Apache StreamPark™
【To be improved】In fact, a key feature of StreamPark is the optimization of the management mode for native Flink jobs at the user level, enabling users to rapidly develop, deploy, run, and monitor Flink jobs using the platform. Meaning, if users are familiar with native Flink, they will find StreamPark even more intuitive to use.
Flink Deployment Modes
How to Use in Apache StreamPark™
Session Mode
- Configure Flink Cluster
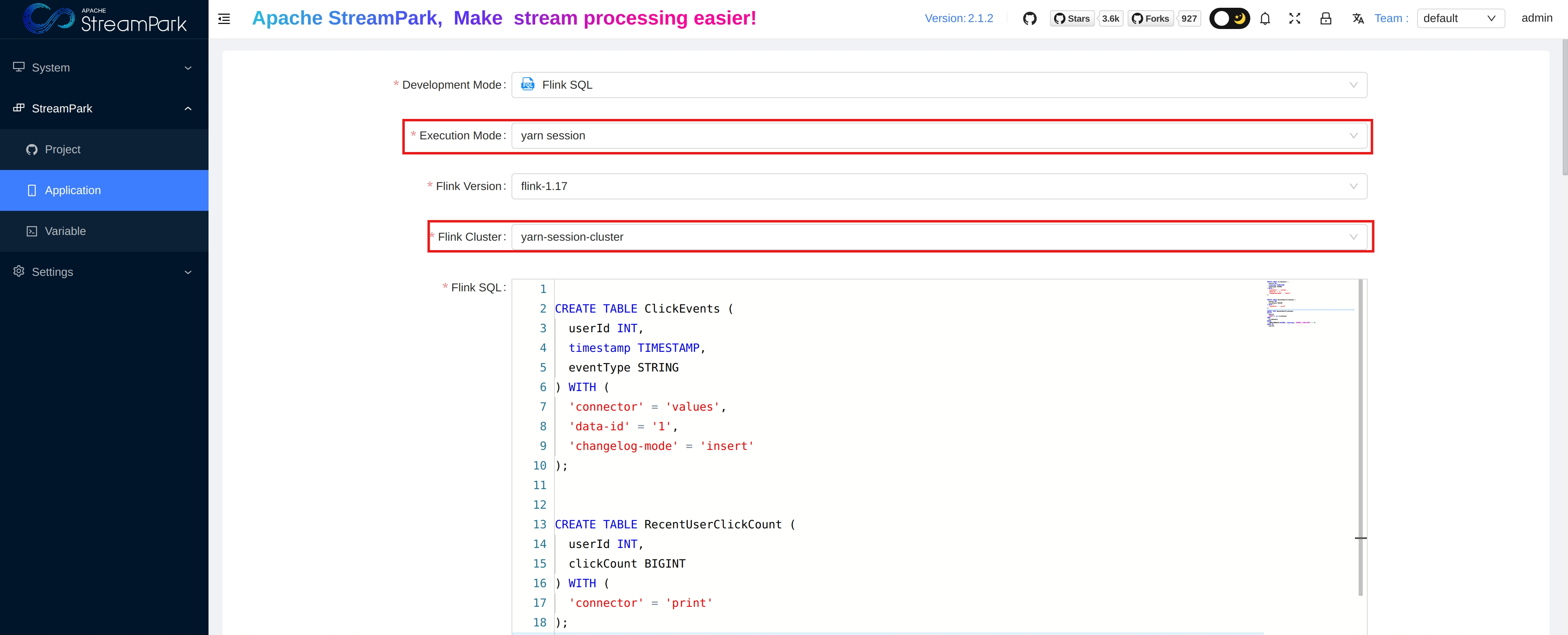
- When creating a job, select the corresponding resource manager's model and an established Flink Cluster in Execution Mode
Application Mode
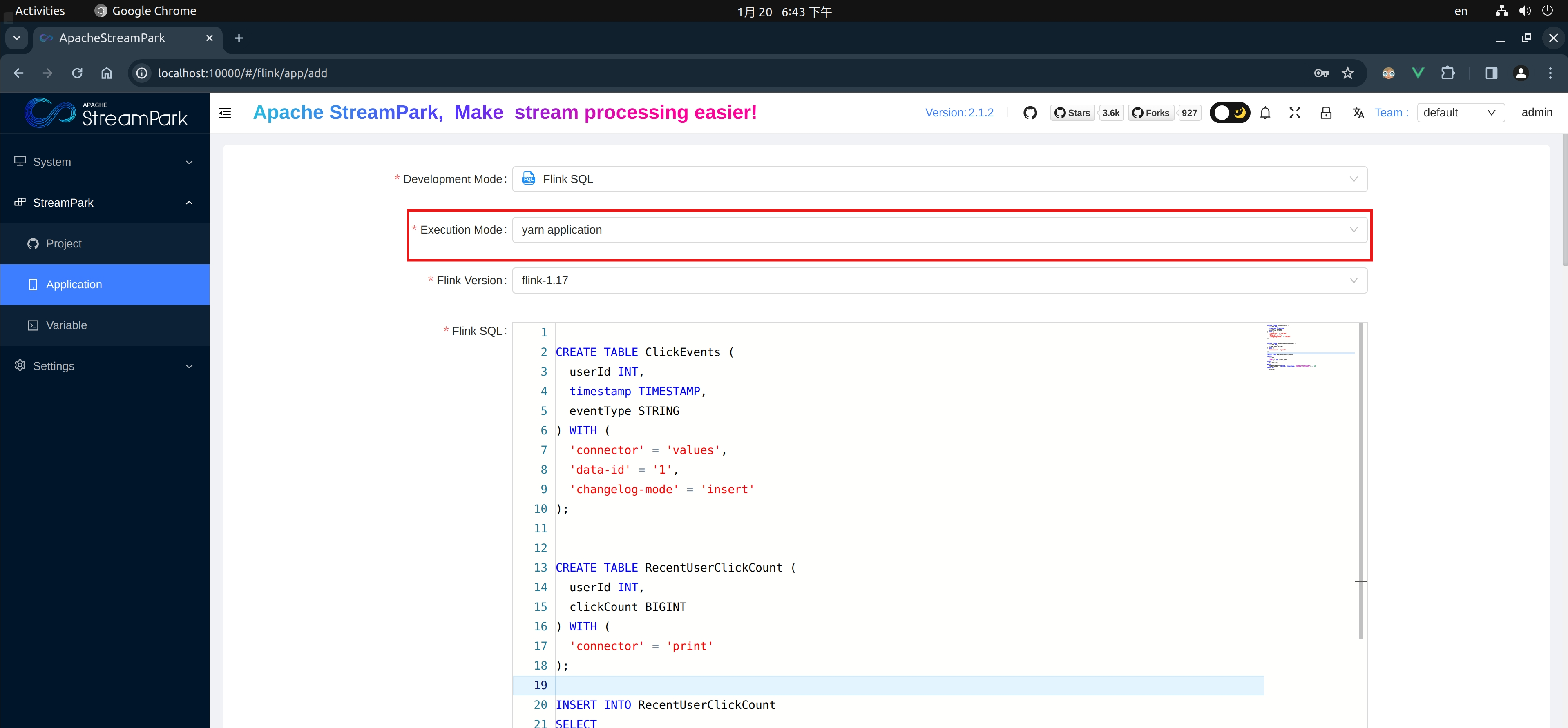
Setting Job Parameters
Native Flink Job Parameters
Official website: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/config/
Native submission command (with parameters)
flink run-application -t yarn-application \
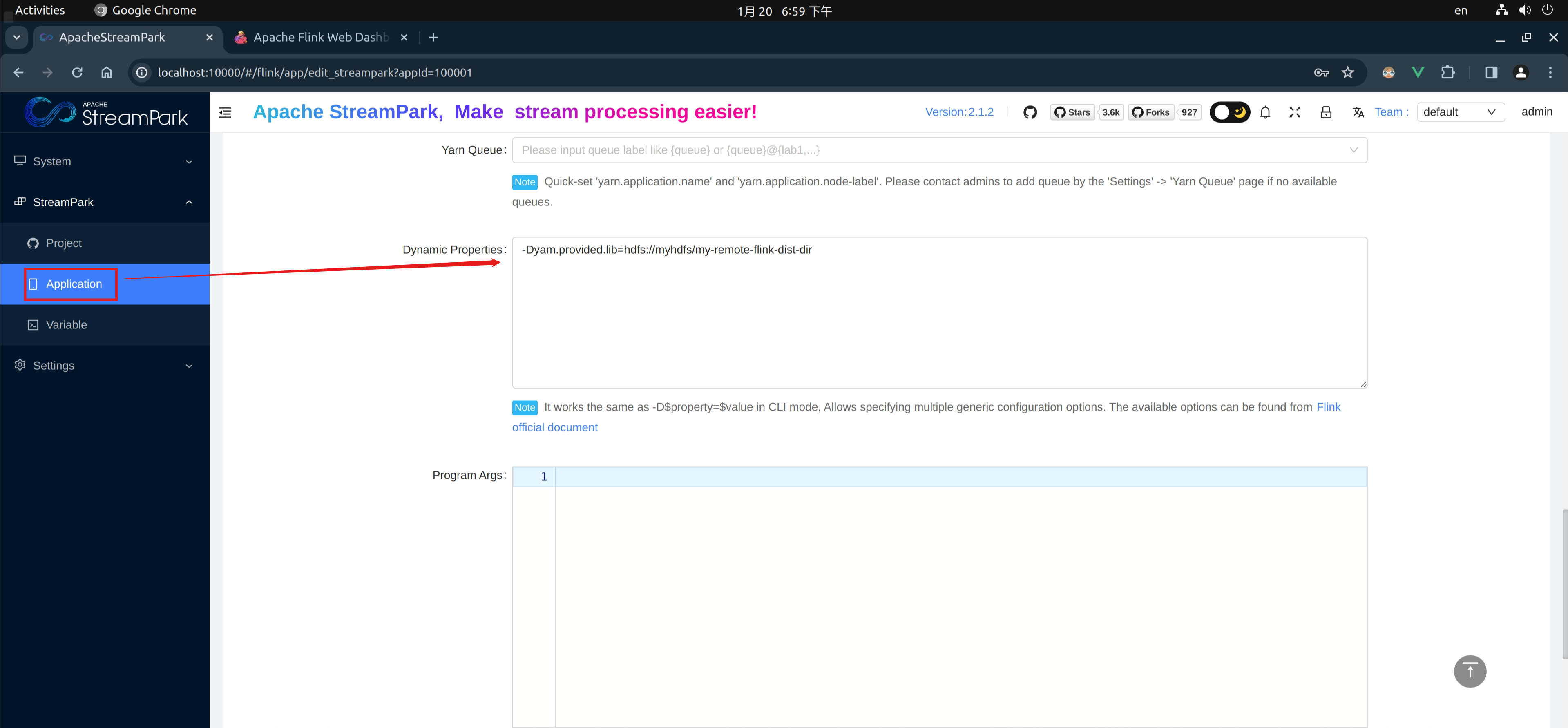
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
hdfs://myhdfs/jars/my-application.jar
How to Use in Apache StreamPark™
When creating or modifying a job, add in “Dynamic Properties” as per the specified format
Alert Strategy
【To be improved】
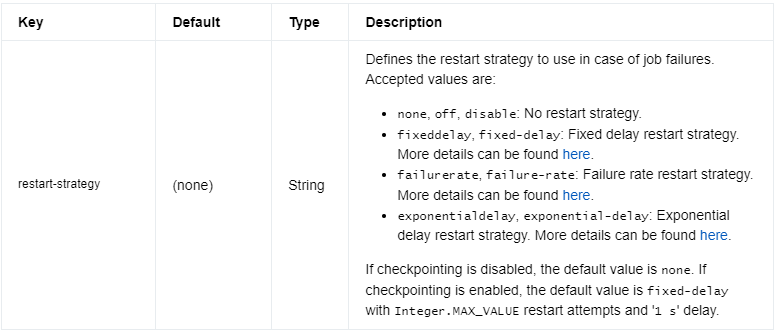
Native Flink Restart Mechanism
Reference: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/ops/state/task_failure_recovery/
How to Use in Apache StreamPark™
【To be improved】Generally, alerts are triggered when a job fails or an anomaly occurs
- Configure alert notifications
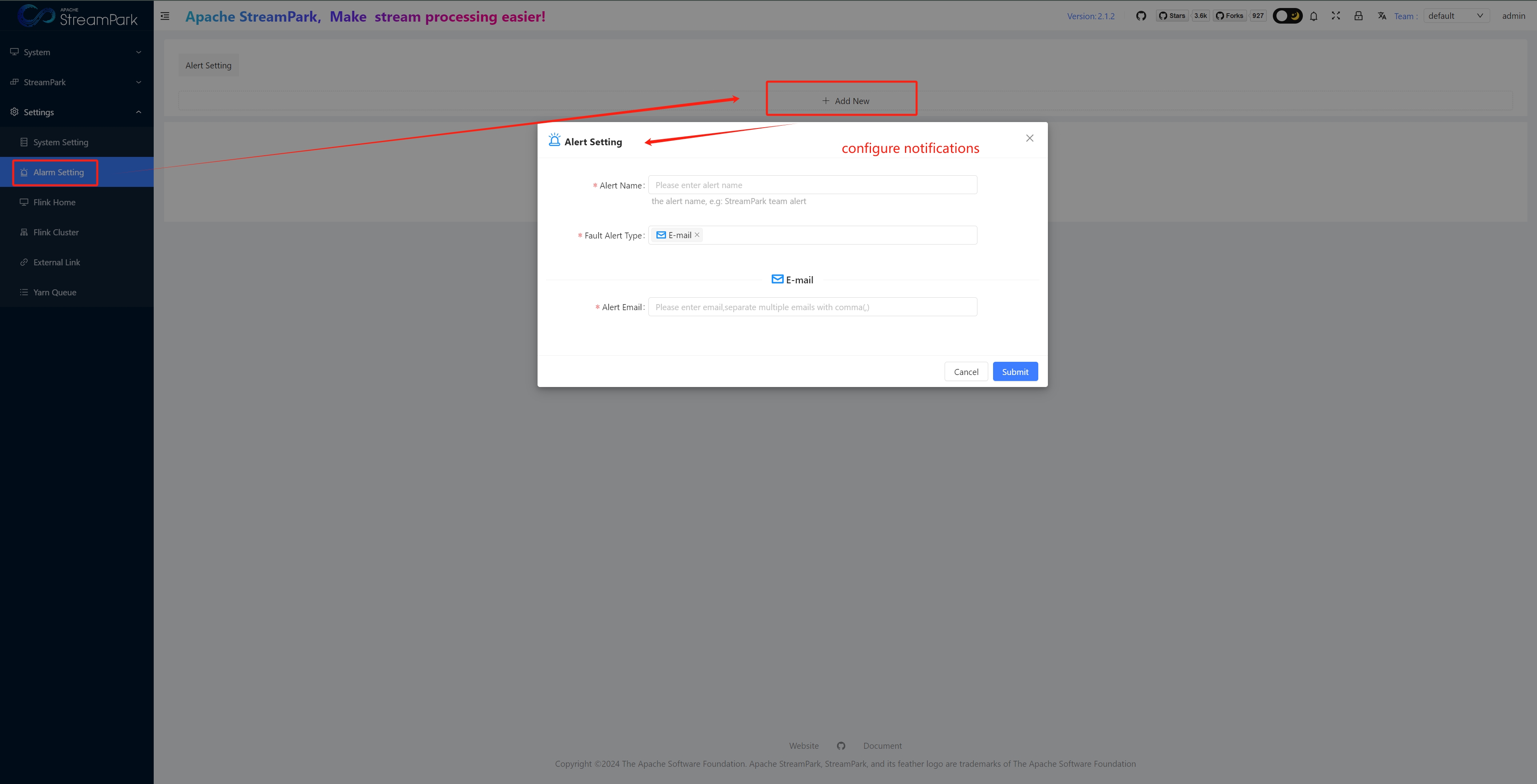
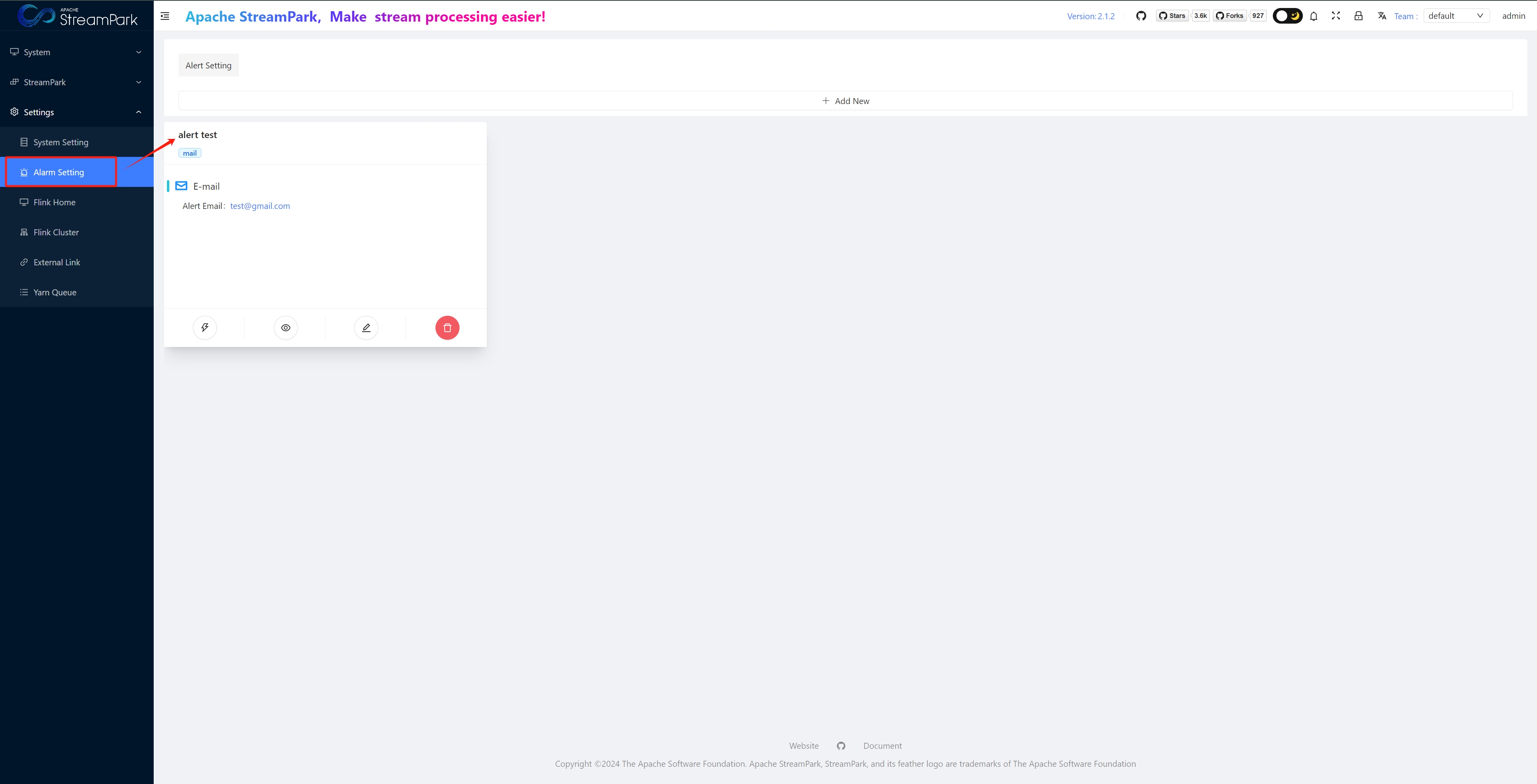
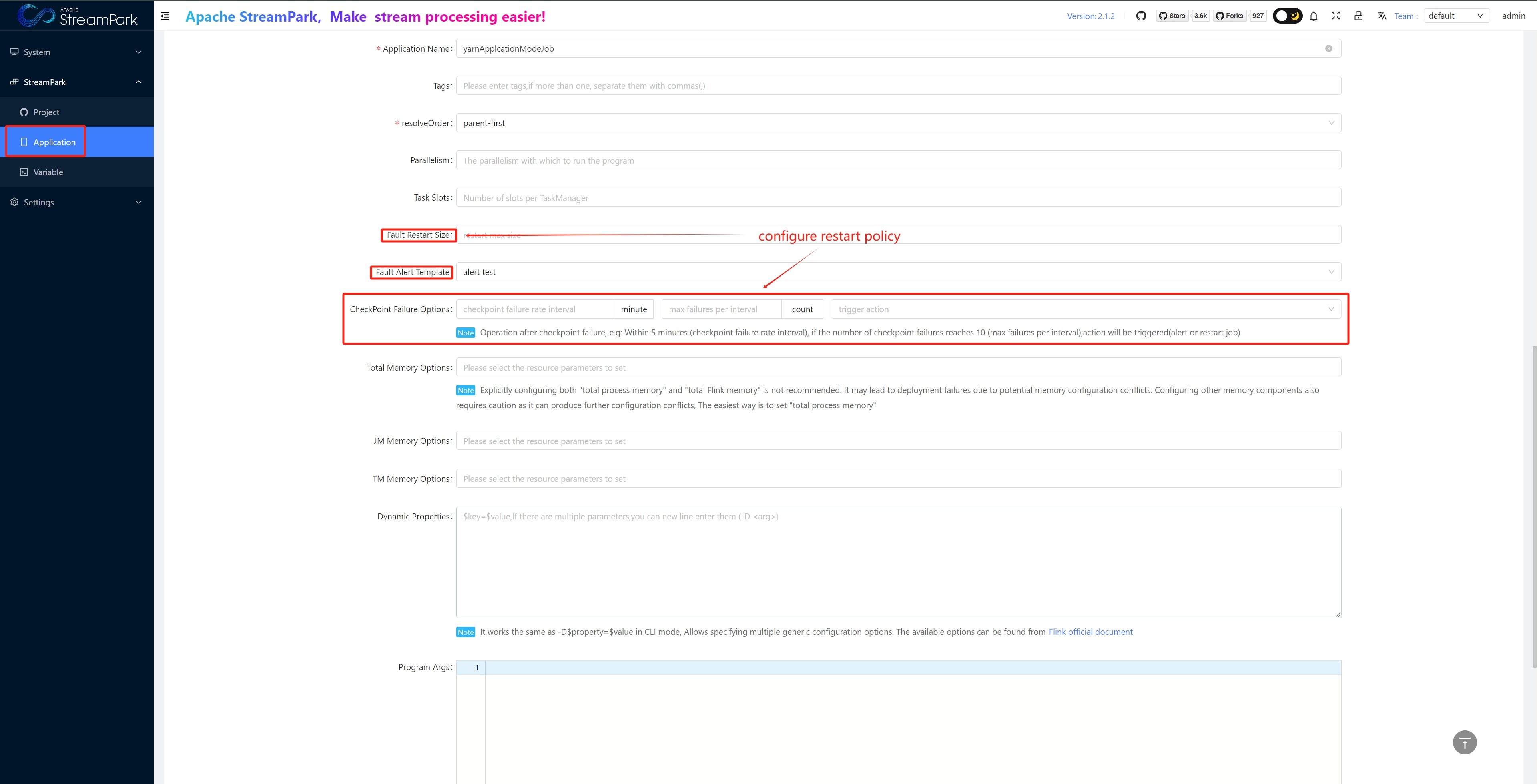
- When creating or modifying a job, configure in "Fault Alert Template" and “CheckPoint Failure Options”
cp/sp
【To be improved】
Native Flink Checkpoint and Savepoint
cp: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/checkpointing/ sp: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/ops/state/savepoints/

How to Configure Savepoint in Apache StreamPark™
Users can set a savepoint when stopping a job
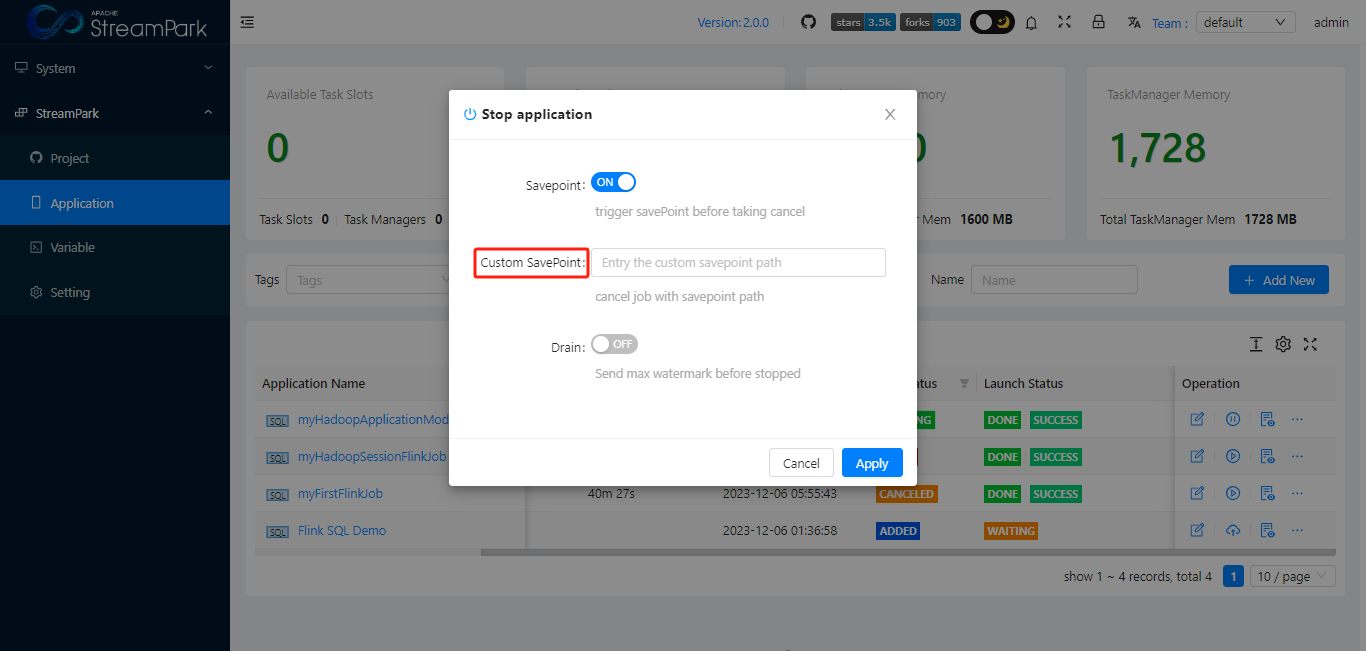
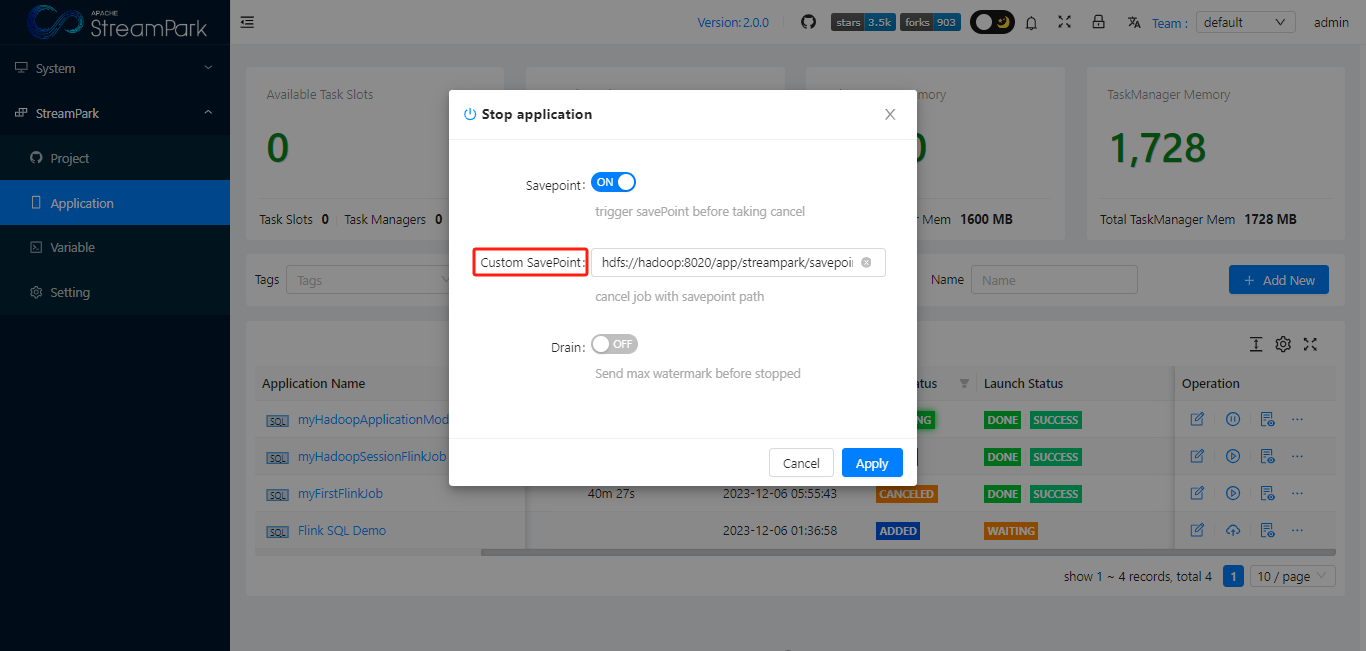

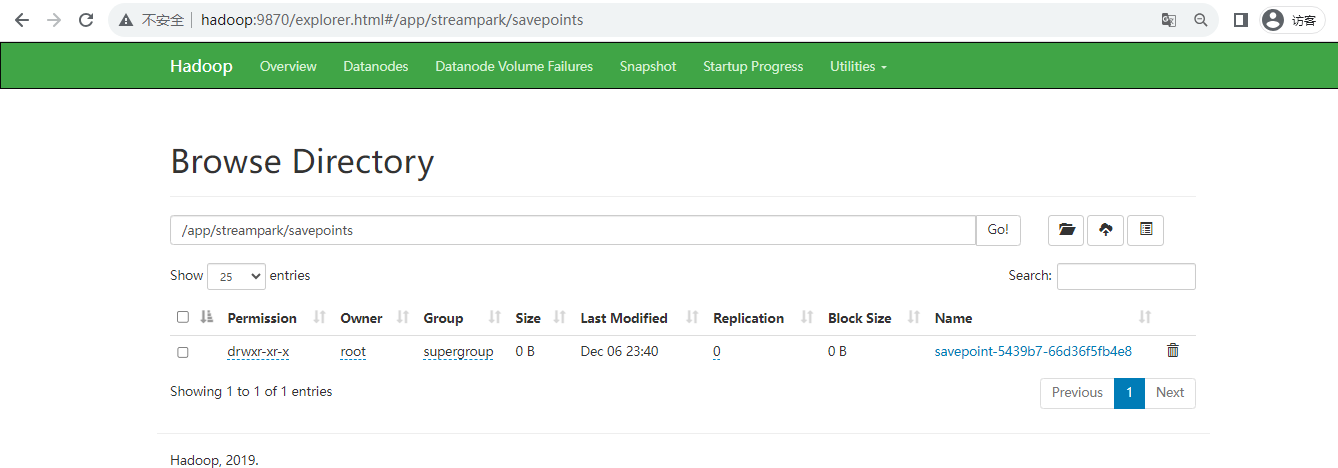
View savepoint

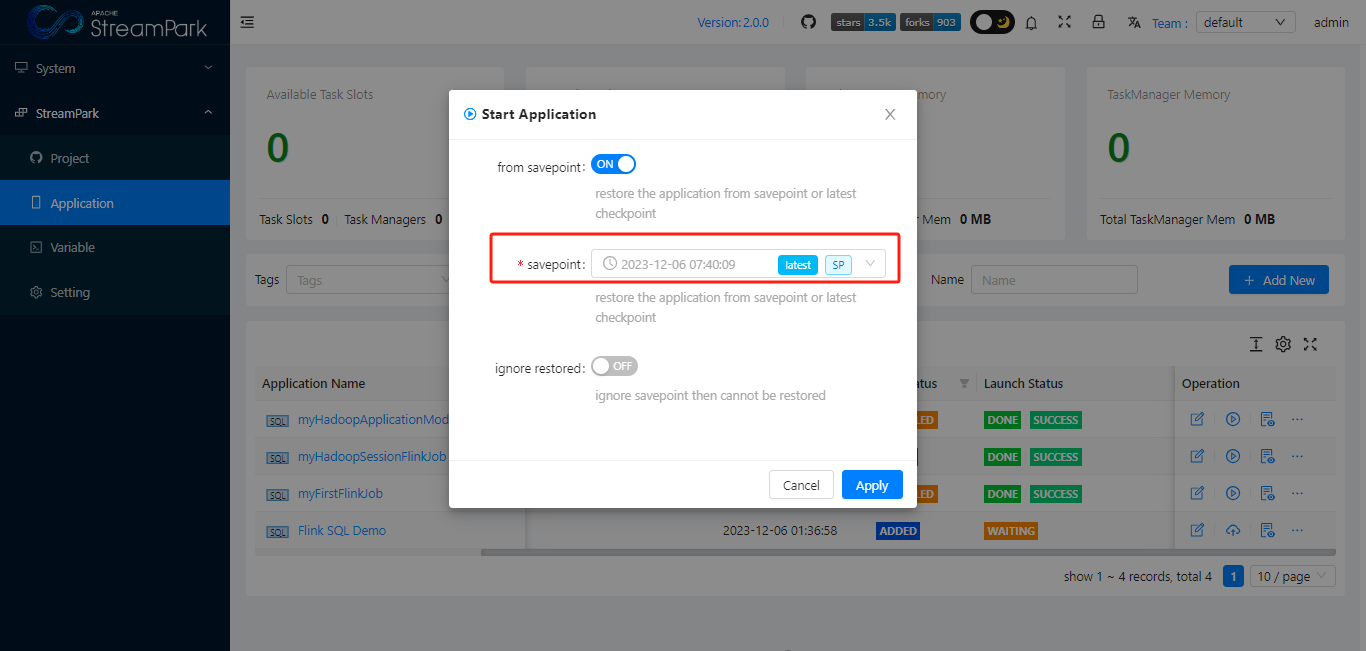
How to Restore a Job from a Specified Savepoint in Apache StreamPark™
Users have the option to choose during job startup
Job Status
【To be improved】
Native Flink Job Status
Job Status in Apache StreamPark™
【To be improved】
Job Details
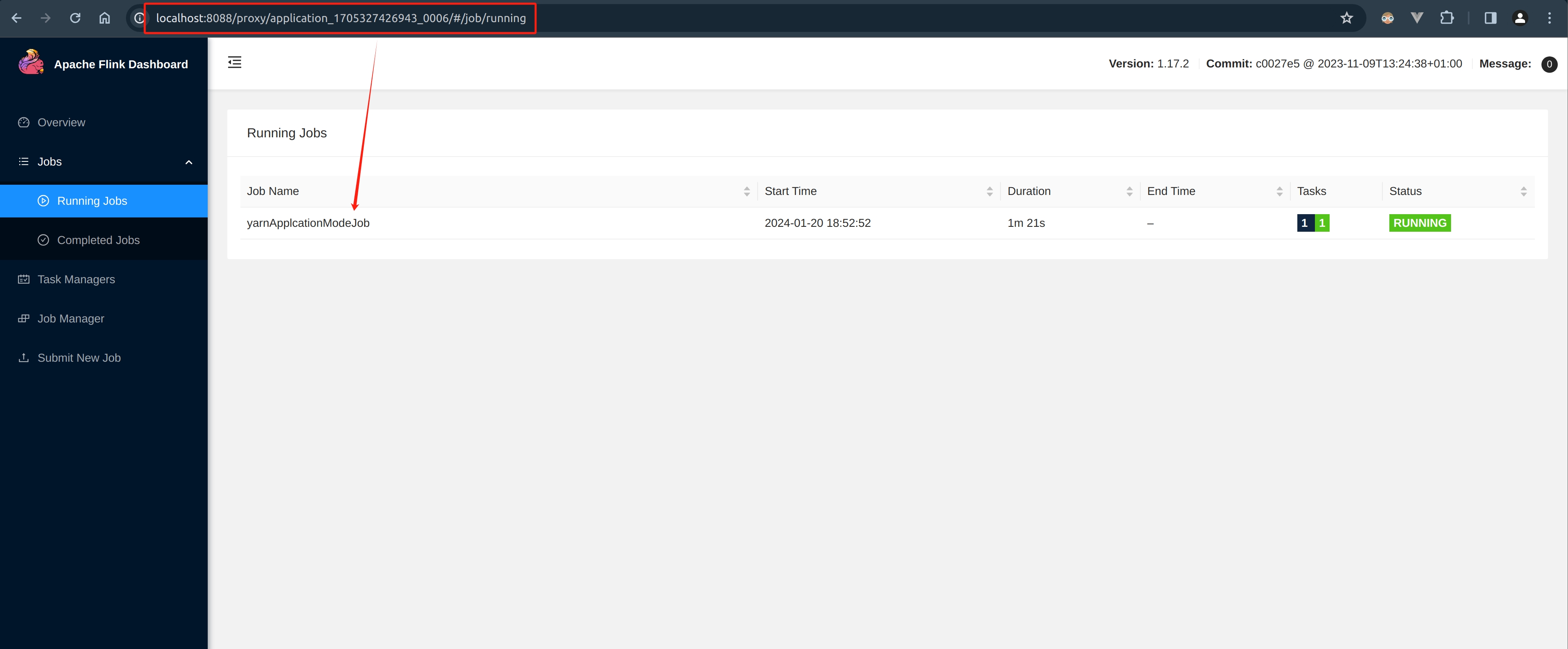
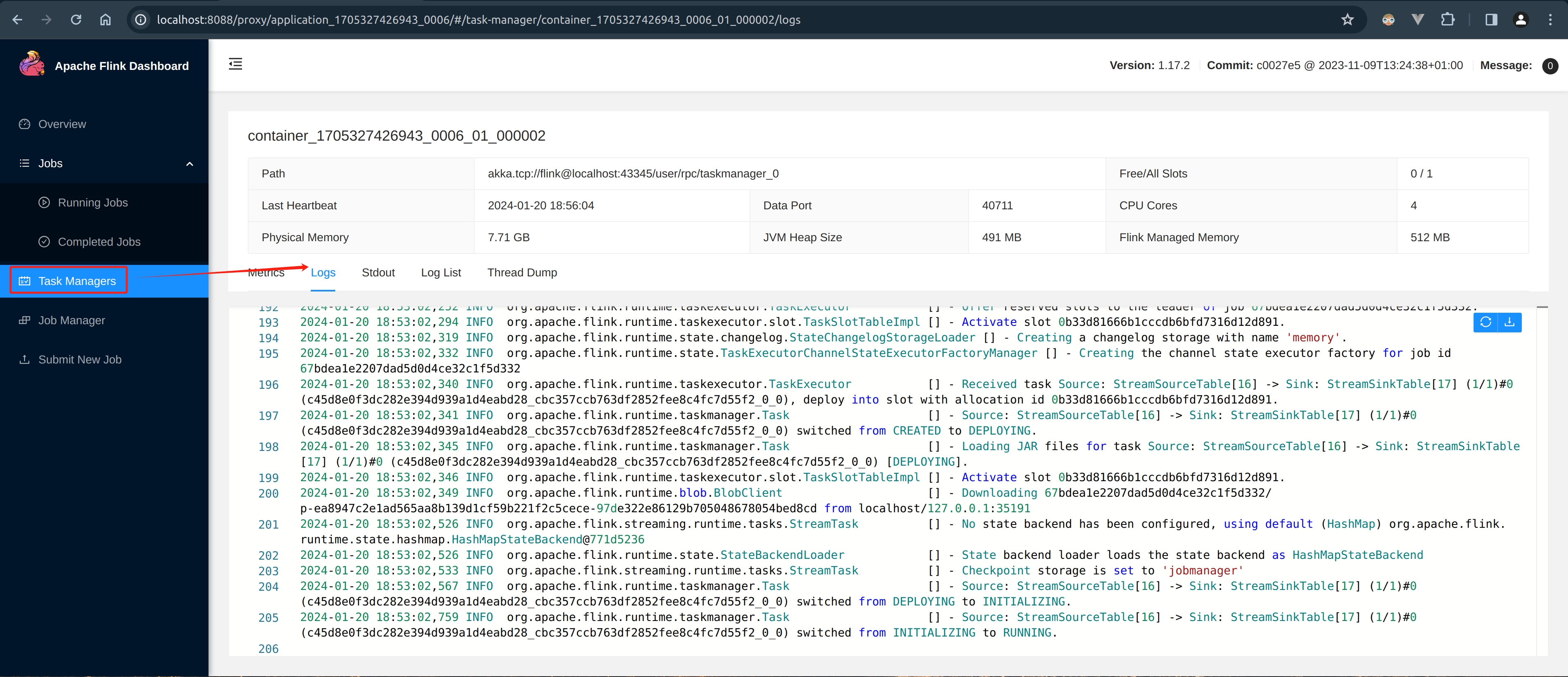
Native Flink Job Details
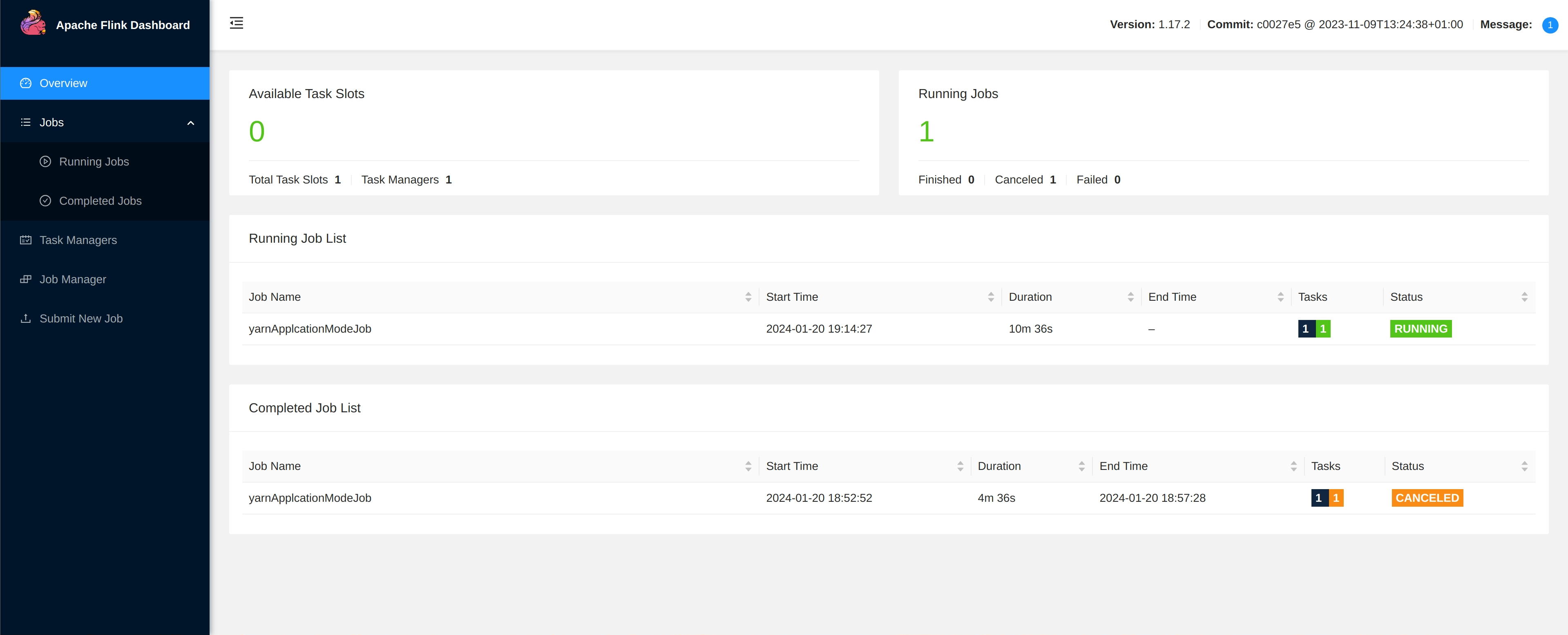
View through “Apache Flink® Dashboard”
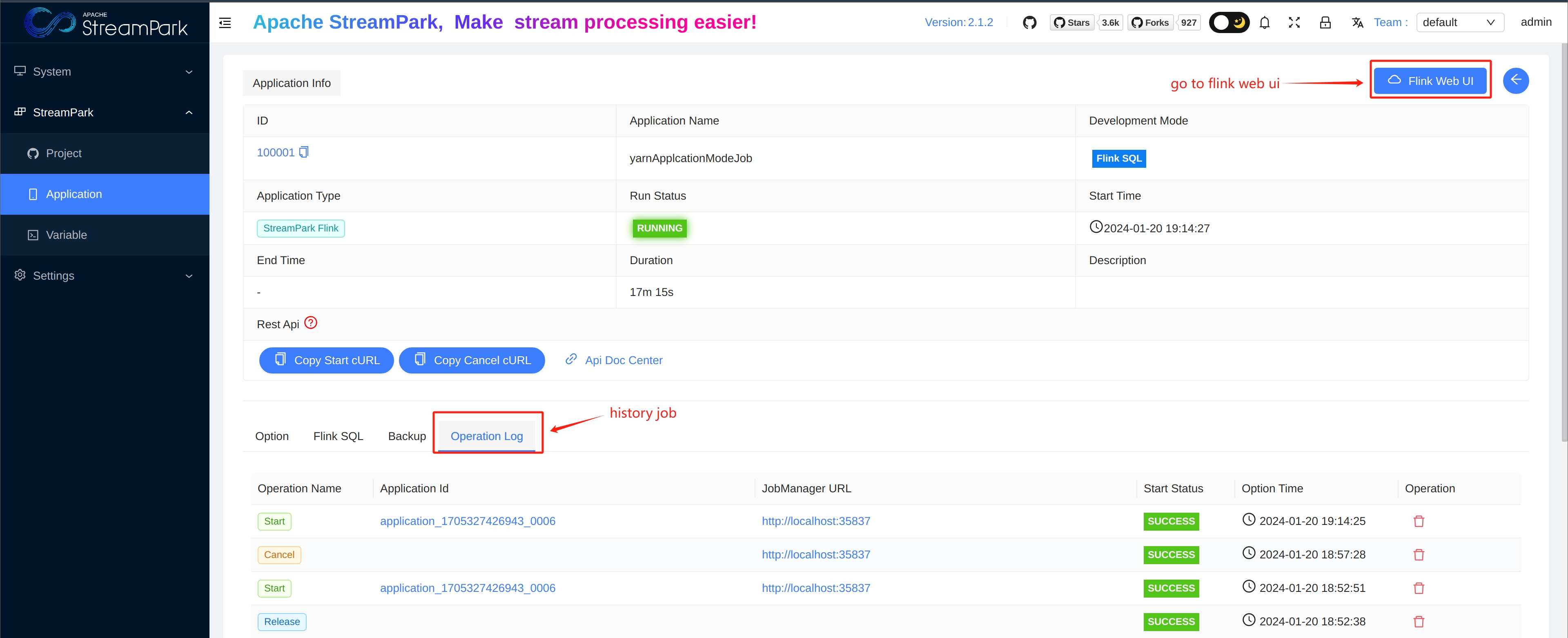
Job Details in Apache StreamPark™
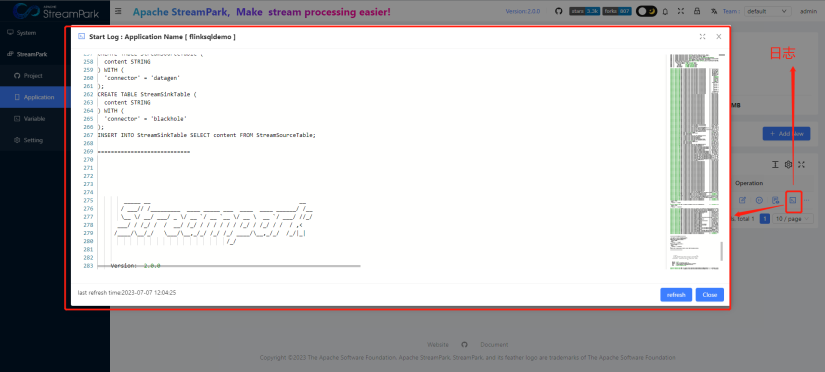
In addition, for jobs in k8s mode, StreamPark also supports real-time display of startup logs, as shown below
Integration with Third-Party Systems
How Native Flink Integrates with Third-Party Systems
Native Flink provides a REST API Reference: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/ops/rest_api/
How Apache StreamPark™ Integrates with Third-Party Systems
StreamPark also provides Restful APIs, supporting integration with other systems. For example, it offers REST API interfaces for starting and stopping jobs.